3. LLM
LLM 节点用于调用大语言模型来处理文本、图片和文档。它把提示词发给配置好的模型,再接收模型的回复,支持结构化输出、上下文管理和多模态输入。
安装模型
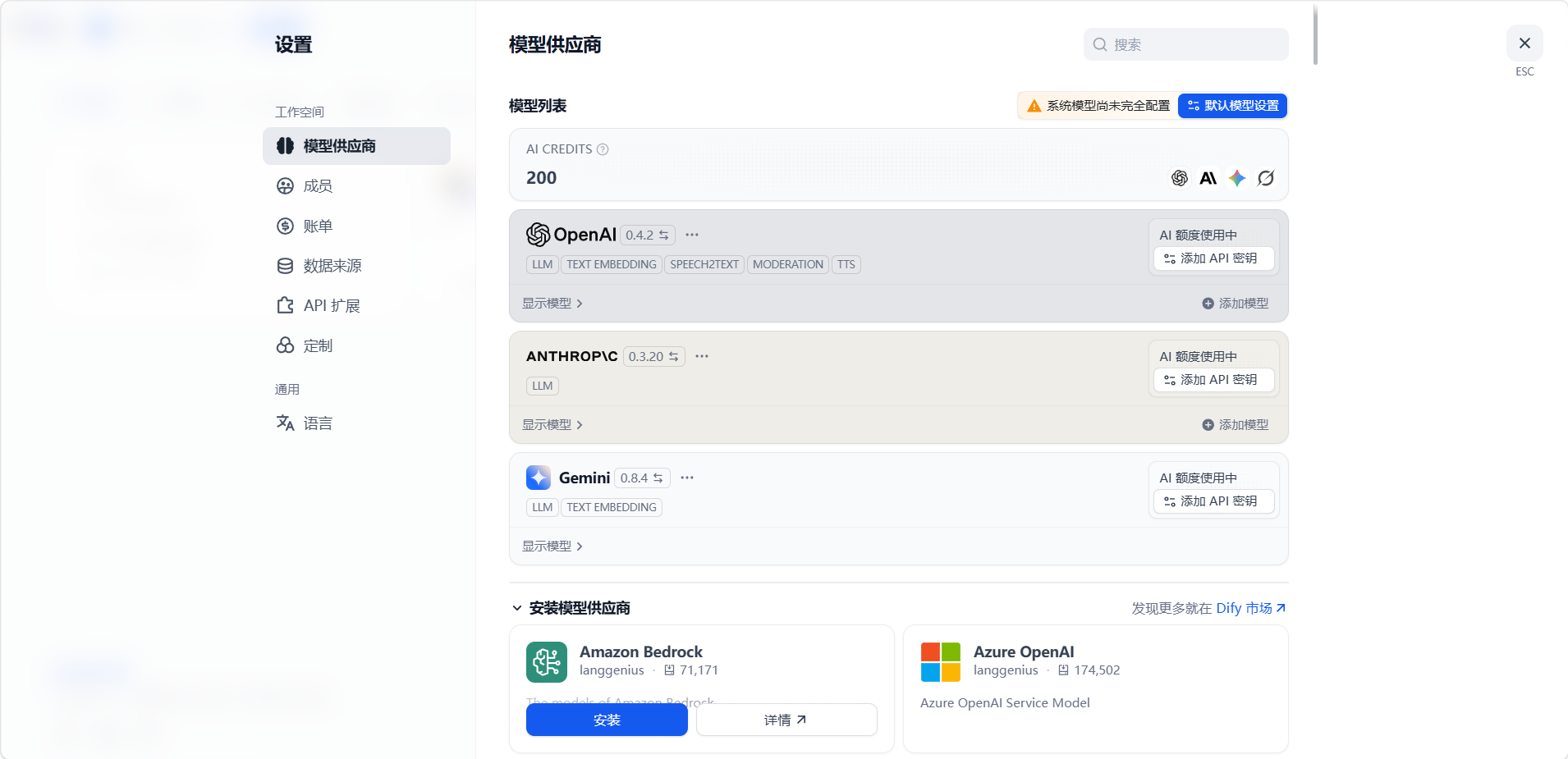
使用前,需先在「设置 > 模型供应商」里至少配置一个模型供应商。
配置提示词
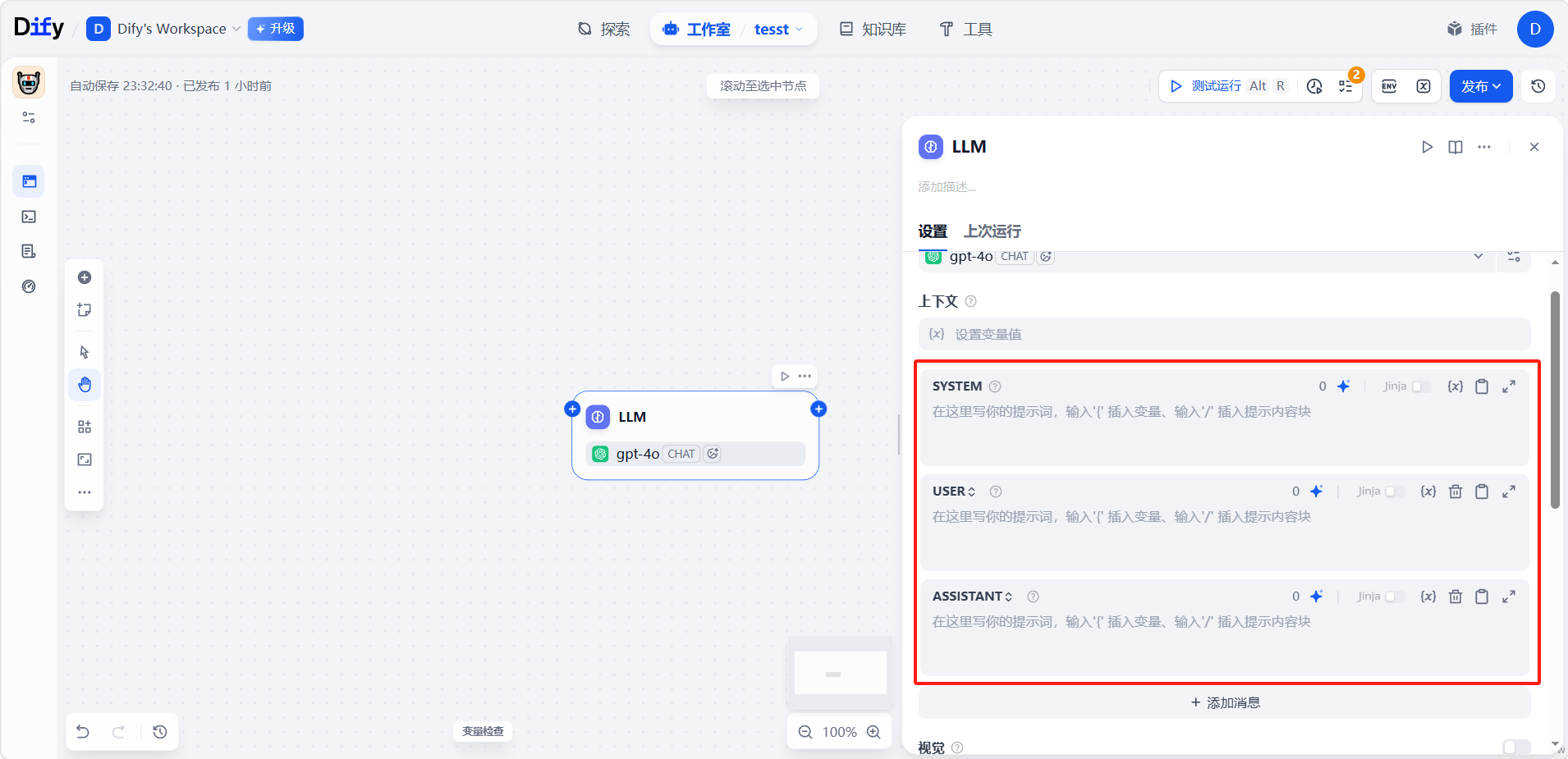
提示词的编写界面会随所选模型的类型而不同,模型分两类:
- 对话型(Chat):提示词按「角色」分段填写,每段代表对话中的一方——System 