7. Agent
Agent 节点将工具的调用决策权交予 LLM,由其自主判断使用哪些工具及调用时机。它无需预先规划每一步骤,而是在推理过程中动态决策、按需调用工具,以完成复杂任务。
Agent 策略
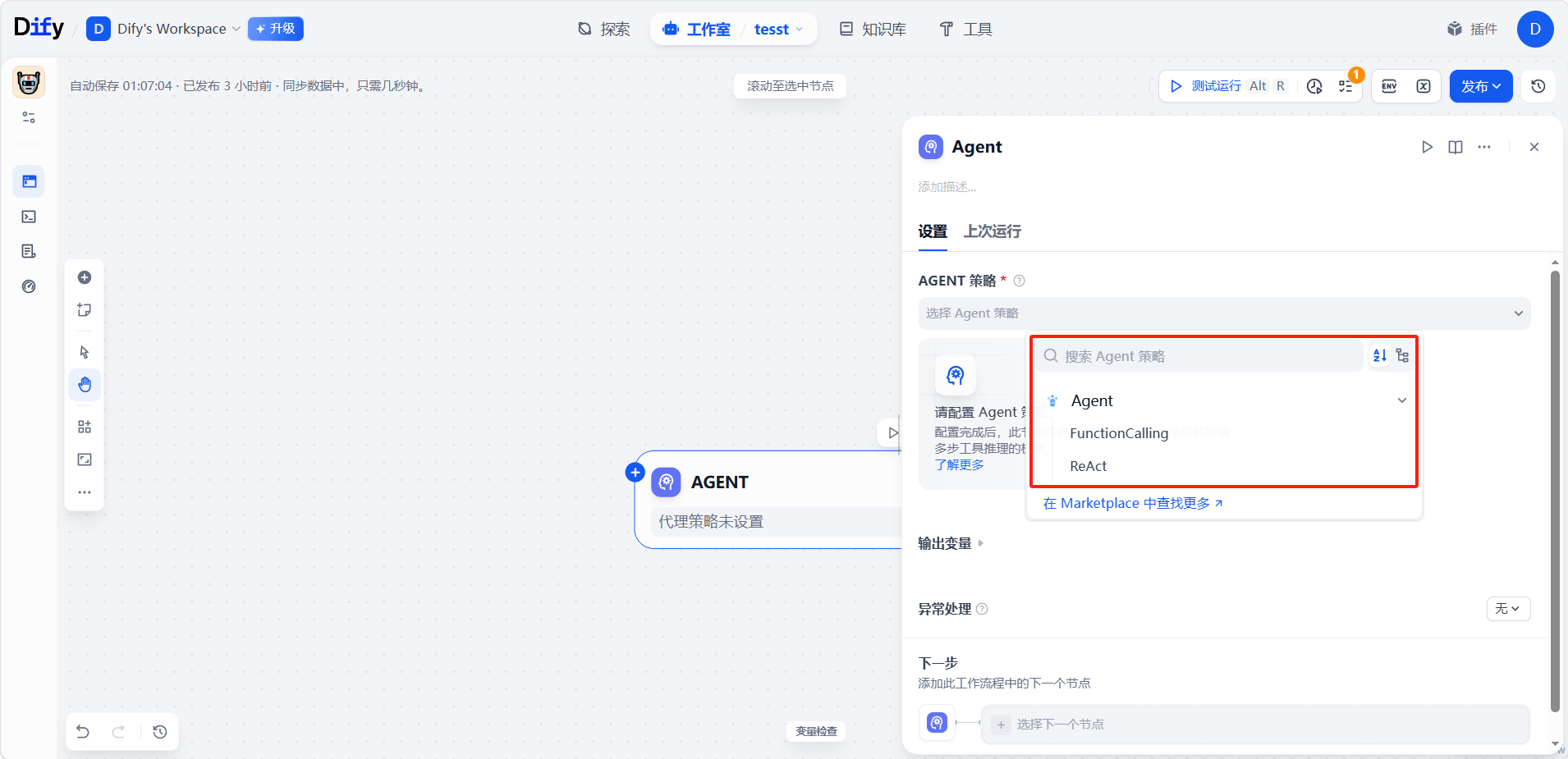
Agent 策略决定了 Agent 如何思考和行动。需根据所用模型的能力和任务需求,选一种最合适的策略。
- Function Calling(函数调用):直接借助 LLM 自带的函数调用能力,通过 tools 参数把工具定义传给模型,由模型用其内置机制决定何时、如何调用工具。