5. 语音
功能介绍
海螺AI的语音创作功能由 MiniMax Audio 提供技术支持,集成了 MiniMax Speech 2.8-hd 高清语音合成模型与 Music-2.5+ 音乐创作模型。整个语音模块分为两大板块:AI生成(语音合成、音乐创作)和AI工具(音色设计、声音克隆、人声提取),五大功能覆盖从内容创作到音频处理的完整链路。
语音合成(AI生成)
将文字输入后,选择喜欢的音色,一键生成高质量语音。支持在文字中插入「情绪标签」(如[开心]、[悲伤]、[惊讶])、「停顿标签」(如<#1.0#>表示停顿1秒)和「语气词标签」(如[嗯]、[哦]),实现对语音情感和节奏的精细控制。
音乐创作(AI生成)
输入歌词和音乐风格描述,AI即可生成完整的AI原创歌曲;也可选择「纯音乐」模式,根据风格描述生成无人声背景音乐,适用于视频配乐、短视频BGM等场景。
音色设计(AI工具)
通过文字描述来"定制"一个专属音色,例如"讲述悬疑故事的播音员,声音低沉富有磁性,语速时快时慢,营造紧张神秘的氛围",系统会据此生成专属音色并可保存至音色库供后续使用。
声音克隆(AI工具)