用来设定模型扮演什么角色、遵守哪些规则,User 放实际要问的内容,Assistant 用来给一两个示范回答(可选,借此让模型照着这个风格答)。目前主流模型多属此类。
- 补全型(Completion):没有角色之分,只给模型一段开头文本,让它顺着往下写。 这类模型较为传统,现在用得少。
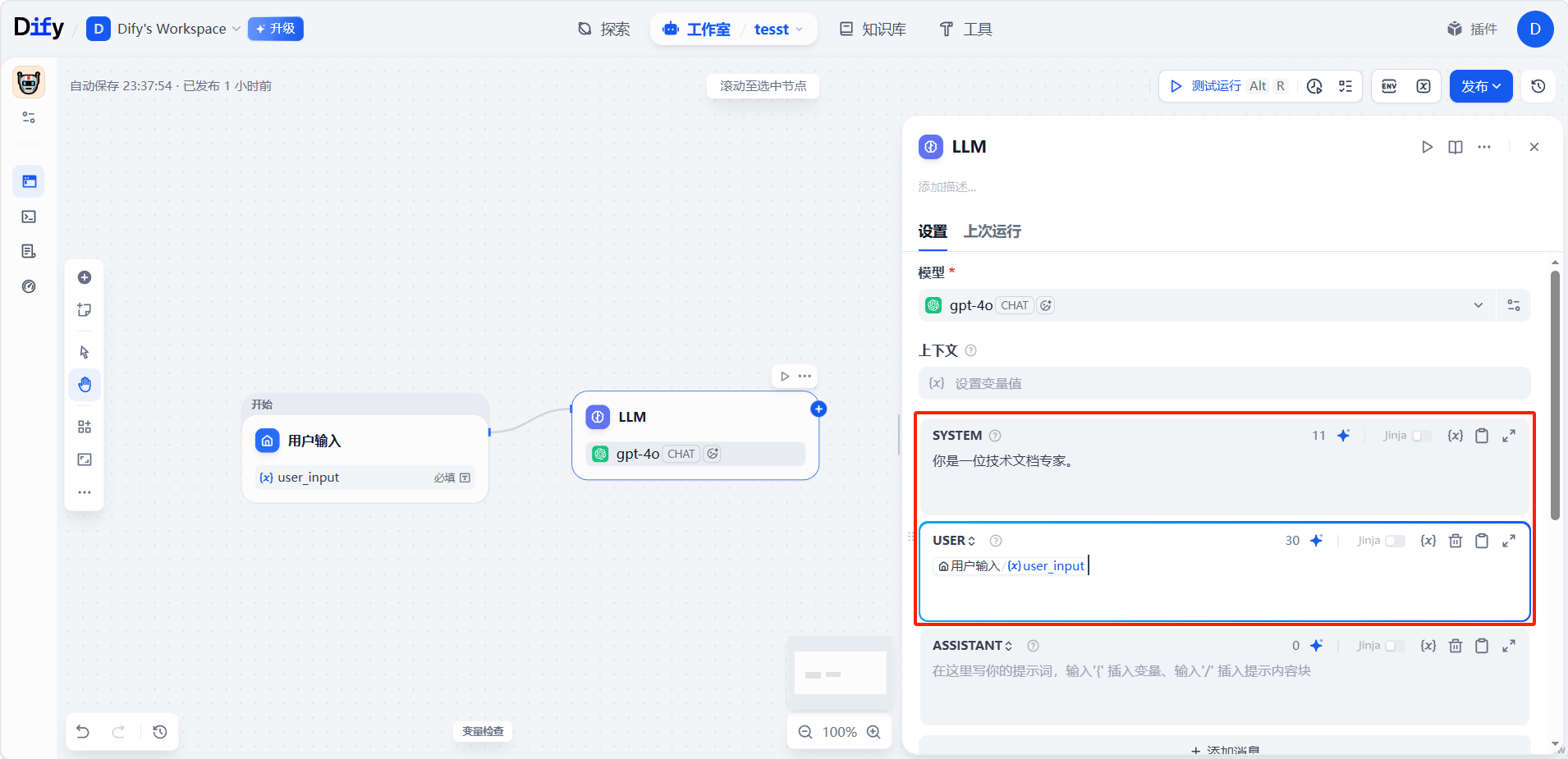
在提示词里引用工作流变量,用双花括号包住变量名:{{变量名}}。这些变量会在提示词送达模型之前,被替换成实际的值。例如:
上下文变量