适合 GPT-4、Claude 3.5 等函数调用能力较强的模型。
- ReAct(推理 + 行动):用结构化的提示词引导模型按「思考 > 行动 > 观察」的循环显式推理,决策过程清晰可见。适合不具备原生函数调用能力的模型,或需要看到明确推理轨迹的场景。
安装 Agent 策略
点击「在 Marketplace 中查找更多」。
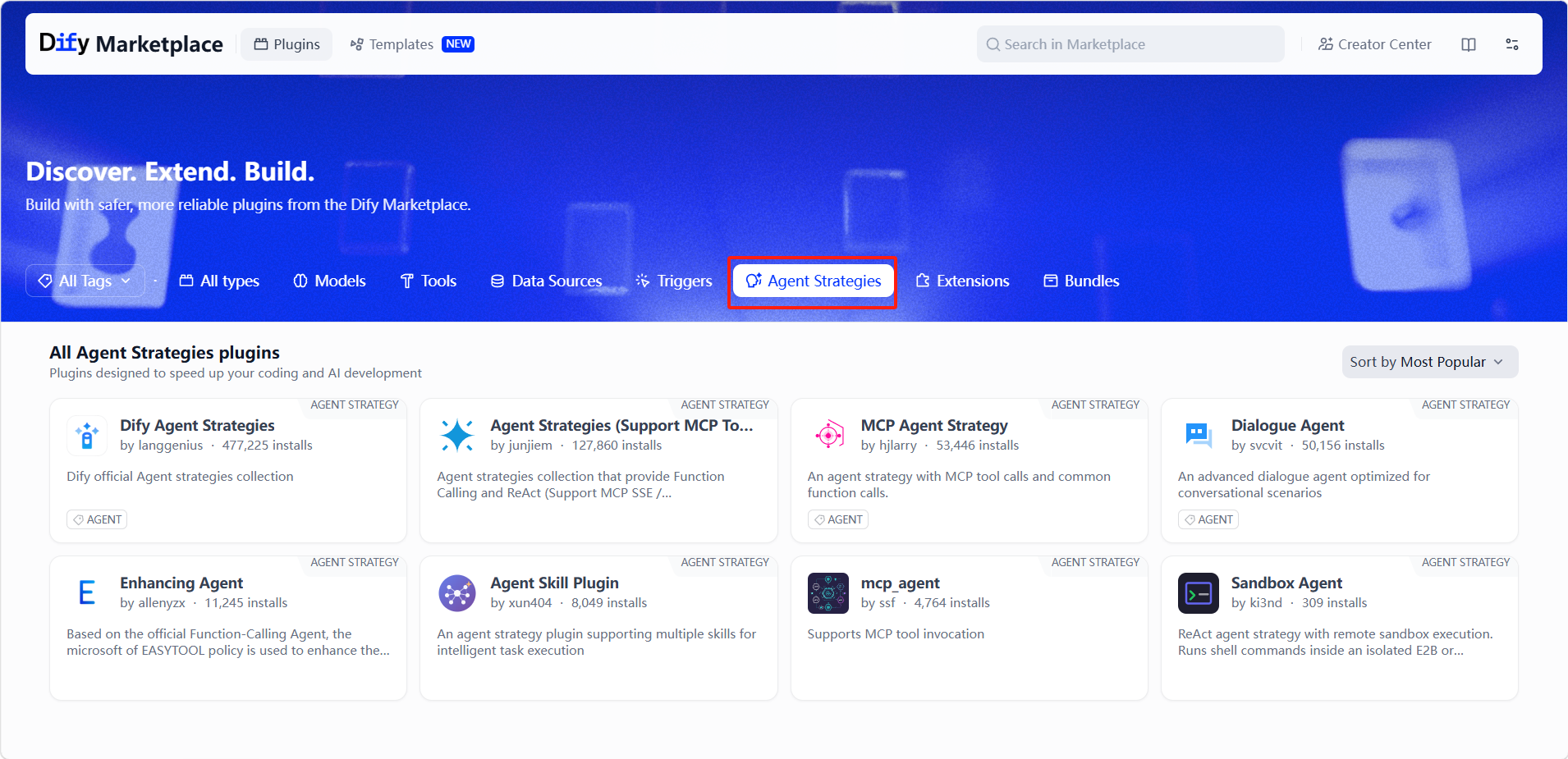
在弹出的页面中选择「Agent Strategies」,浏览并安装所需的策略。