朗读一段指定文字,即可完整克隆你自己的声音,并将其用于后续文字转语音任务。开始录音即表示你已取得声音授权。克隆完成的音色可在「音色库 → 我的音色」中使用。
人声提取(AI工具)
上传含有环境噪音或背景音乐的音频/视频文件,AI会自动去除环境音和背景噪声,提取并增强原始人声的清晰度与纯净度。支持最大500MB、时长不超过300秒的文件。
提示:使用语音功能需要登录MiniMax语音账号。
语音合成
点击左侧边栏「音频」,或直接访问 MiniMax Audio。
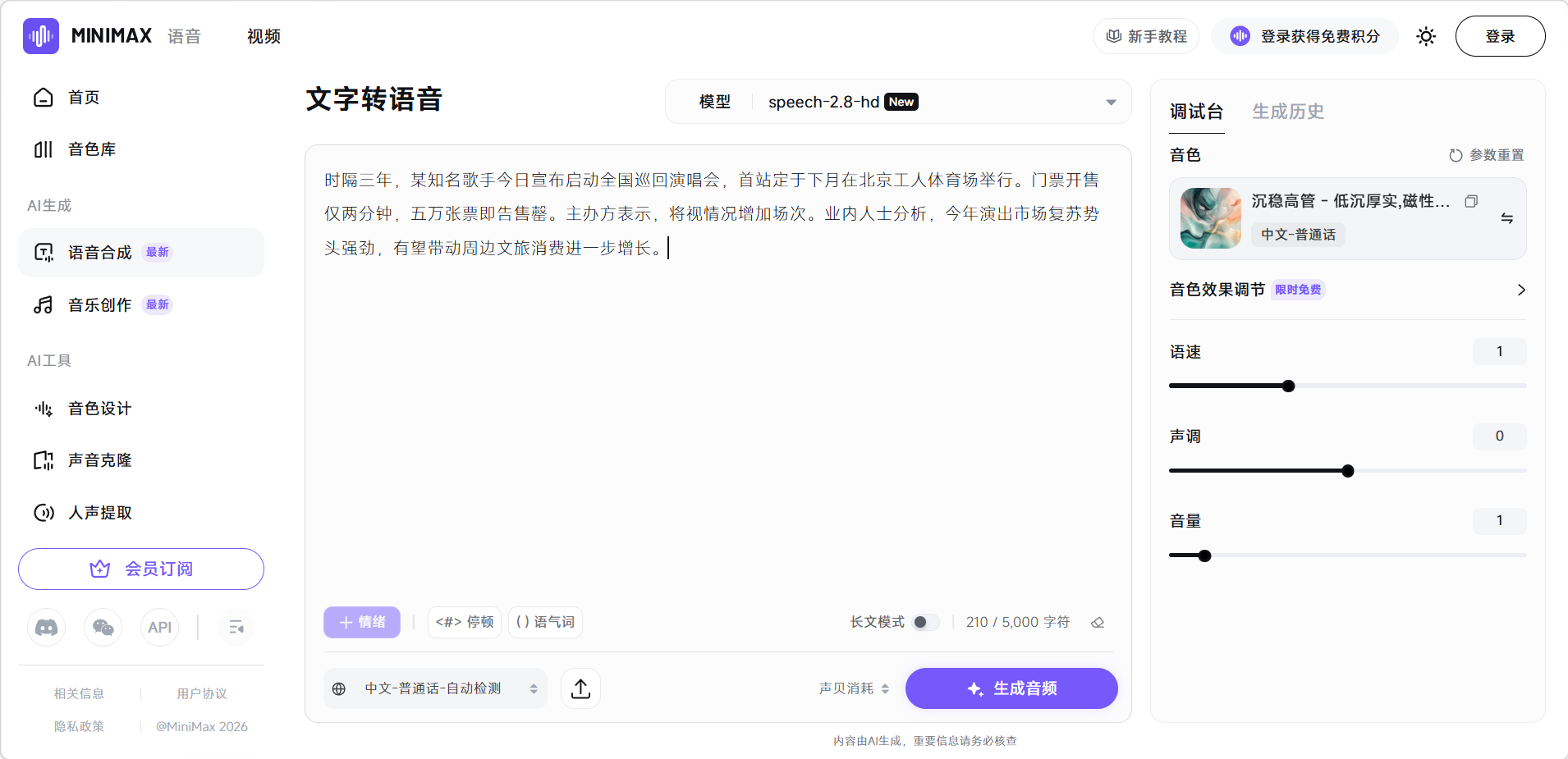
点击左侧「语音合成」,在文本输入区输入需要合成的文字(最多5000字符,开启「长文模式」后支持更多,但等待时间更久)。
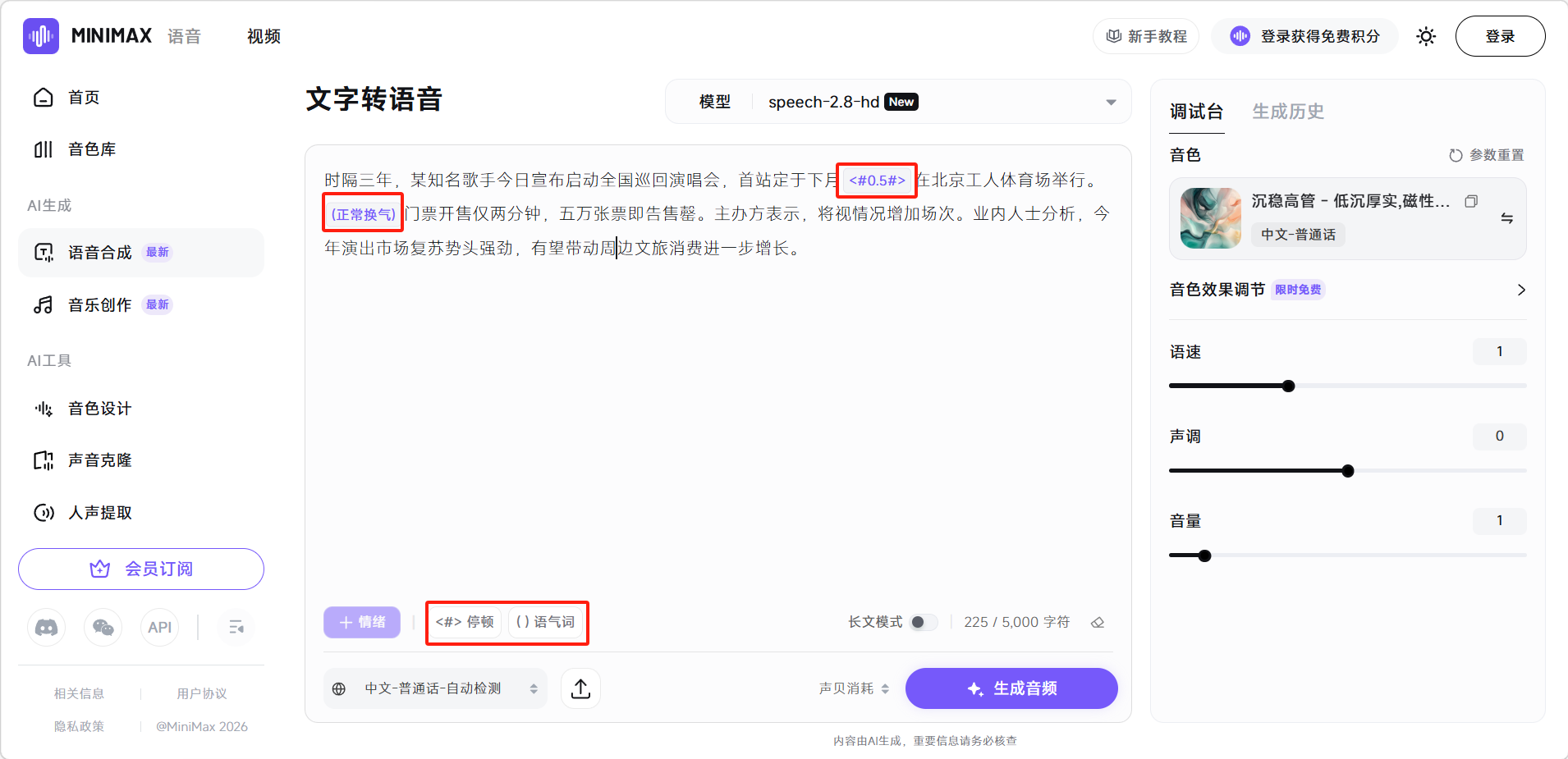
还可以点击下方的「停顿」和「语气词」按钮,在光标的位置添加停顿时间和语气词。
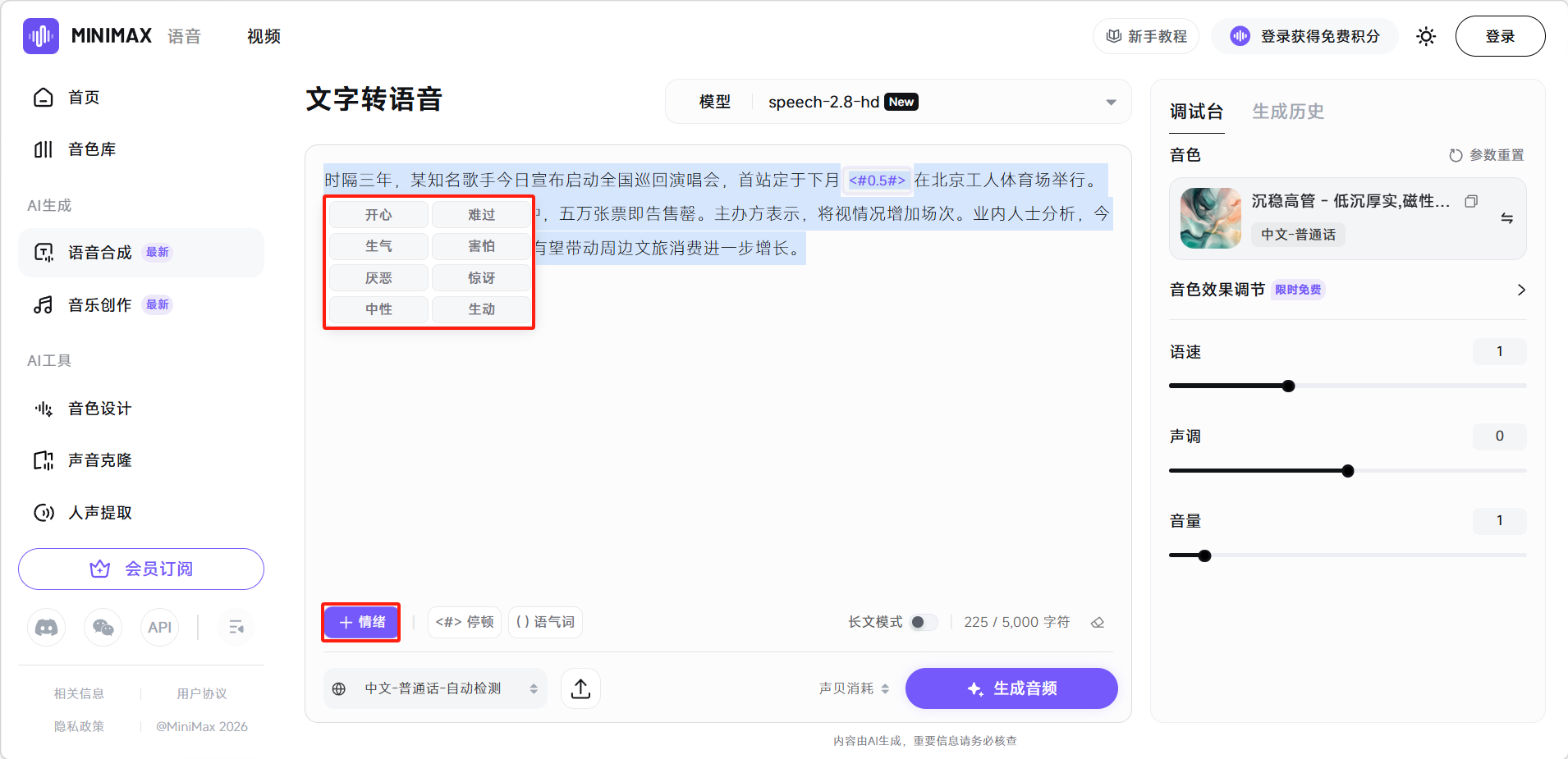
框选文本后还可以设置朗读文字的情感。
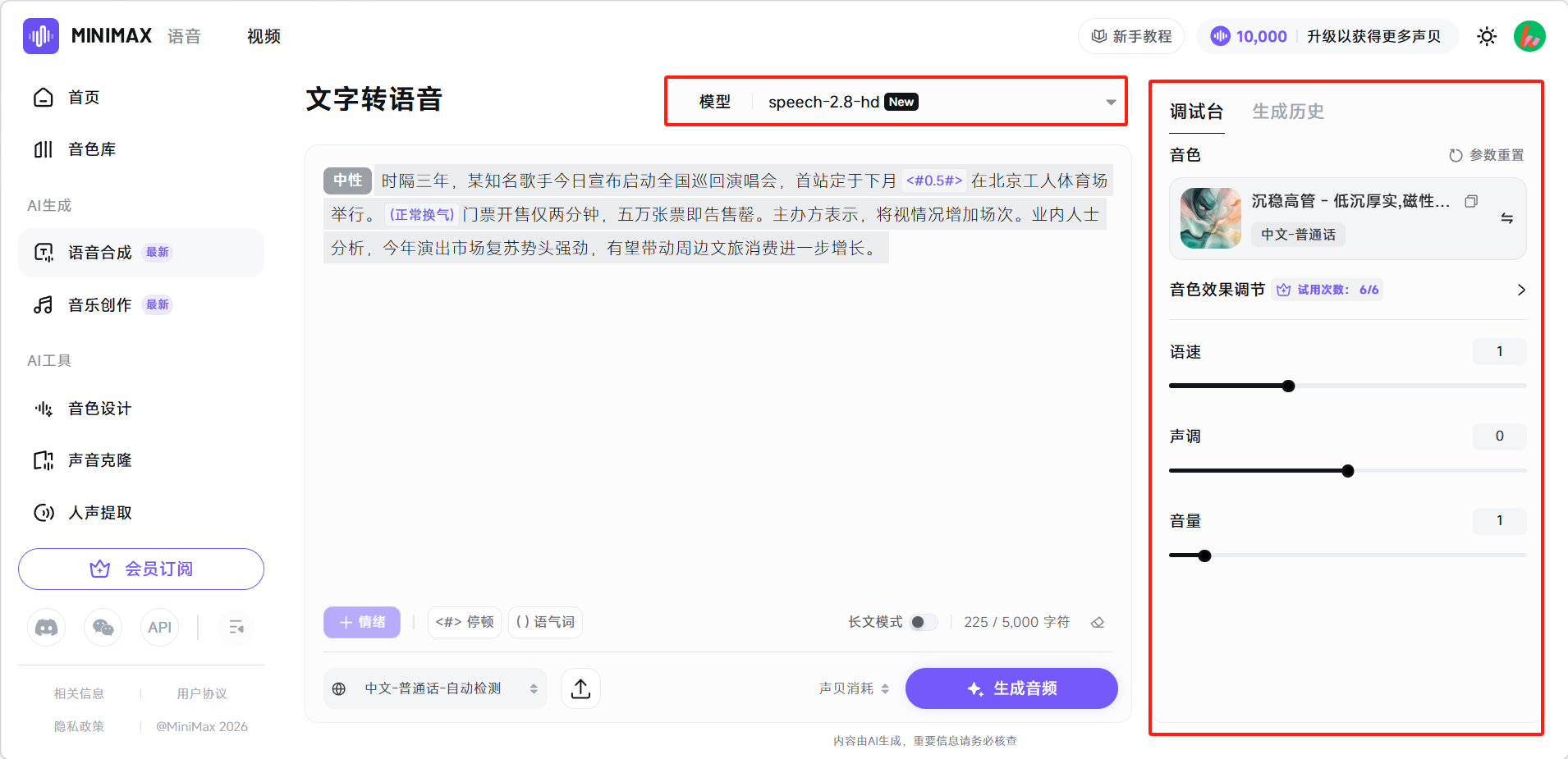