上下文变量用于把外部知识喂给模型,同时记录这些知识的出处。这正是 RAG(检索增强生成)的核心思路——让模型依据指定的资料来回答,而不是仅凭自身训练记忆作答,从而减少胡编。
具体做法分两步:先把知识检索节点的输出连到 LLM 节点的「上下文」输入口,再在提示词里引用这份上下文。例如:
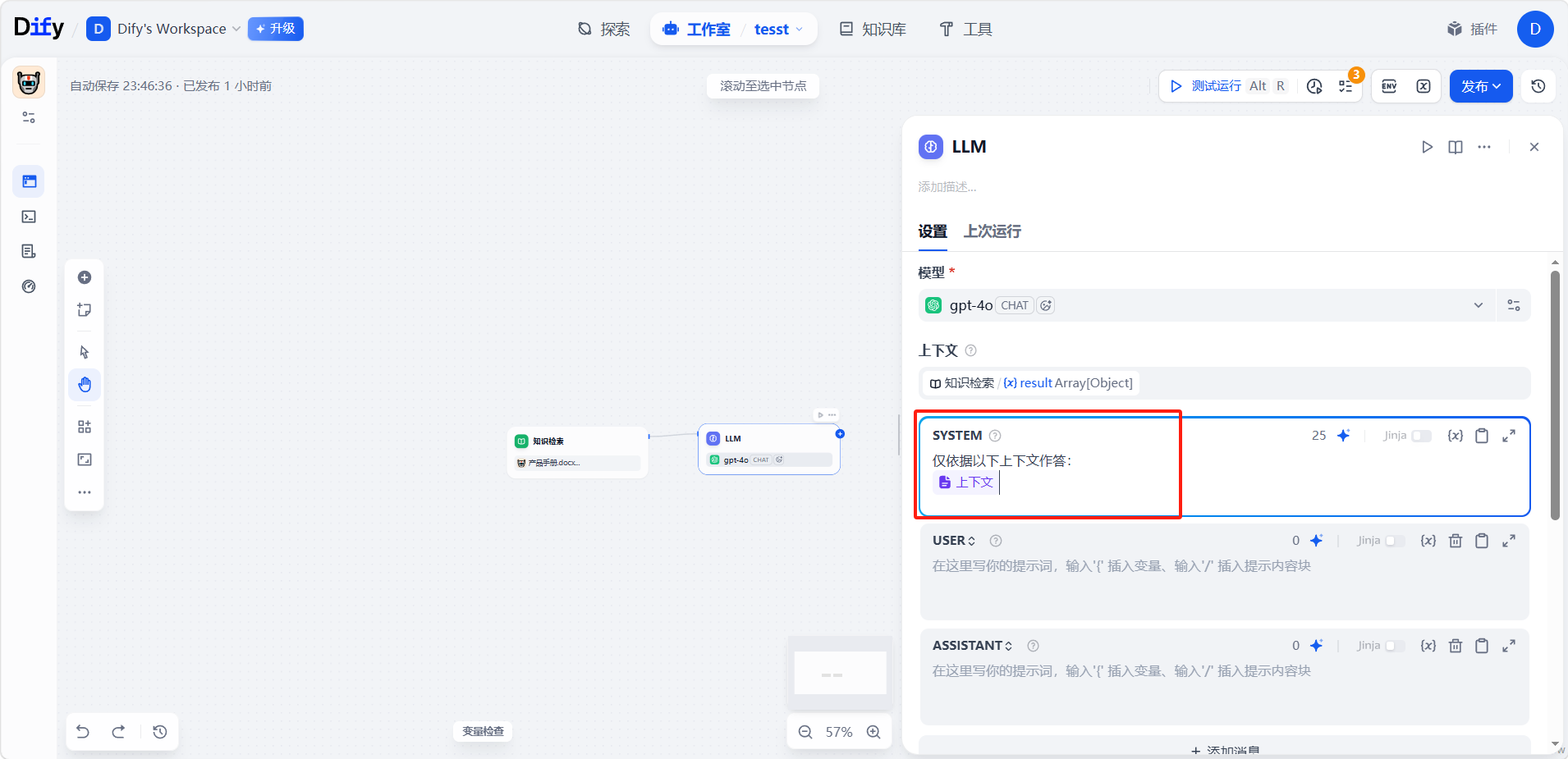
当上下文变量来自知识检索时,Dify 会自动记录引用出处,让访客看到信息的来源。
结构化输出
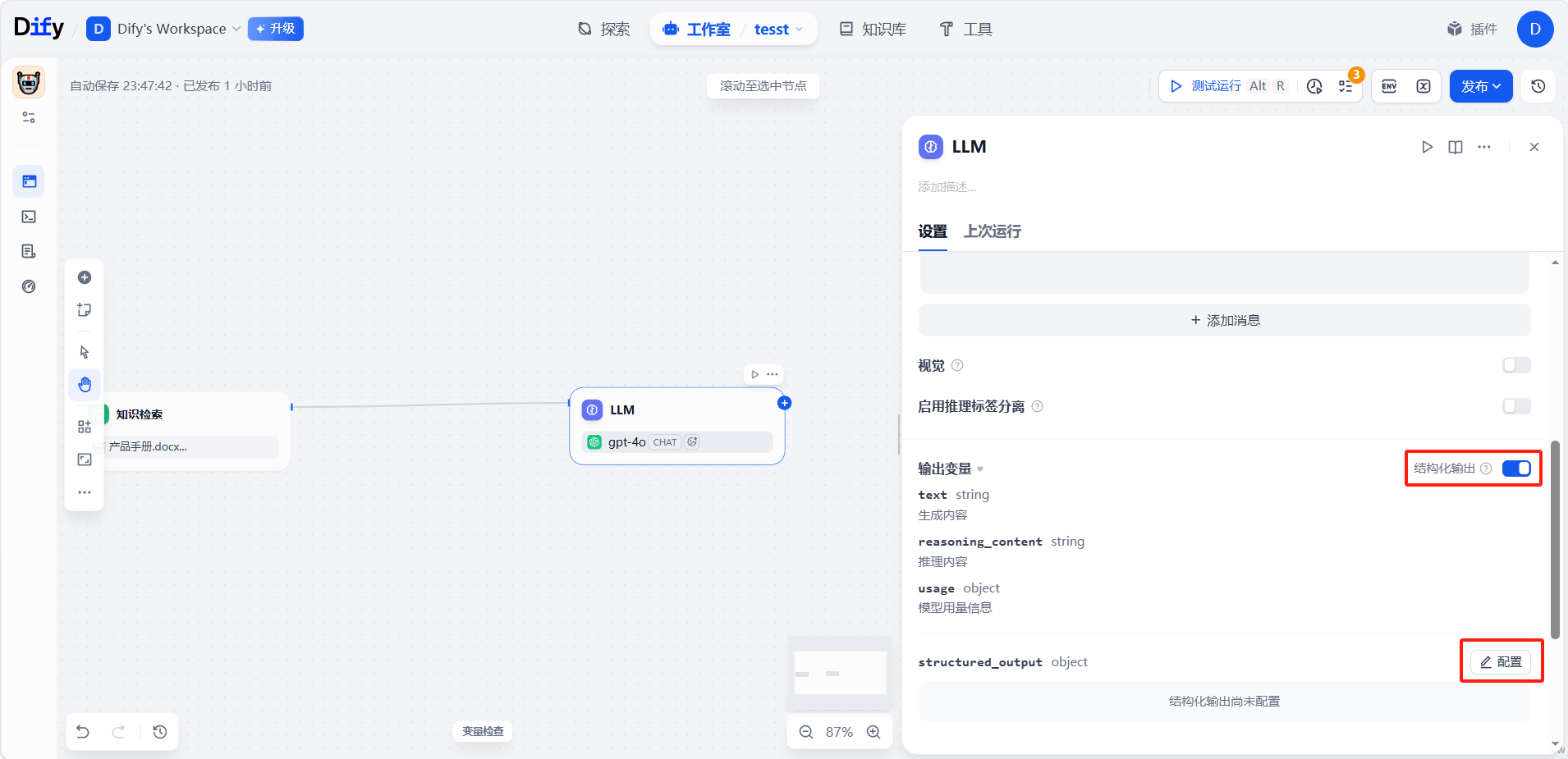
可强制模型按指定的数据格式(如 JSON)返回结果,便于程序进一步处理。有三种配置方式:
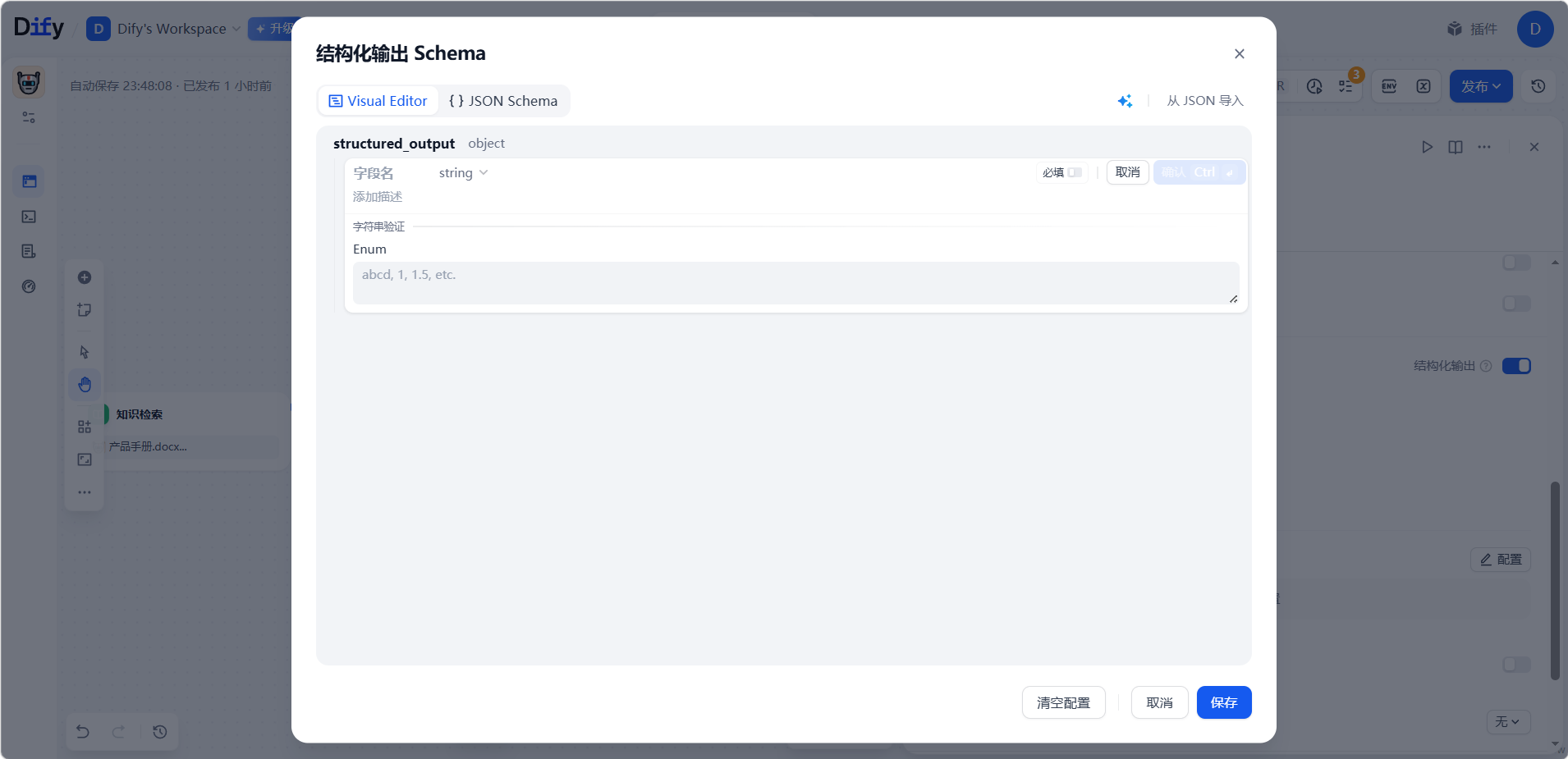
- 可视化编辑器:适合简单结构。逐个添加字段,设好名称和类型、标记哪些必填、补上说明,编辑器会自动生成对应的 JSON Schema。
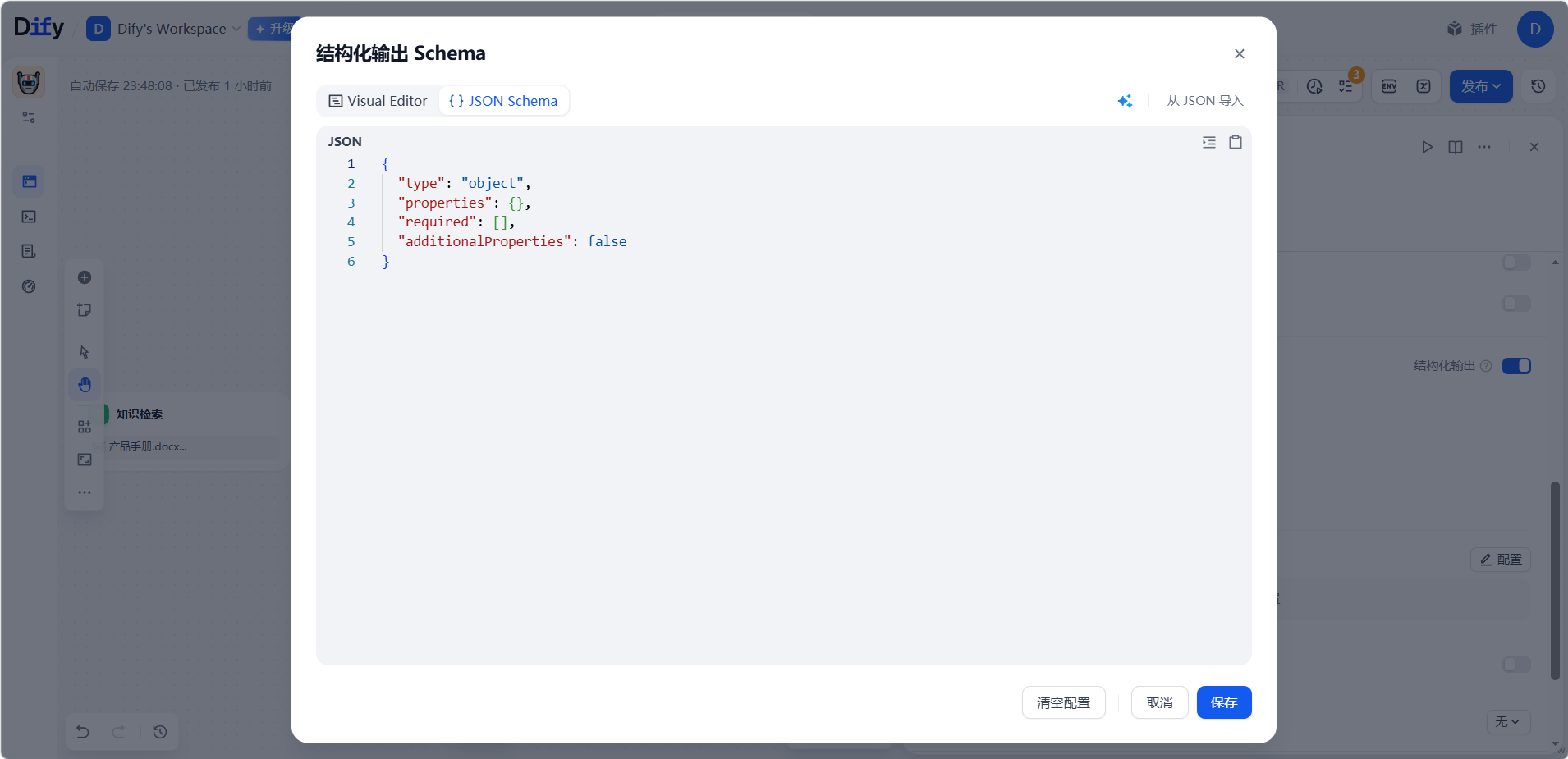
- JSON Schema:适合带嵌套对象、数组和校验规则的复杂结构,直接手写 schema。例如:
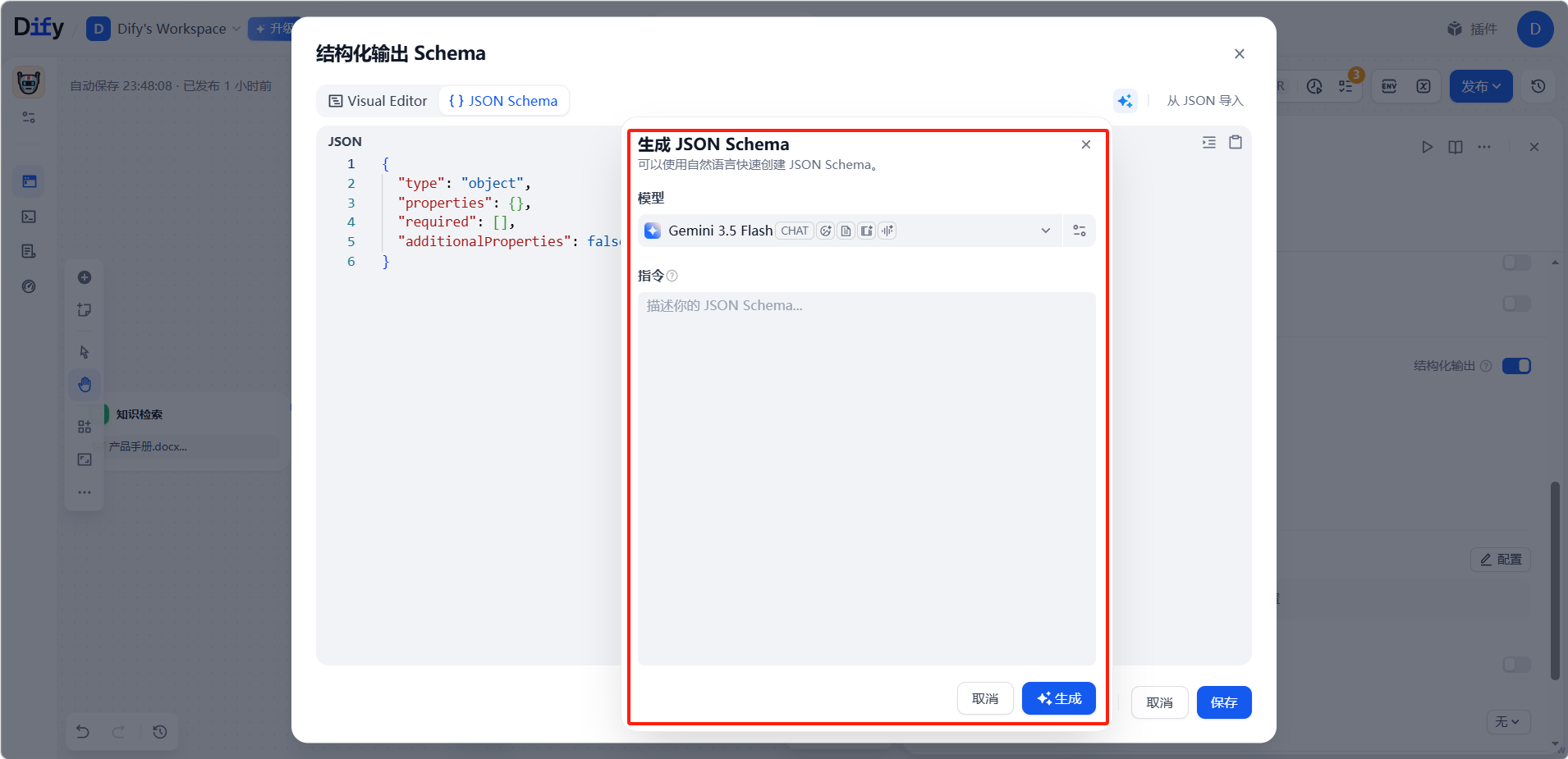
- AI 生成:用自然语言描述需求,让 AI 生成 schema。