配置
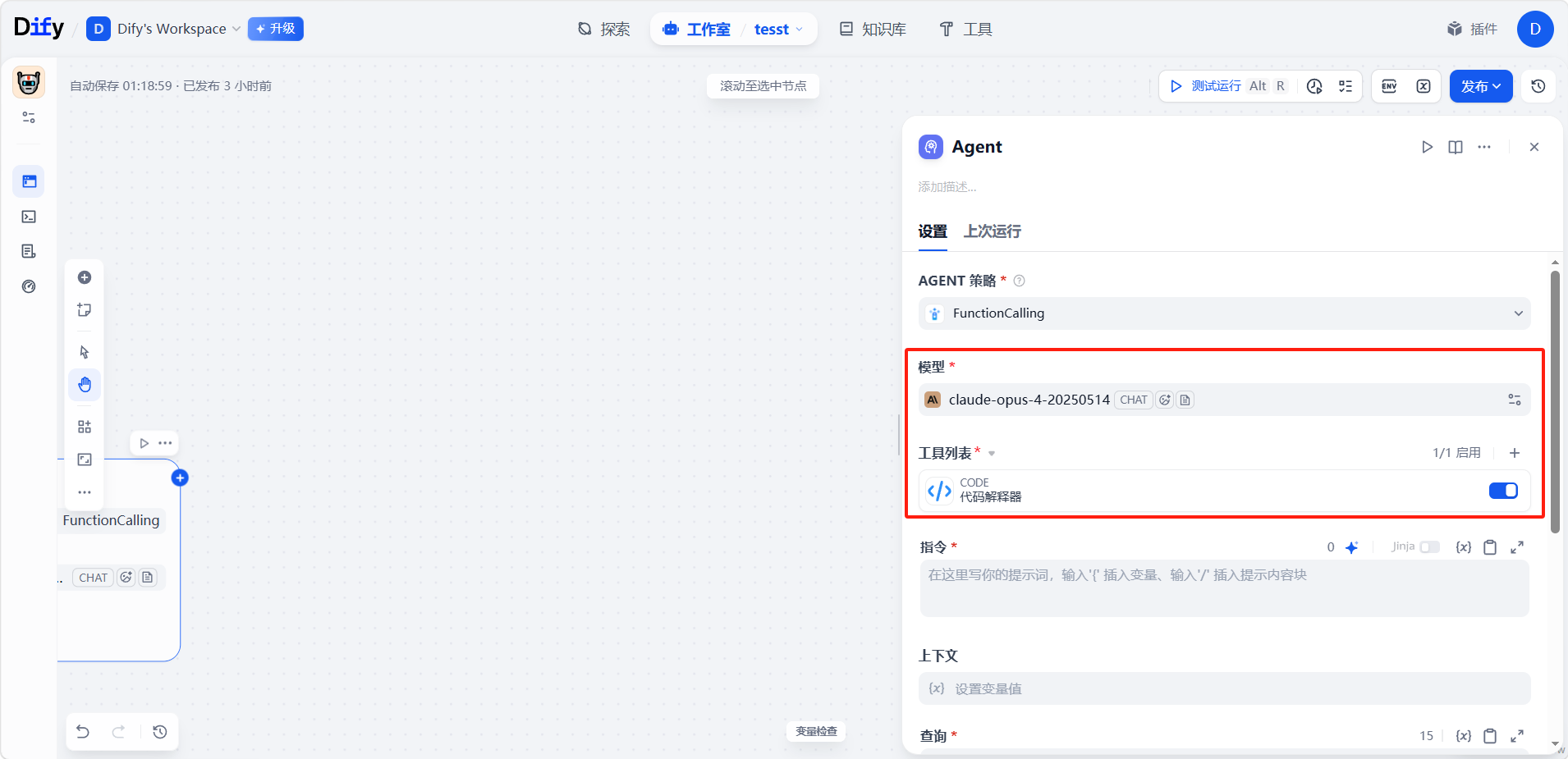
选择模型
配置好 Agent 策略后,选择一个支持该策略的 LLM。模型能力越强,越能胜任复杂推理,但每轮迭代的成本也相应越高。若采用 Function Calling 策略,须确认所选模型支持函数调用。
配置工具
设定 Agent 可调用的工具。每个工具需明确三项:
- 授权:访问外部服务所需的 API 密钥和凭据,在工作区中配置。
- 描述:清楚说明该工具做什么、何时该用——这是 Agent 判断要不要调用它的依据。
