8. 深度研究(Deep Research)
Deep Research 是 ChatGPT 提供的自主研究功能。与普通对话不同,它会模拟人类研究员的工作方式:自主规划研究路径、浏览大量网页、交叉验证信息,最终生成一份带引用来源的完整研究报告。
一次深度研究通常需要 5–30 分钟,期间 ChatGPT 可能会浏览数十甚至上百个网页。研究过程中支持实时跟踪进度,并可随时中断或调整研究方向与可访问的数据源。
工作流程
Deep Research 的标准工作流程如下:
- 描述需要达成的研究目标
- 选择 Deep Research 可使用的数据源(公开网页、上传文件、连接的应用)
- ChatGPT 生成一份研究计划,用户可在研究启动前审阅并修改
- 研究过程中可实时跟进进度,并可随时中断以调整研究重点或数据源
- 研究完成后输出一份结构化报告,附带引用与来源链接,便于核实信息
Deep Research 默认由最新模型驱动;如有需要,用户也可选择旧版模型执行研究任务。
与普通搜索的区别
使用限制
Deep Research 的使用额度因订阅计划而异。具体规则如下:
- 额度查询: ChatGPT 产品界面内会显示剩余的 Deep Research 任务数计数器,建议以产品内显示为准
- 重置周期: 对于具有固定月度额度的计划,额度自首次使用日起每 30 天重置一次(非自然月重置)
- 地区可用性: Deep Research 的可用性取决于订阅计划及所在国家/地区
- 企业管控: Enterprise 与 Edu 工作区的管理员可通过基于角色的访问控制(RBAC)管理 Deep Research 的访问权限。
开启方式
Deep Research 提供两种触发方式:
- 在 ChatGPT 输入框中直接键入
/Deepresearch命令 - 点击输入框中的「+」按钮,在工具菜单中选择「Deep research」
选择数据源
Deep Research 支持三类数据源,可灵活组合使用。
默认数据源
默认情况下,Deep Research 可访问以下内容:
- 公开网页
- 用户上传的文件
连接的应用
当结果的可信度与可追溯性尤为重要时,Deep Research 可从已授权的应用与数据服务中获取信息,包括:
- 文档存储类: Google Drive、SharePoint 等