右侧边栏可以设置音色、语速、声调、音量。用户可以自行搭配。最后选择模型,设置成完成后点击「生成音频」即可。
生成效果展示。
使用技巧
- 长文稿建议分段合成:将长文按自然段或情绪转折点切分,每段单独生成后在剪辑软件中拼接,这样可以对每段单独调整音色和语速,整体效果更自然。
- 情绪标签嵌入技巧:在对话或旁白中插入情绪标签时,建议将标签紧贴对应文字,如「他激动地喊道[激动]:我终于做到了!」比放在句首效果更精准。
- 利用停顿标签控制节奏:在新闻播报、广告配音场景中,用<#0.5#>(半秒停顿)隔开不同语句,可以让语音听起来更从容专业,避免语速过快连成一片。
- 同一段文字尝试多个音色:不同音色对同一段文字的诠释差异很大,建议先用2-3个候选音色各生成一次,对比后再决定最终方案。
- 语速和声调微调:语速调至0.85-0.95之间通常比默认1.0更具亲切感,适合情感类内容;新闻、解说类内容可保持1.0或调至1.05,显得干练利落。
示例一
示例二
音乐创作
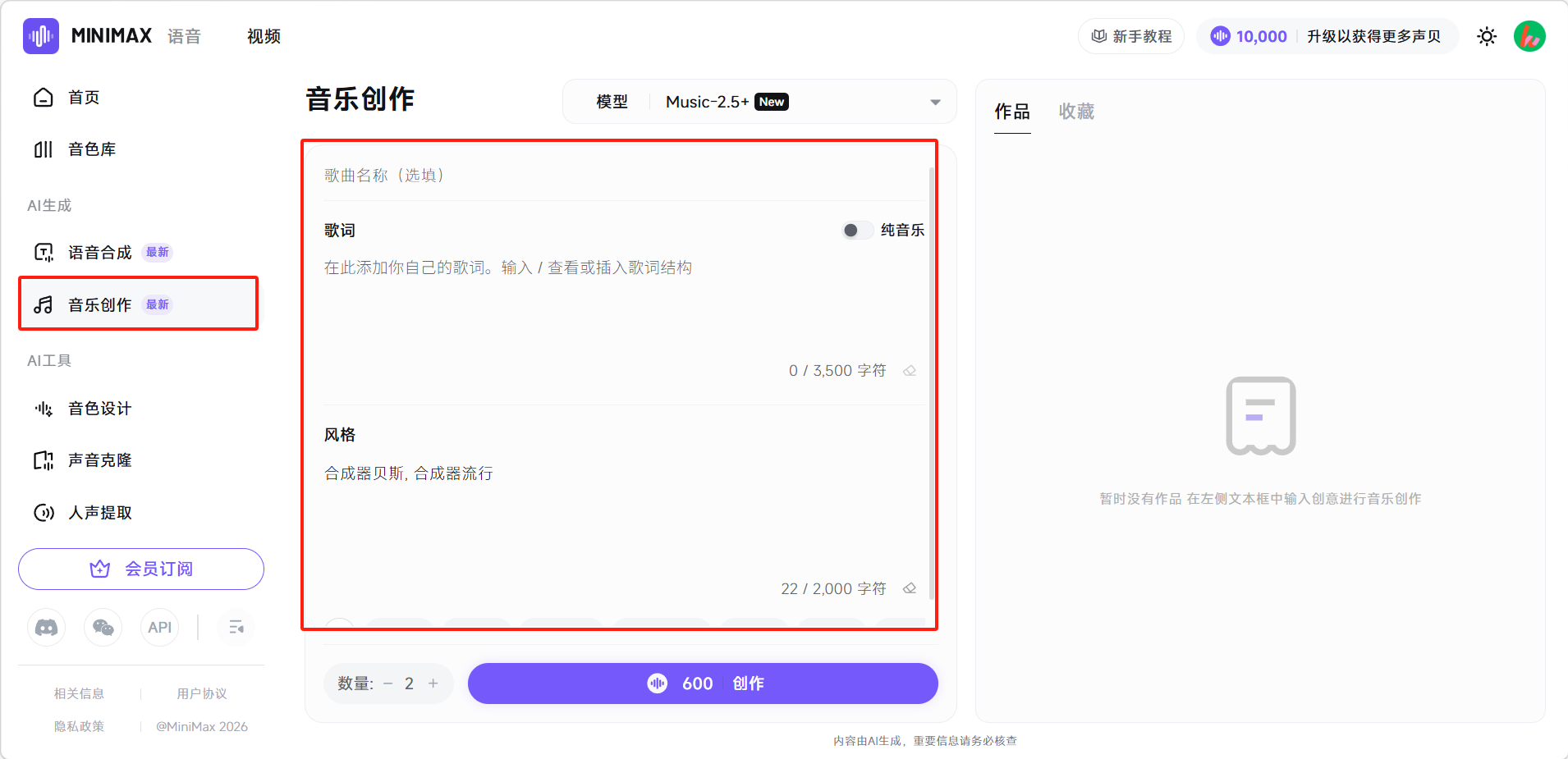
点击左侧「音乐创作」进入创作界面,填写歌曲名(可选填),完整歌词(最多3500字符)和音乐风格。