- 参数:工具接受的必填和选填输入,并设好相应的校验规则。
工具参数
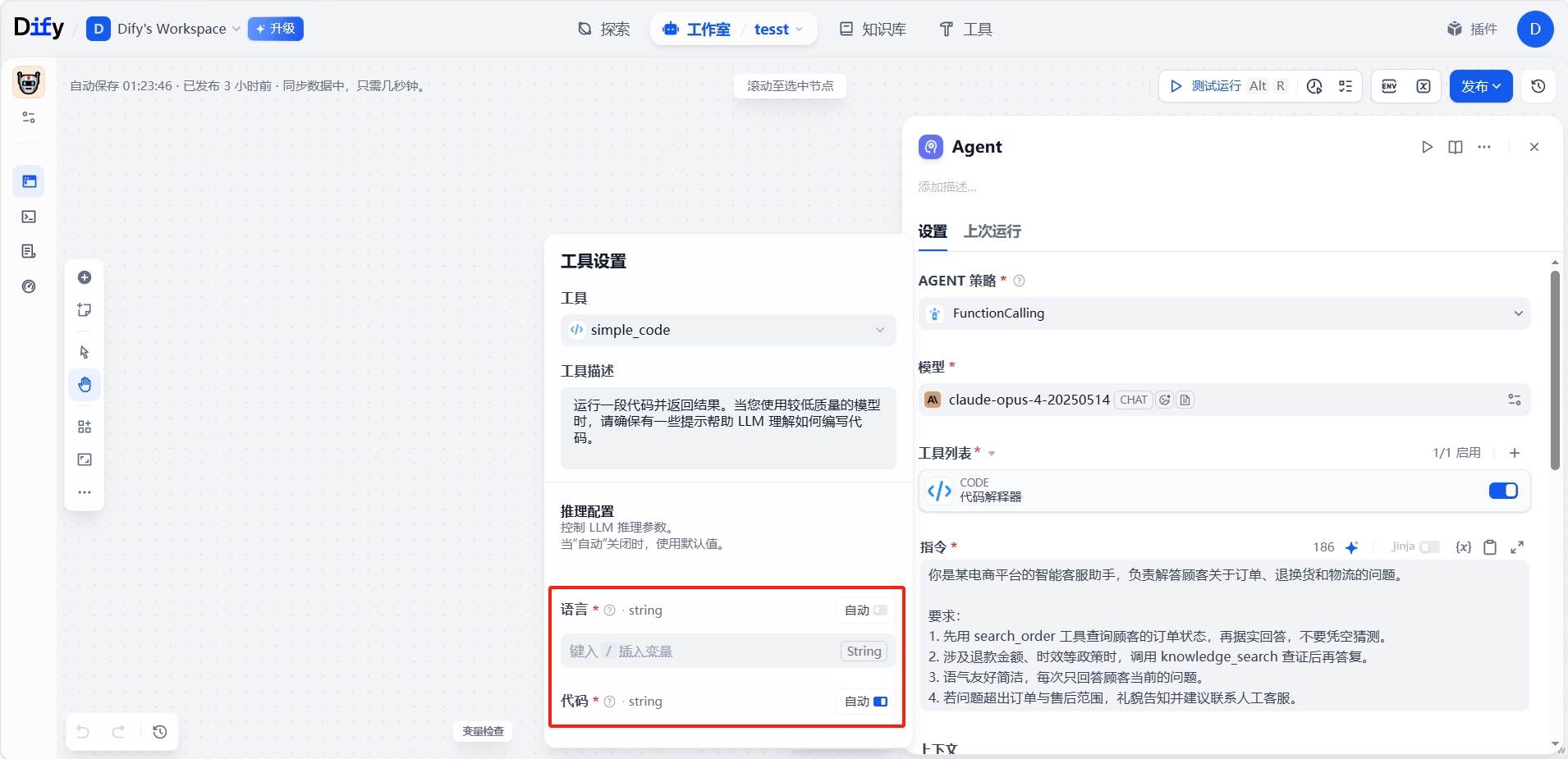
工具参数可设为自动生成或手动填写。自动生成的参数由 Agent 在运行时自行填入;手动填写的参数则需给定固定值,成为工具配置的固定部分。
指令与上下文
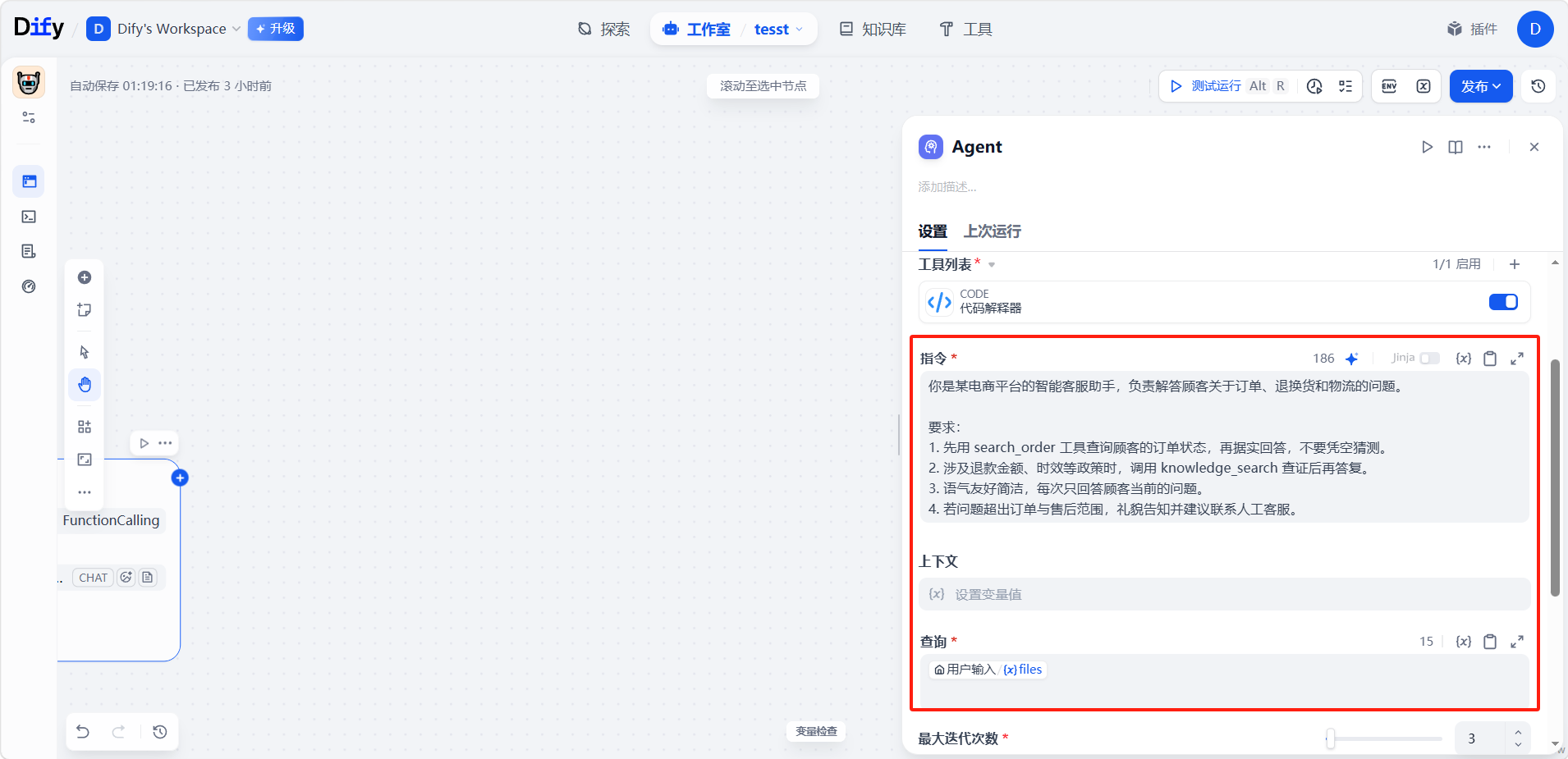
用自然语言定义 Agent 的角色、目标和背景信息。可用 Jinja2 语法引用上游节点的变量。其中查询指定 Agent 要处理的输入或任务,它可以是来自前序节点的动态内容。