需要注意的是,原生支持 JSON 的模型,结构化输出更稳定可靠;对不支持的模型,Dify 会把 schema 塞进提示词里引导,但结果未必每次都如预期。
记忆与文件处理
记忆(Memory)让同一段聊天流对话里的多次 LLM 调用能延续上下文——此前的来回问答会以「用户—助手」的格式自动拼进后续的提示词,模型因此记得前面聊过什么。可通过编辑 USER 模板,定制其中哪些内容进入用户提示词。记忆仅作用于当前节点,且不跨对话保留:换一段新对话,记忆便重新开始。
注意:记忆功能只有在 Chatflow(聊天流)中可用。
文件处理方面,把文件变量加进提示词即可供多模态模型使用。不同模型处理能力不同:GPT-4V 能看图,Claude 可直接读 PDF,其余模型可能需要先做预处理。
视觉(Vision)配置
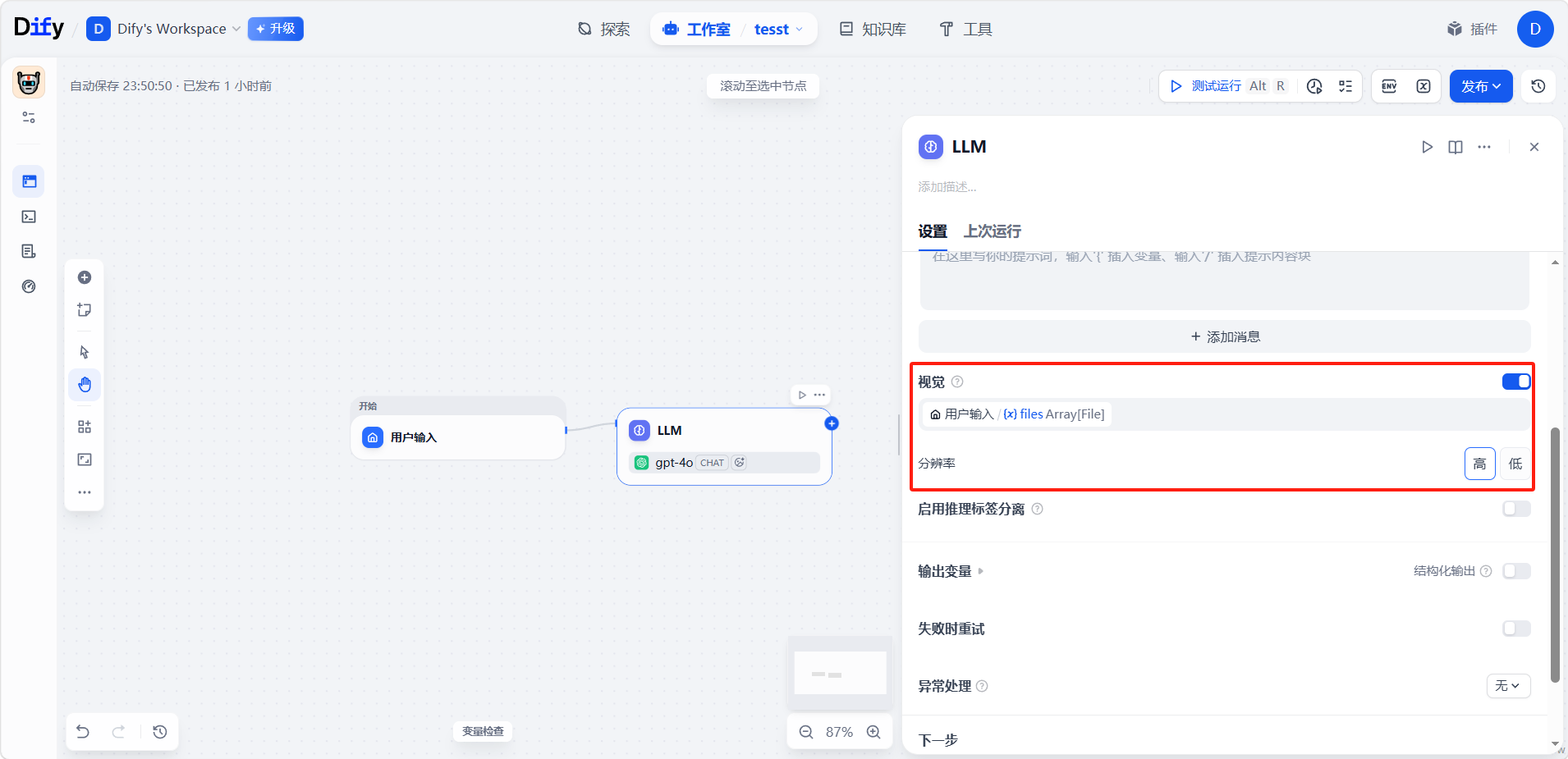
处理图片时,可控制识别的精细程度:
- 高精度:对复杂图片识别更准,但消耗更多 token。
- 低精度:处理更快、token 更省,适合简单图片。
视觉输入默认的变量选择器是 userinput.files,它会自动取用用户输入节点上传的文件。
Jinja2 模板支持