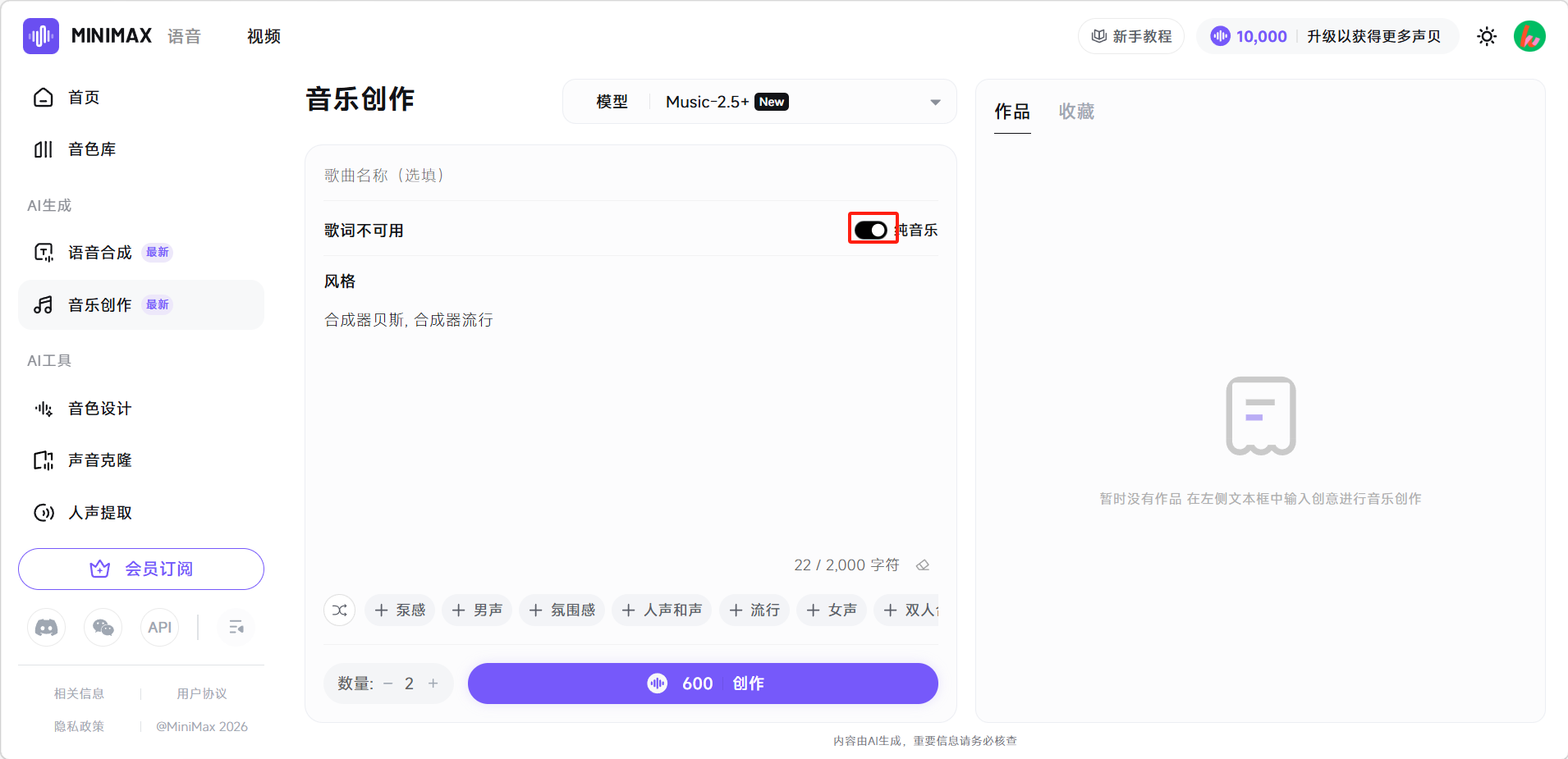
如果不想写歌词,点击「纯音乐」按钮即可。
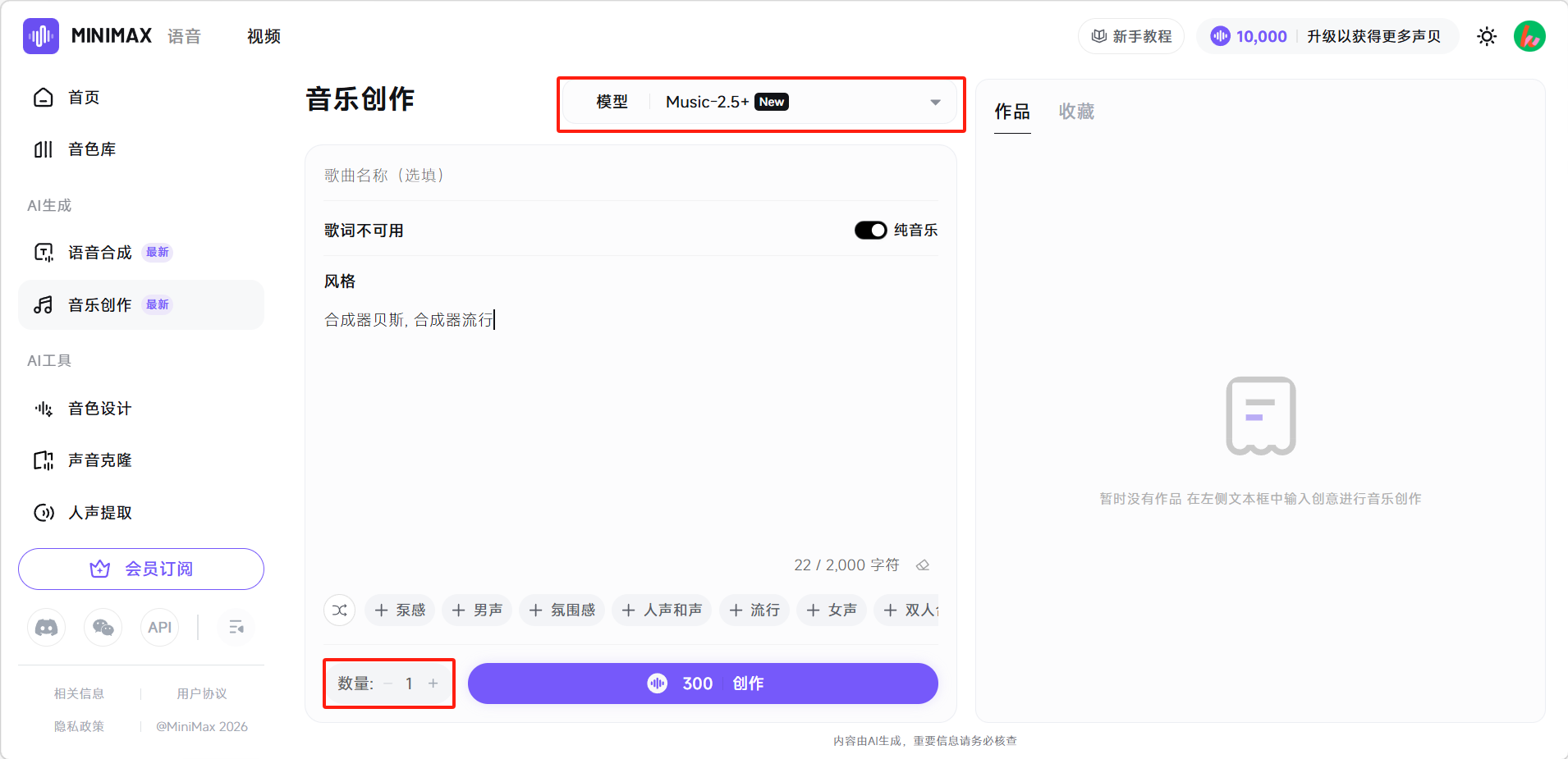
设置生成数量后,选择创作模型。点击「创作」按钮即可。
生成效果展示。
使用技巧
- 风格描述越具体,效果越好:不要只写"流行音乐",而是写"抒情流行,女声,钢琴+弦乐编曲,节拍偏慢,适合睡前聆听",这样AI对风格的把握会更准确。
- 纯音乐模式适合视频配乐:如果需要视频BGM,选择「纯音乐」模式并描述画面的情绪和节奏,例如"轻快活泼的背景音乐,适合美食探店视频,有清脆的吉他和手鼓节奏"。
- 同一歌词生成多次:同一套歌词每次生成的旋律都不同,建议设置生成数量为2-4首,从中挑选最满意的旋律版本。
- 歌词分节技巧:歌词中用空行分隔主歌、副歌和过渡段,有助于AI理解歌曲结构,生成的音乐段落感会更清晰。
示例一
示例二
音色设计
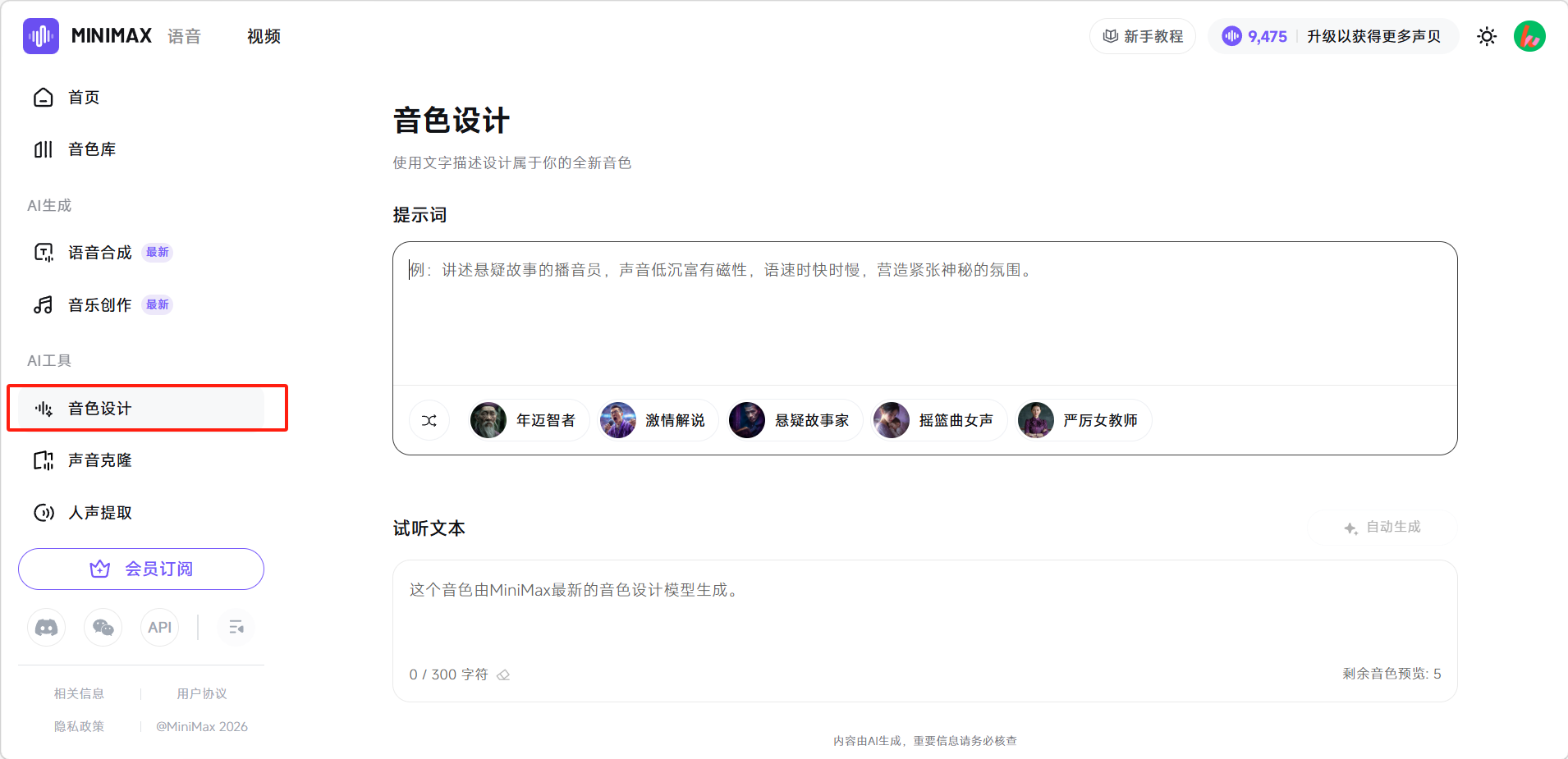
点击左侧「音色设计」进入设计页面。