执行控制
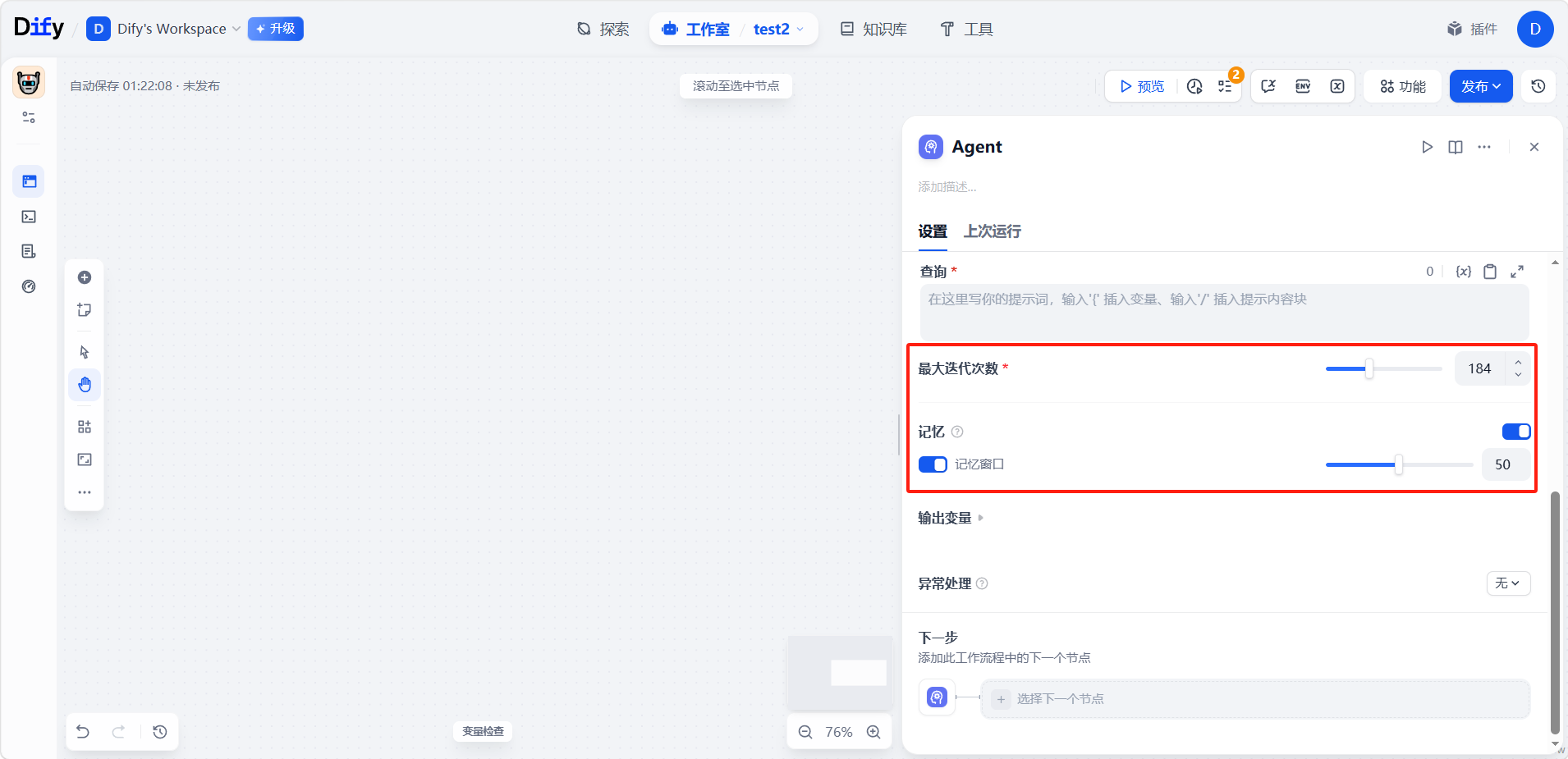
- 最大迭代次数:设定迭代次数的安全上限,防止 Agent 陷入无限循环。具体数值应按任务复杂度而定。
- 记忆:借助 TokenBufferMemory 控制 Agent 记住多少条历史消息。记忆窗口越大,可参考的上下文越多,但消耗的 token 也越多。它让对话得以延续,使得后续提问能引用先前的操作。
注意:记忆功能仅适用于 Chatflow(聊天流)。