提示词支持 Jinja2 模板,让提示词能按数据动态拼装。普通模式下,{{变量名}} 只能整块替换成对应的值;切到 Jinja2 模式后,则可以在提示词里写循环(把列表逐条展开)、条件判断(分情况输出不同内容)和数据变换等逻辑,自动生成成段内容。
例如,知识检索召回的结果数量时多时少。普通模式下只能把整批结果整块塞进去,挤成一团、无法逐条编号:
切到 Jinja2 模式,用一段循环就能让它们自动逐条编号、各占一行:
召回几条就生成几行,无需提前写死。模型最终收到的提示词如下:
流式输出
LLM 节点默认开启流式输出,文本会一块块实时吐出,从而边生成边展示。图片、文档等文件类输出,会在流式过程中自动处理并保存。
错误处理
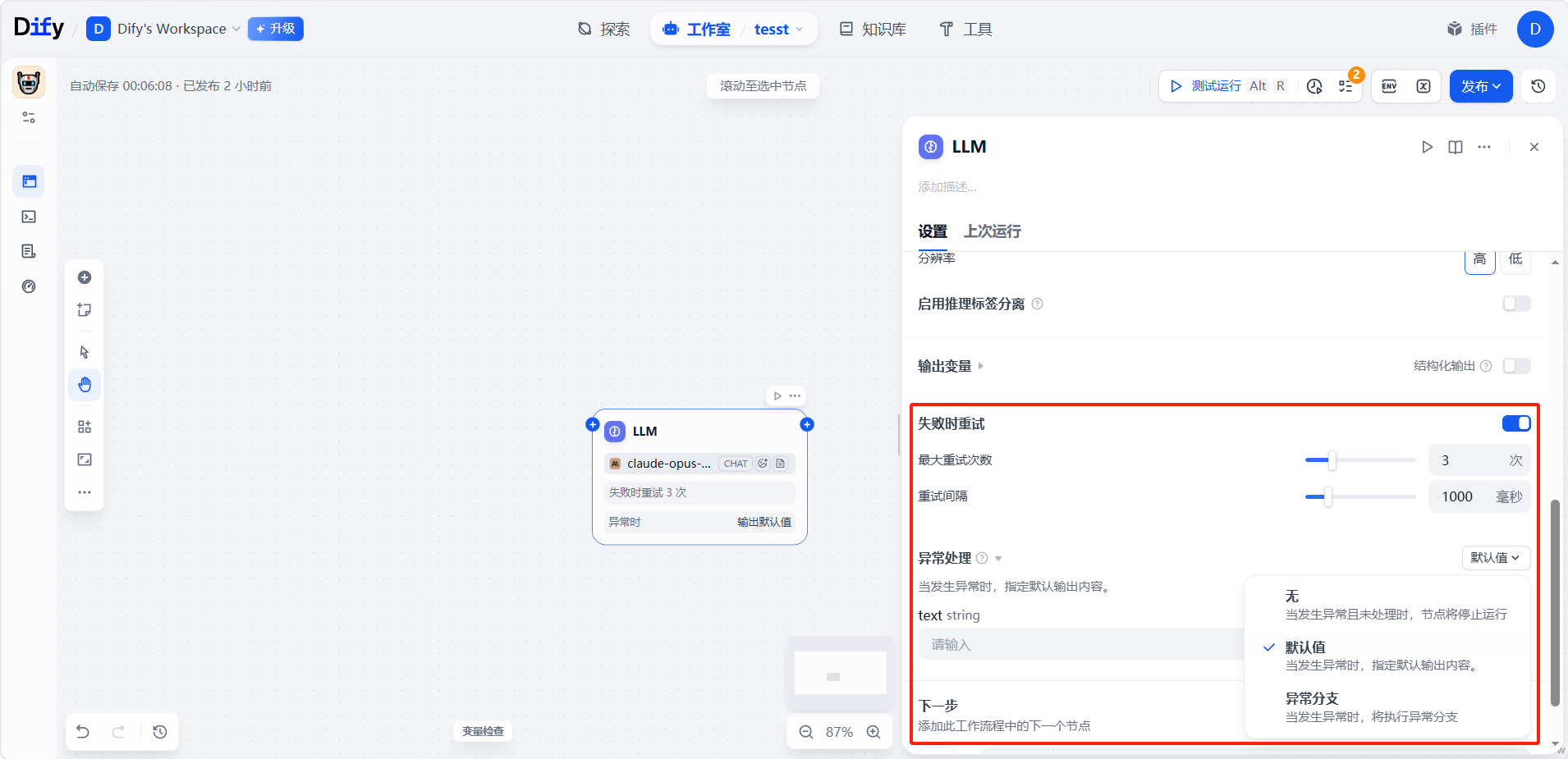
当一次 LLM 调用失败时(比如模型超时、服务暂时不可用),节点可以自动重试,相关策略包括:
- 最大重试次数:最多再试几次,仍失败才算彻底失败。
- 重试间隔:每次重试之间等多久再发起。
- 退避倍数:让间隔逐次拉长的倍率。比如设为 2,间隔就按 1 秒、2 秒、4 秒递增——避免在服务繁忙时短时间内反复猛敲,给对方喘息的余地。
若重试到上限仍未成功,可再设一道兜底方案,决定接下来怎么办:返回一个预设的默认值、把流程导向专门的错误分支去处理,或自动改用另一个备选模型重试。
评论
0 条