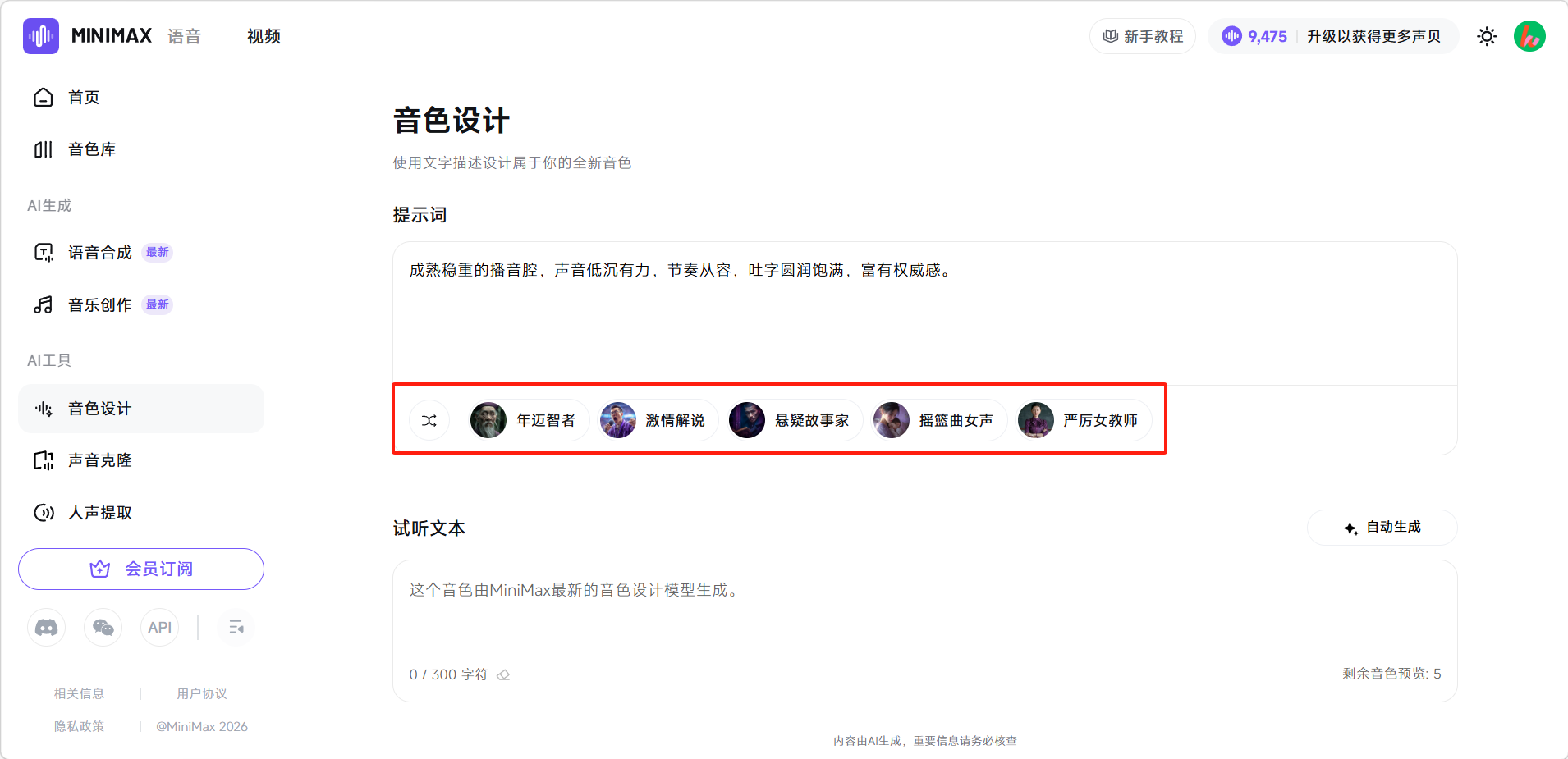
描述想要的音色或选择下方预设的模板。然后点击「自动生成」。
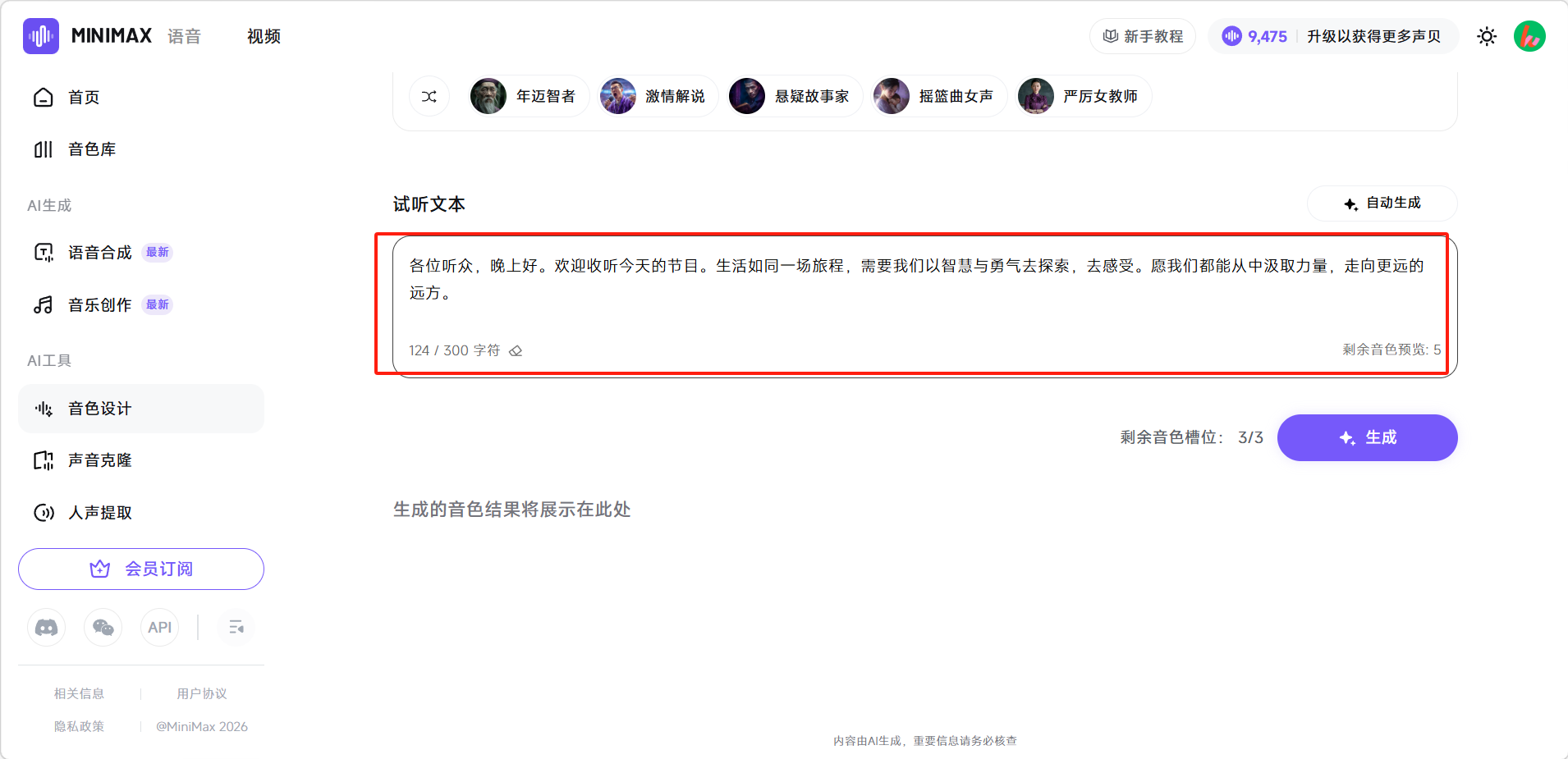
自动生成完成后在「试听文本」输入框会生成一段试听文本,点击下方「生成」即可试听。
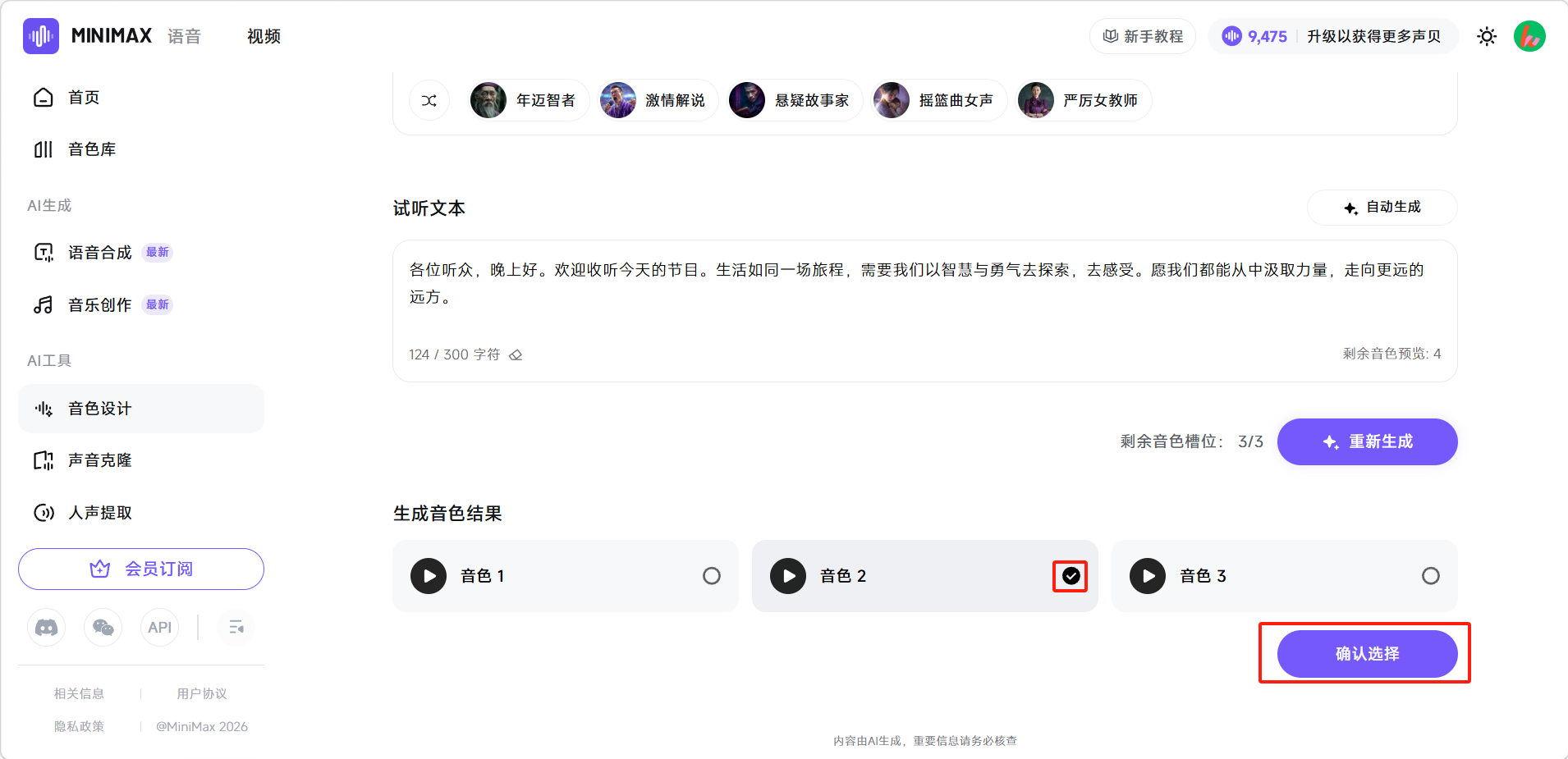
选择满意的音色,点击「确认选择」。
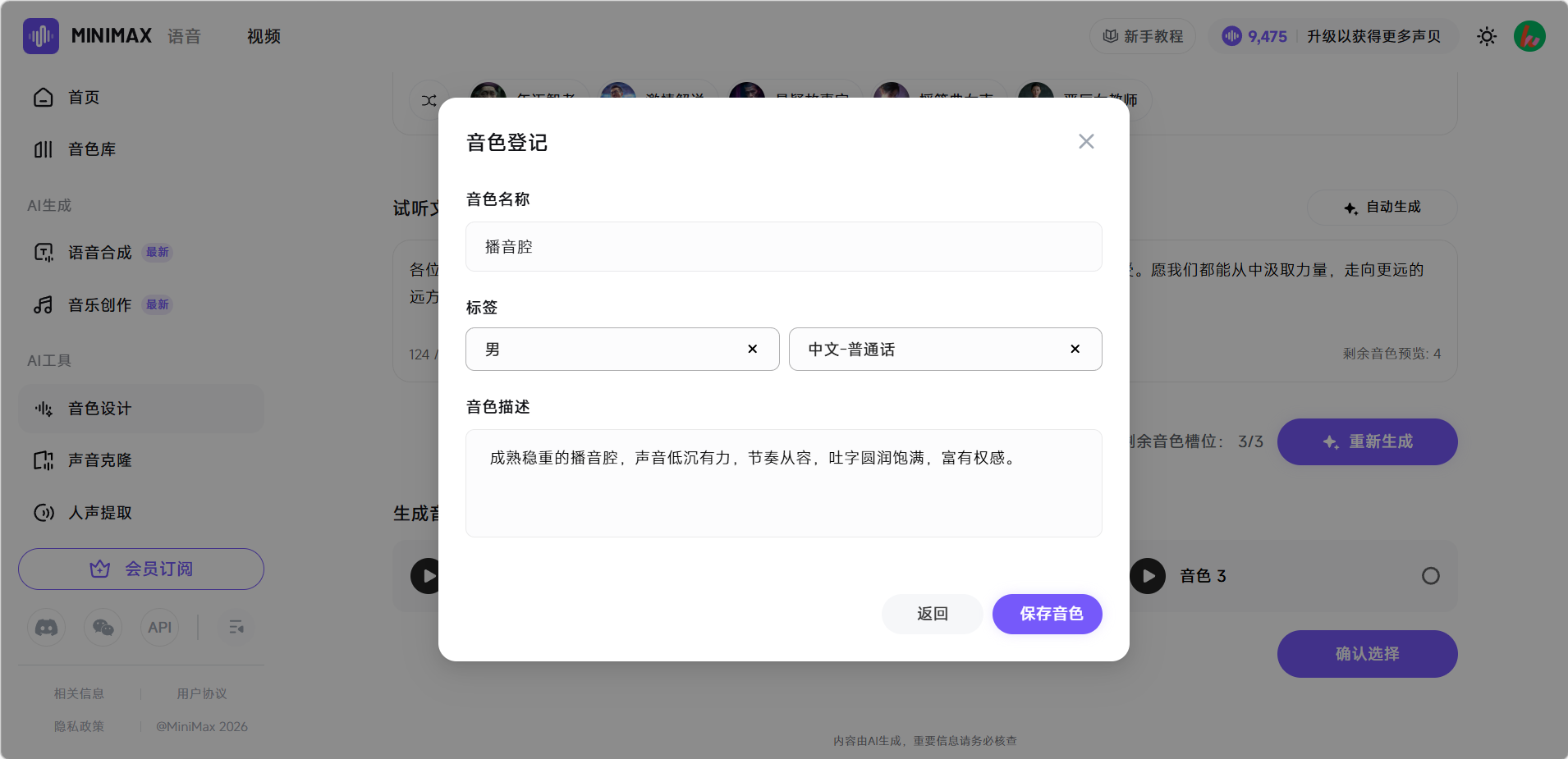
设置音色的名称,性别,和语言。点击「保存音色」即可。
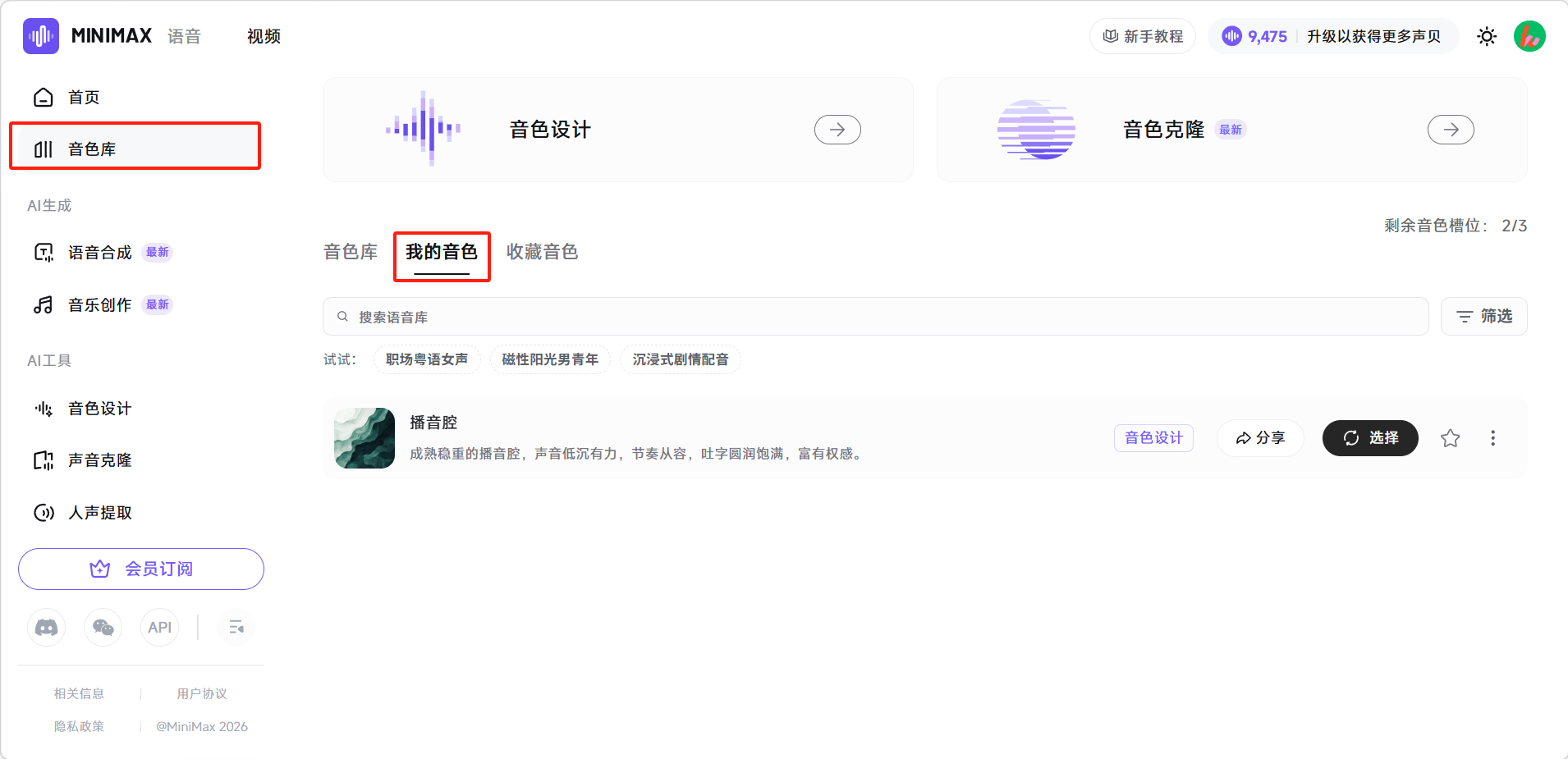
保存好的音色可在「音色库」>「我的音色」中找到。
使用技巧
- 音色描述要包含声音特征、说话风格和使用场景三个维度,这样设计出的音色与预期最接近。例如:「一位30岁左右的男性,声音低沉且有磁性,说话沉稳不急促,适合商业纪录片解说」。
- 多次生成对比:点击「自动生成」可以生成多个版本的音色,再逐一试听,从中选择最贴合需求的版本。