输出变量
Agent 节点提供较为完整的输出,包括:
- 最终回答:Agent 对该任务给出的最终答复。
- 工具输出:执行过程中每次调用工具所返回的结果。
- 推理轨迹:逐步的决策过程(ReAct 策略下尤其详尽),可在 JSON 输出中查看。
- 迭代次数:本次共进行了多少轮推理。
- 成功状态:Agent 是否成功完成了任务。
- Agent 日志:带元数据的结构化日志事件,便于调试和监控工具调用。
适用场景
- 研究与分析:自主检索多个来源、综合信息,给出较全面的答复。
- 故障排查:需要边收集信息、边验证猜想,并根据发现随时调整方向的诊断类任务。
- 多步数据处理:下一步该做什么取决于中间结果的复杂流程。
- 动态 API 调用:API 的调用顺序取决于响应和条件、无法预先定死的场景。
实践建议
- 工具描述要清楚:帮助 Agent 准确判断每个工具该在何时、如何使用。
- 迭代上限要合理:既防止成本失控,又给复杂任务留出足够的腾挪空间。
- 指令要详尽:把 Agent 的角色、目标,以及各种约束或偏好交代清楚。
- 记忆要权衡:根据实际需求,在「保留足够上下文」和「节省 token」之间取得平衡。
评论
0 条