- 行业数据源: FactSet、PitchBook、Scholar Gateway 等经过身份验证的专业数据库
说明: Deep Research 仅对连接的应用执行读取操作,不会在研究过程中执行任何写入操作。
指定网站
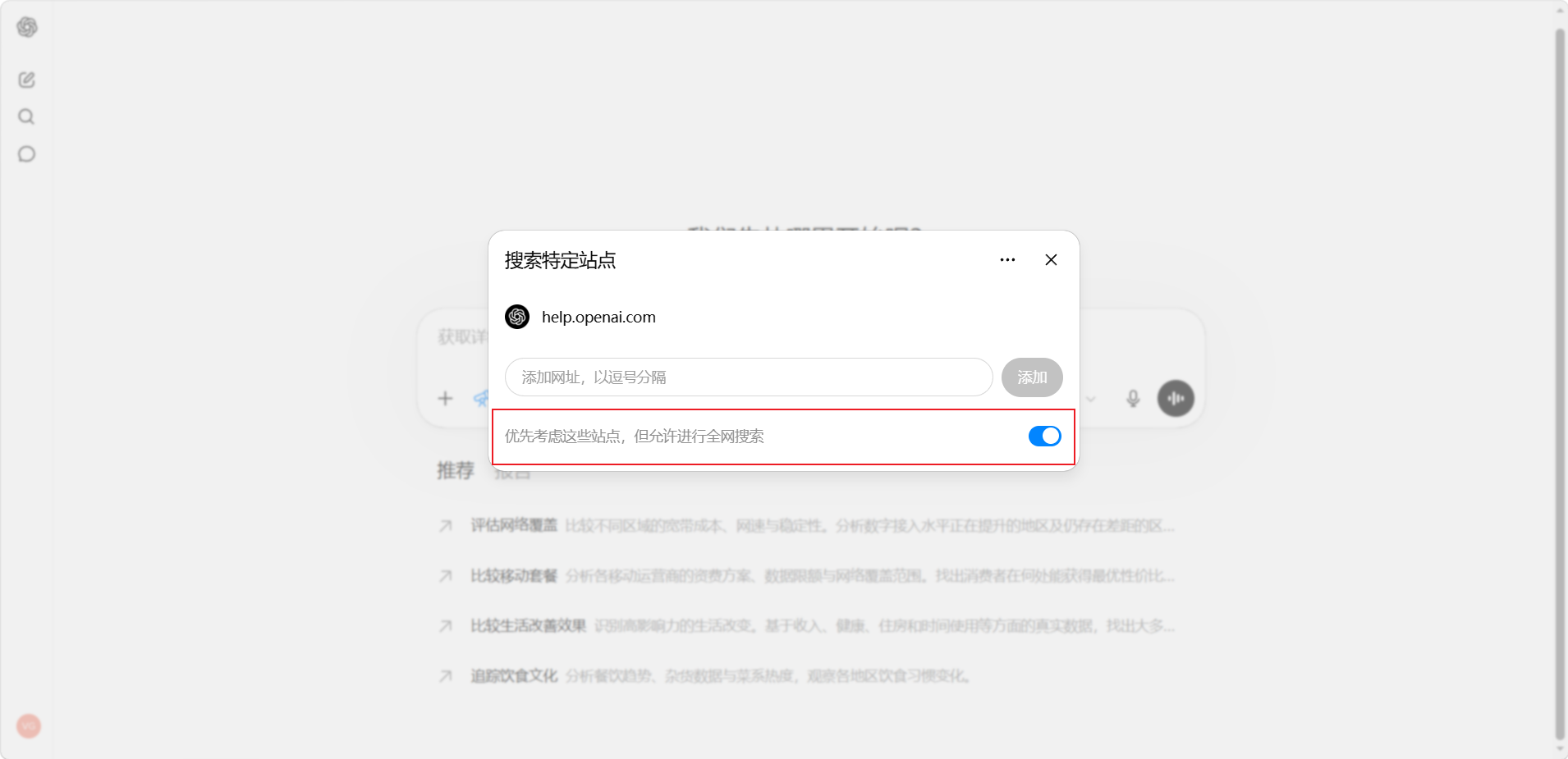
如需将研究范围限定在特定网站,可在 ChatGPT 输入框中选择「站点 > 管理站点」进行配置:
- 仅限指定来源: 关闭「优先考虑这些站点,但允许进行全网搜索」开关,将研究范围严格限制为所输入的网站或域名
- 优先指定来源: 开启「优先考虑这些站点,但允许进行全网搜索」开关,在重点参考指定来源的同时,仍允许进行全网搜索
提示:支持以逗号分隔的形式批量输入多个网站
撰写优质研究提示词
一份优质的 Deep Research 提示应清晰描述研究问题、期望产出与相关约束。提供充分的上下文有助于 ChatGPT 生成更贴合需求的研究计划,便于在研究启动前进行审阅与调整。
在正式开始研究前,Deep Research 可能会提出澄清问题以确认研究目标,并同步展示一份研究计划。用户可对该计划进行审阅与编辑,确保最终报告与研究意图保持一致。
提示词三要素:
示例:

链接:https://chatgpt.com/s/t_6a083ae4e8d881918578b4a185fa67ba
研究过程中的交互
澄清阶段
提交请求后,ChatGPT 可能先提出澄清问题:
研究计划确认
ChatGPT 会展示研究计划:
实时进度追踪
研究进行中会显示:
研究过程中可随时执行以下操作:
- 中断研究以调整研究焦点
- 修改可访问的数据源范围
- 实时查看研究进度
报告解读与导出
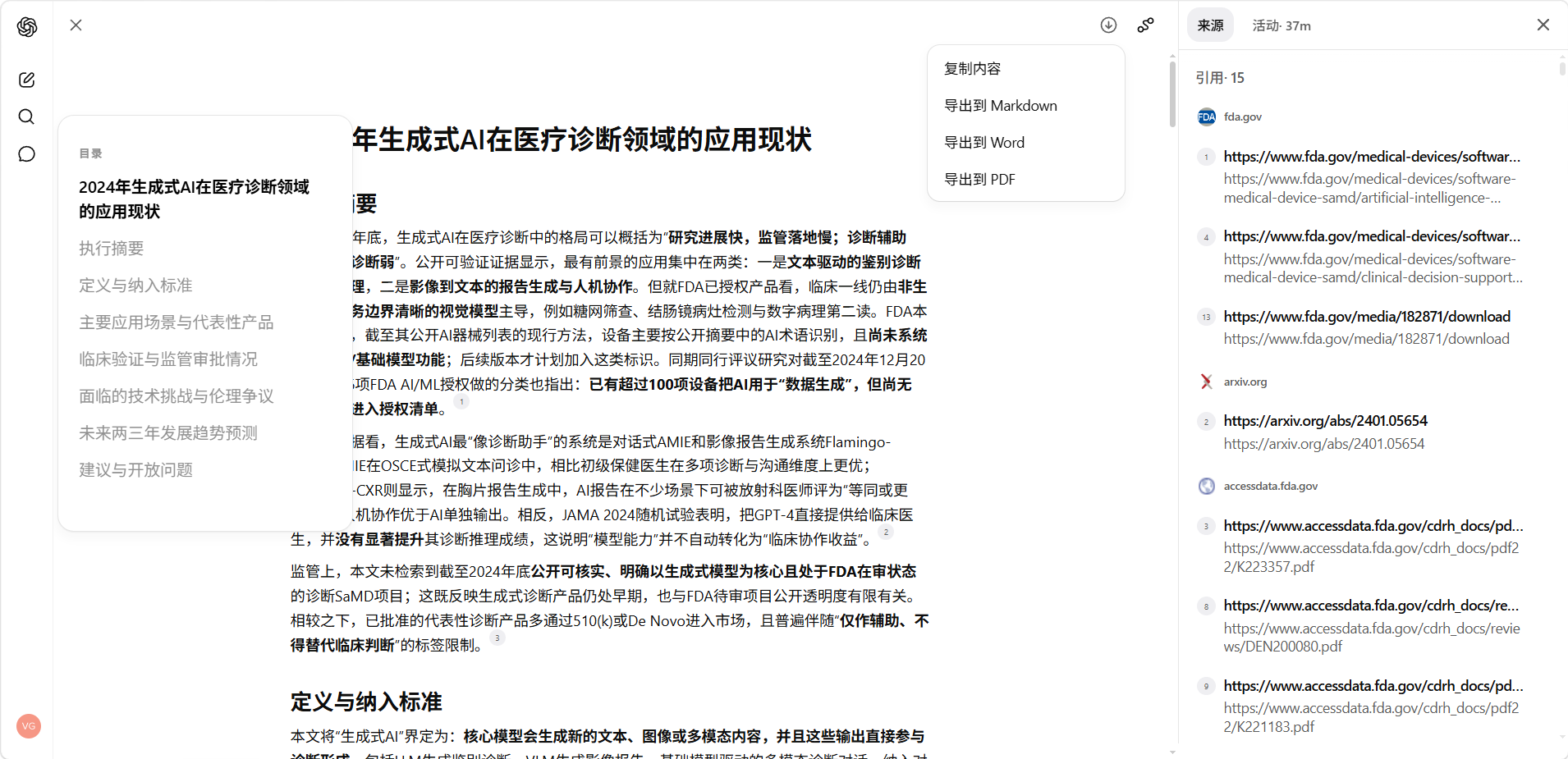
报告视图
研究完成后,报告将在全屏视图中打开,便于审阅与复用,包含以下核心组件:
- 目录(Table of contents): 用于在长篇报告中快速导航
- 来源列表(Sources used): 集中展示所有引用来源,便于核查
- 活动历史(Activity history): 完整记录研究过程的执行轨迹
下载格式
支持将完整报告导出为以下格式以便分享与复用:
- Markdown
- Word
引用来源的使用
所有 Deep Research 输出均附带引用或来源链接,可逐项核实信息。报告中的引用通常以角标或链接形式呈现:
验证流程建议:
- 对于关键数据,点击来源链接核实原文
- 检查来源的权威性与时效性
- 当多个来源存在矛盾时,优先采信更权威的来源
报告生成后的追问
报告生成后,可在同一会话中继续追问:
适用场景
市场与行业研究
技术方案选型
学术文献综述
竞品分析
政策法规梳理
不适用场景
实战案例:为创业项目做市场调研
第一步:提出研究请求
第二步:回答澄清问题
第三步:确认研究计划
第四步:获取报告并追问
常见问题
Q:Deep Research 在所有国家/地区都能使用吗?
不一定。是否可用取决于订阅计划及所在国家或地区。
Q:研究运行过程中可以做哪些控制?
研究启动前可编辑研究计划;运行过程中可实时查看进度、中断研究以调整焦点,并可更新研究可访问的数据源。
Q:能否为 Deep Research 选择其他模型?
可以。Deep Research 默认由最新模型驱动,如有需要,也可继续使用旧版模型执行研究任务。
Q:Deep Research 的结果会保留多久?
研究结果保留在对话历史中,除非主动删除对话。删除对话将同时删除关联的 Deep Research 输出。
Q:任务需要紧急获得答案怎么办?
如时间紧迫,建议使用普通搜索或标准对话以获得更快的响应,将 Deep Research 用于需要深度分析的场景。
Q:哪些应用可用于 Deep Research?
ChatGPT 中的所有应用均与 Deep Research 兼容。但具体可用的应用取决于订阅计划与工作区配置。
数据隐私与企业管控
数据隐私
使用 Deep Research 的对话遵循与常规 ChatGPT 对话相同的数据处理与隐私设置。用户可在数据控制中心管理数据保留与训练偏好。
企业管控(Enterprise / Edu)
- 基于角色的访问控制(RBAC): Enterprise 与 Edu 工作区的管理员可通过 RBAC 控制 Deep Research 的访问权限
- 应用启用控制: Deep Research 遵循与标准 ChatGPT 相同的应用启用控制规则——已允许的应用对 Deep Research 可用,已禁用的应用则不可用
- 合规 API: Deep Research 的活动记录会包含在 Conversation API 中,便于合规审计与追溯
评论
0 条