- 保存命名规范:建议给自定义音色起一个有意义的名字(如"悬疑男声-低沉版"、"活泼女声-清脆版"),方便后续创作时快速找到对应音色。
- 设计好的音色可直接用于「语音合成」:保存后的自定义音色会出现在语音合成的音色列表中,可直接调用,实现专属声音批量输出。
示例一
示例二
声音克隆
点击左侧边栏「声音克隆」进入页面。
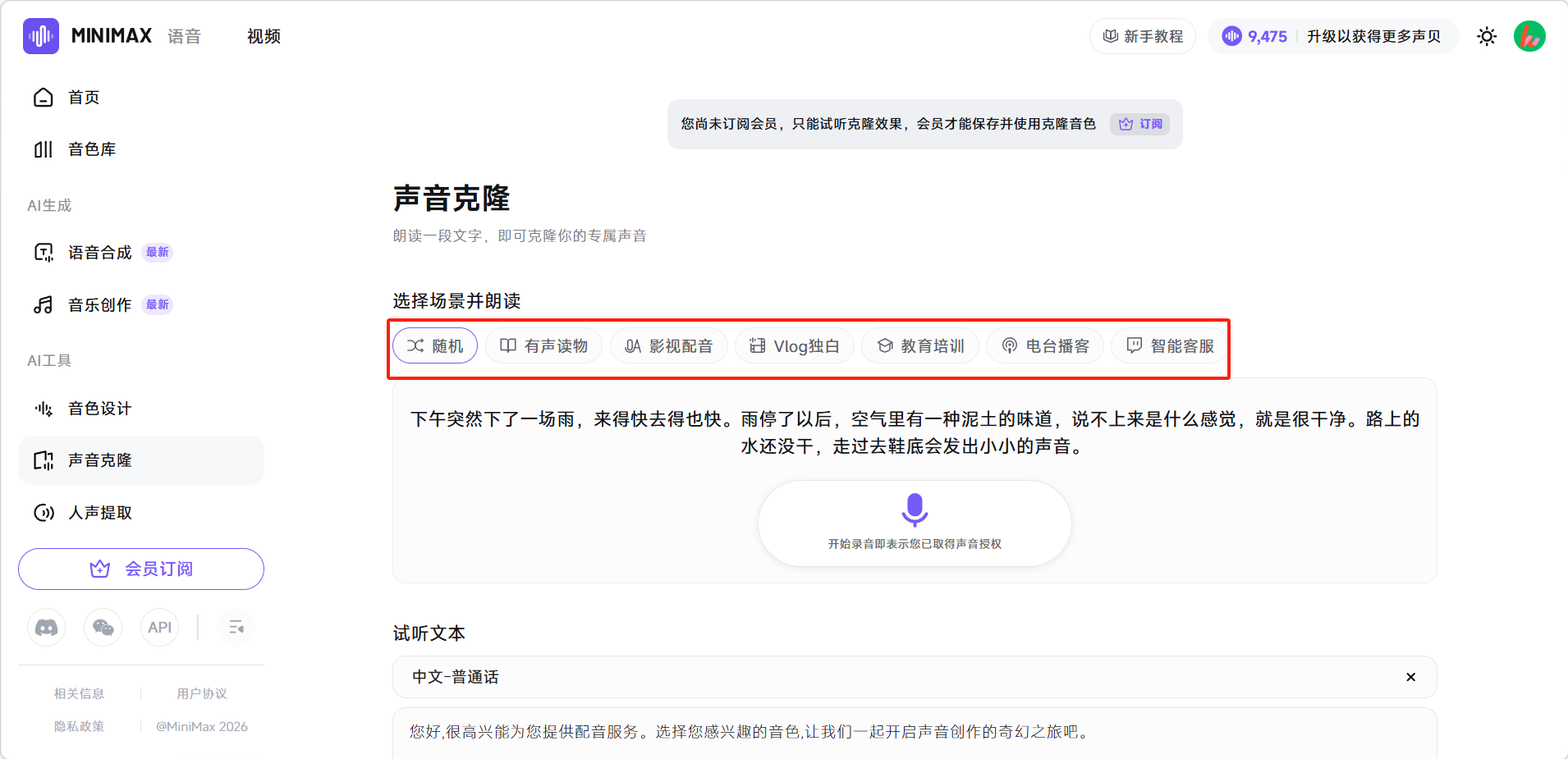
选择朗读场景,系统会提供对应的朗读文本。
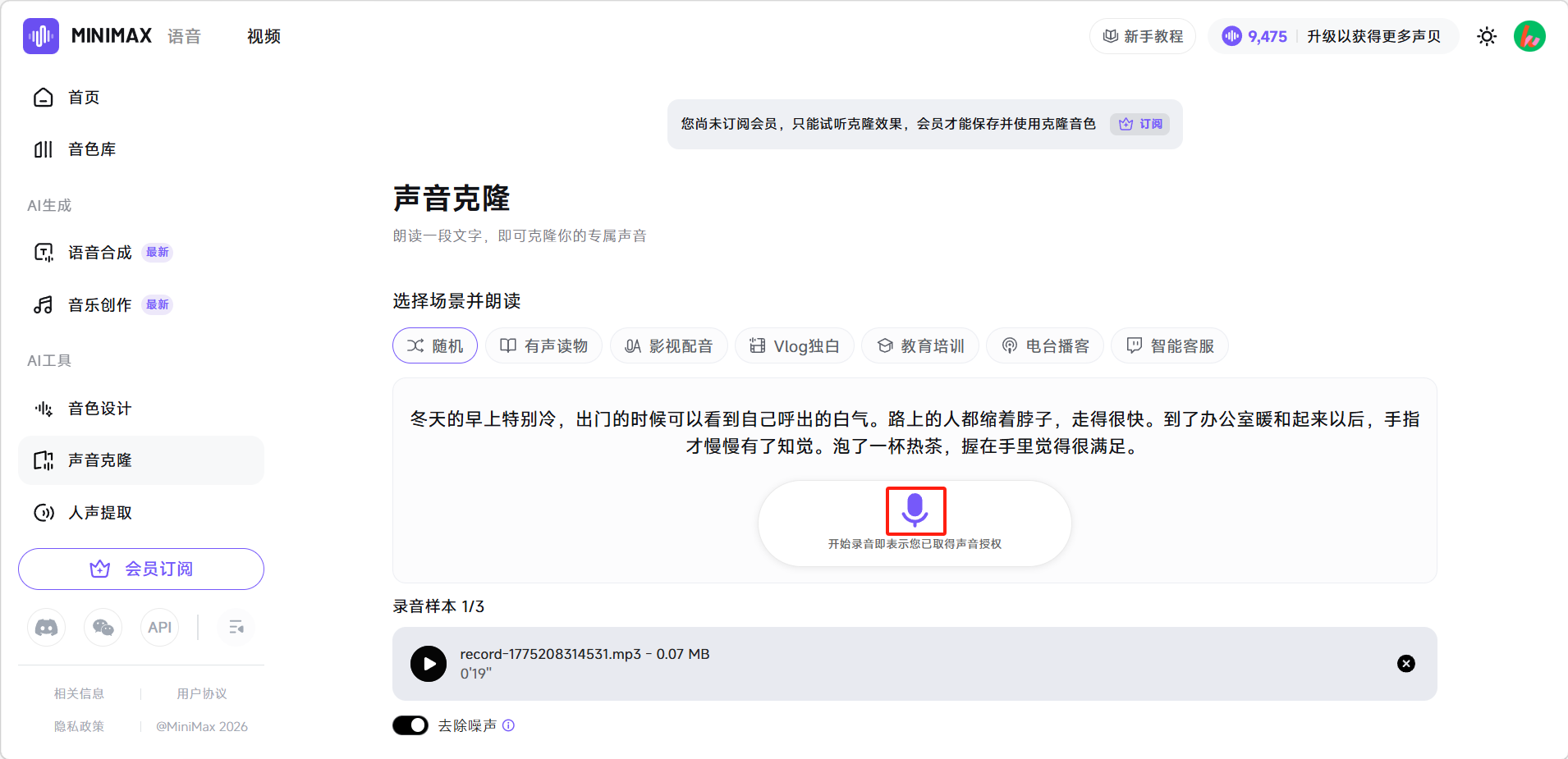
点击录音按钮开始朗读(建议在安静环境下进行)。
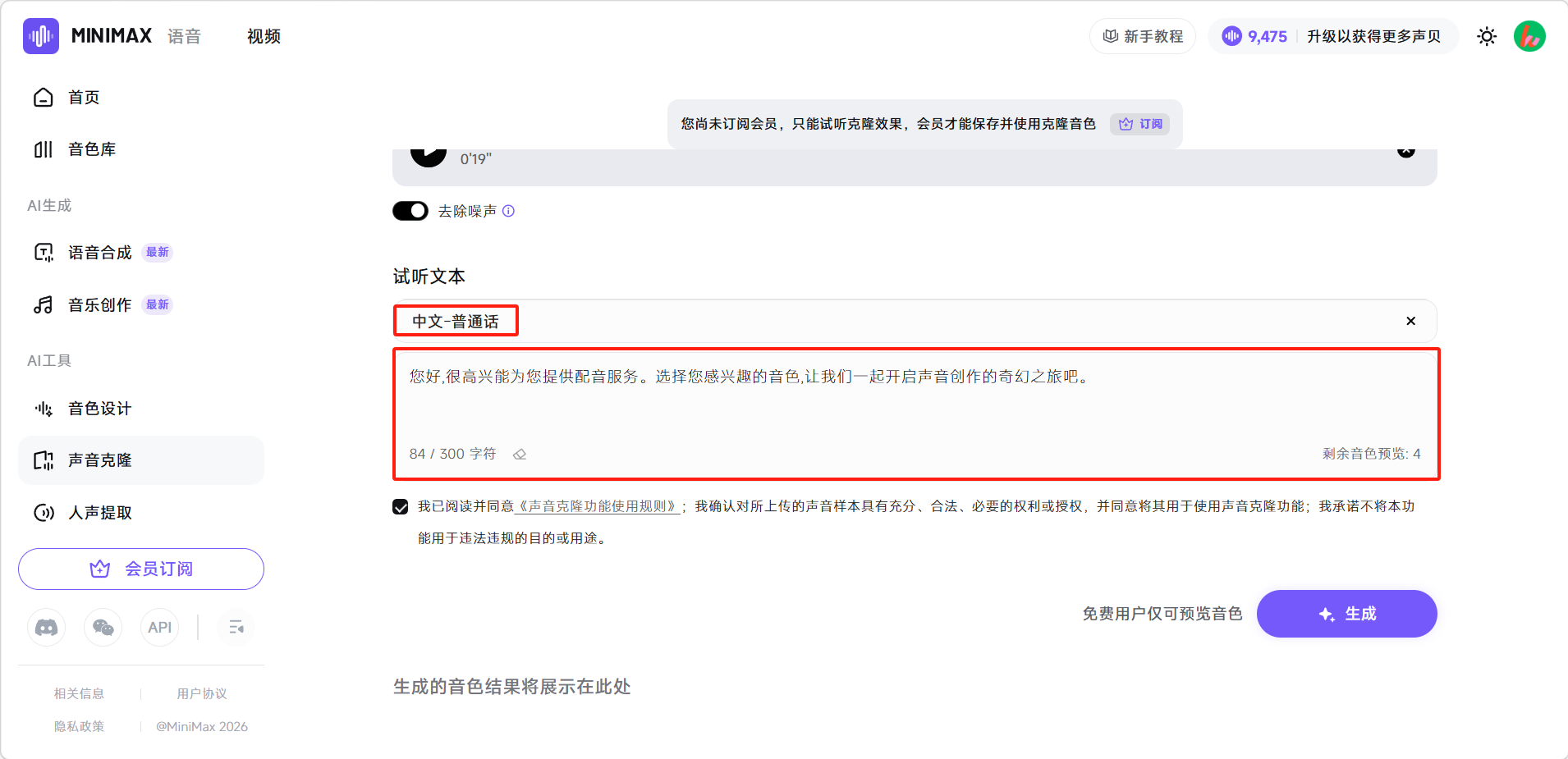
录制完成后,在下方选择试听的语言和文本,点击右下角「生成」。
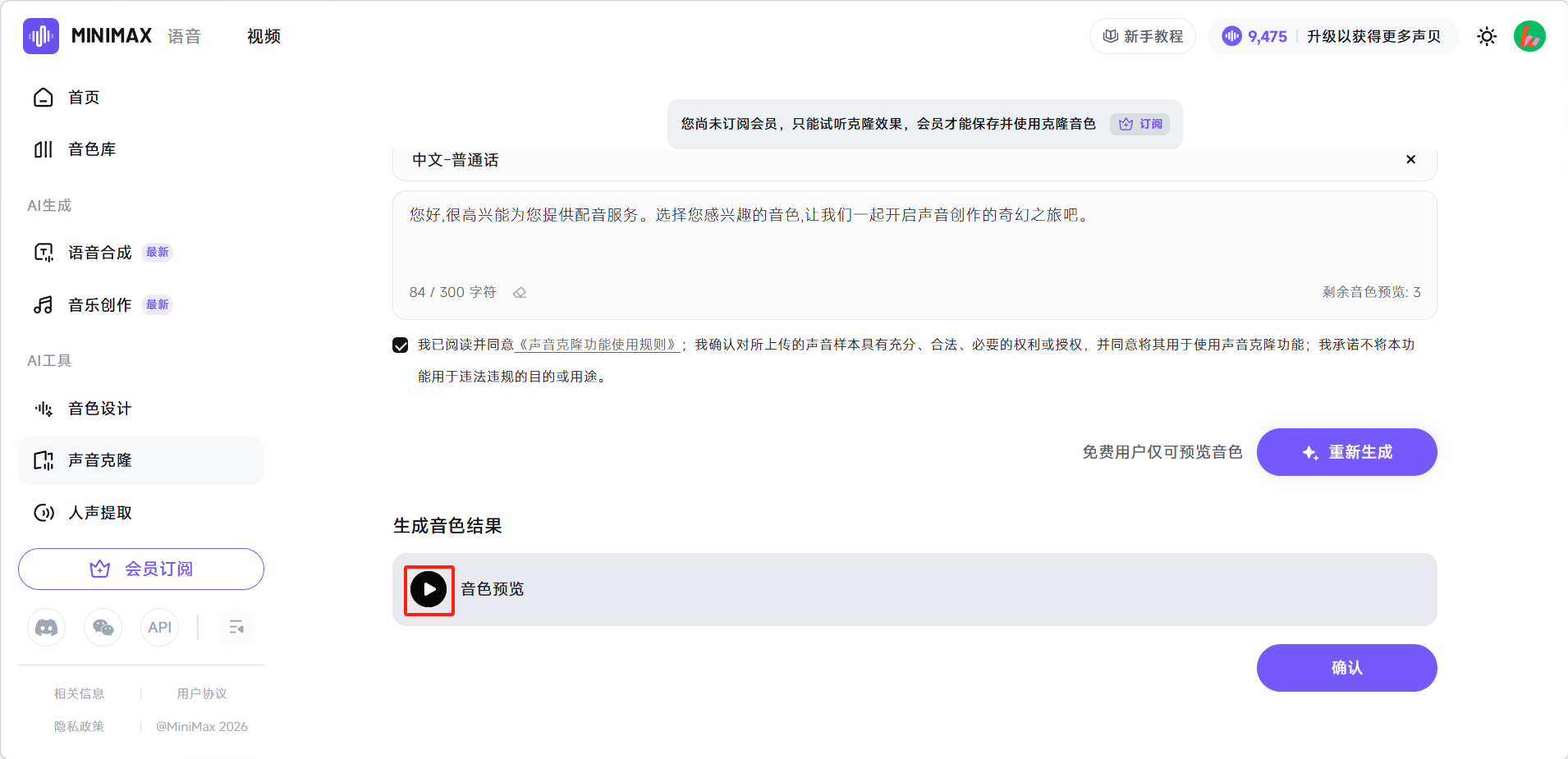
生成完成后点击播放键即可试听克隆的音色。没问题后点击右下角确认即可保存。
使用技巧
- 录音环境至关重要:选择安静的室内环境,关闭风扇、空调等噪音源,距离麦克风15-20cm正面朗读,效果最佳。录音时避免手机通知干扰,建议开启勿扰模式。
- 朗读时保持自然状态:不要刻意表演或"播音腔",用日常说话的节奏和语调朗读指定文本,这样克隆出的音色在后续合成时会更加自然。
- 录制多个场景版本:平台提供多种朗读场景(如"新闻播报"、"情感旁白"等),建议选择与自己实际使用场景最接近的,克隆效果会更对口。
- 克隆后先用短文测试:保存克隆音色后,先用一段简短的测试文字生成音频,听一听效果,确认与本人声音的相似度后再大量使用。
示例一
示例二
人声提取
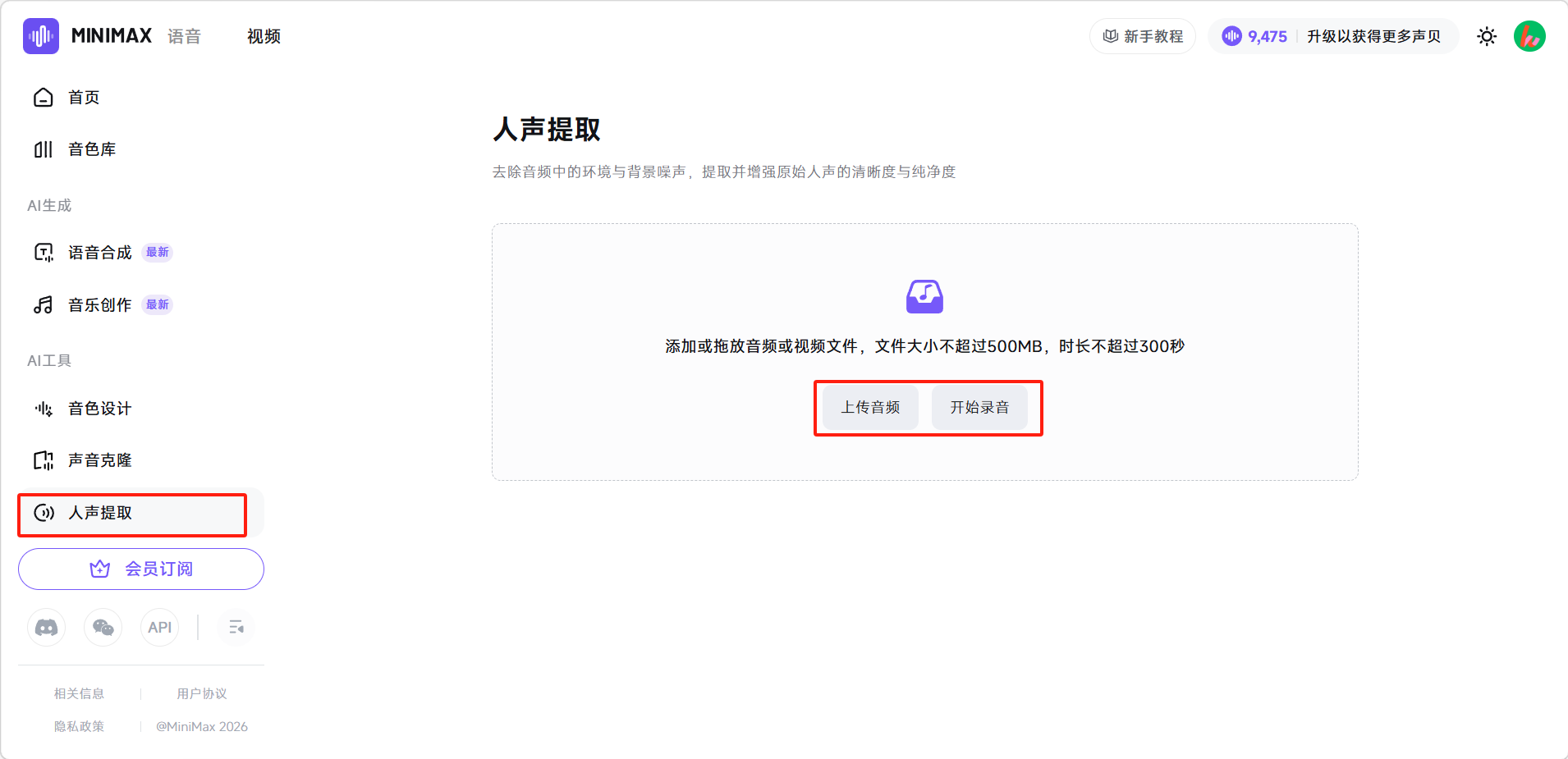
点击左侧边栏「人声提取」进入页面,点击「上传音频」或「开始录音」,添加需要处理的音频/视频文件。
上传成功后点击「提取人声」。
等待AI处理完成,下载提取后的干净人声文件即可。
使用技巧
- 支持上传音频或视频文件:既可以上传MP3、WAV等纯音频文件,也可以直接上传含有人声的视频文件(如录制的采访视频),系统会自动处理并提取干净的人声。
- 文件大小和时长限制:单次上传文件最大500MB,时长不超过300秒。若原始文件较长,建议先在剪辑软件中裁切到目标片段再上传处理。
- 提取后的人声可直接用于声音克隆:如果想克隆某人的声音但没有干净的录音素材,可以先用人声提取功能处理带背景音的视频,再将提取的干净人声用于声音克隆(注意遵守平台规定,仅限处理已获授权的声音)。
- 适合处理户外采访和会议录音:户外拍摄或会议室录音通常夹杂大量环境噪音,人声提取功能可以有效净化这些素材,让后期配音和字幕工作更顺畅。
示例一
示例二
进阶创作思路
语音功能与平台其他功能结合,可以解锁更多创作可能:
方案一:语音合成 + 视频生成,制作完整配音视频。先在「创作视频」中生成视频片段,再在「语音合成」中根据视频时长和节奏生成配音(注意控制语音时长与视频时长匹配),最后在剪辑软件中合轨,即可得到有画有声的完整短视频。
方案二:音色设计 + 大批量内容生产。如果需要为多个系列视频制作配音,先通过「音色设计」定制一个专属品牌音色,再批量将文稿输入「语音合成」,以这个固定音色生成所有配音文件,有效建立内容的声音品牌识别度。
方案三:人声提取 + 声音克隆,打造个性化声音素材库。如果你有一些录制较早、质量不稳定的历史音频,可以先用「人声提取」清洗音质,再结合「声音克隆」重建更清晰的克隆音色,让旧内容也能焕发新生。
评论
0 条