#7. 代码生成
讯飞星火覆盖主流编程语言,能够胜任代码生成、解释、检错、推理及单元测试等多种开发任务。只需描述功能需求或粘贴代码片段,即可获得符合要求的代码输出、清晰的逻辑讲解,或系统性的错误排查与测试支持,有效提升开发效率与代码质量。
#两种使用方式
对话框直接提问
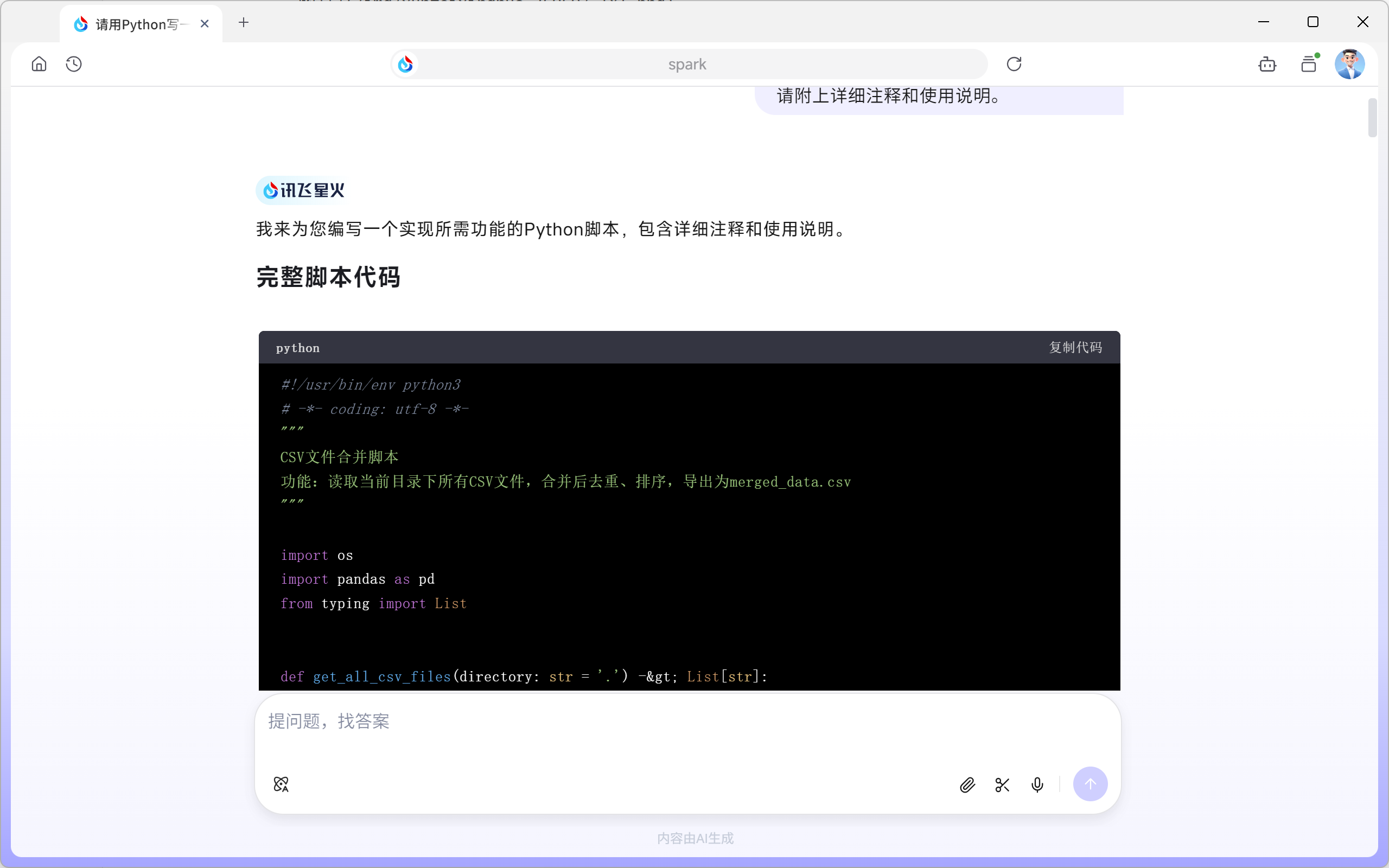
在对话框上方选择「通用」直接输入代码需求即可使用。
使用编程智能体
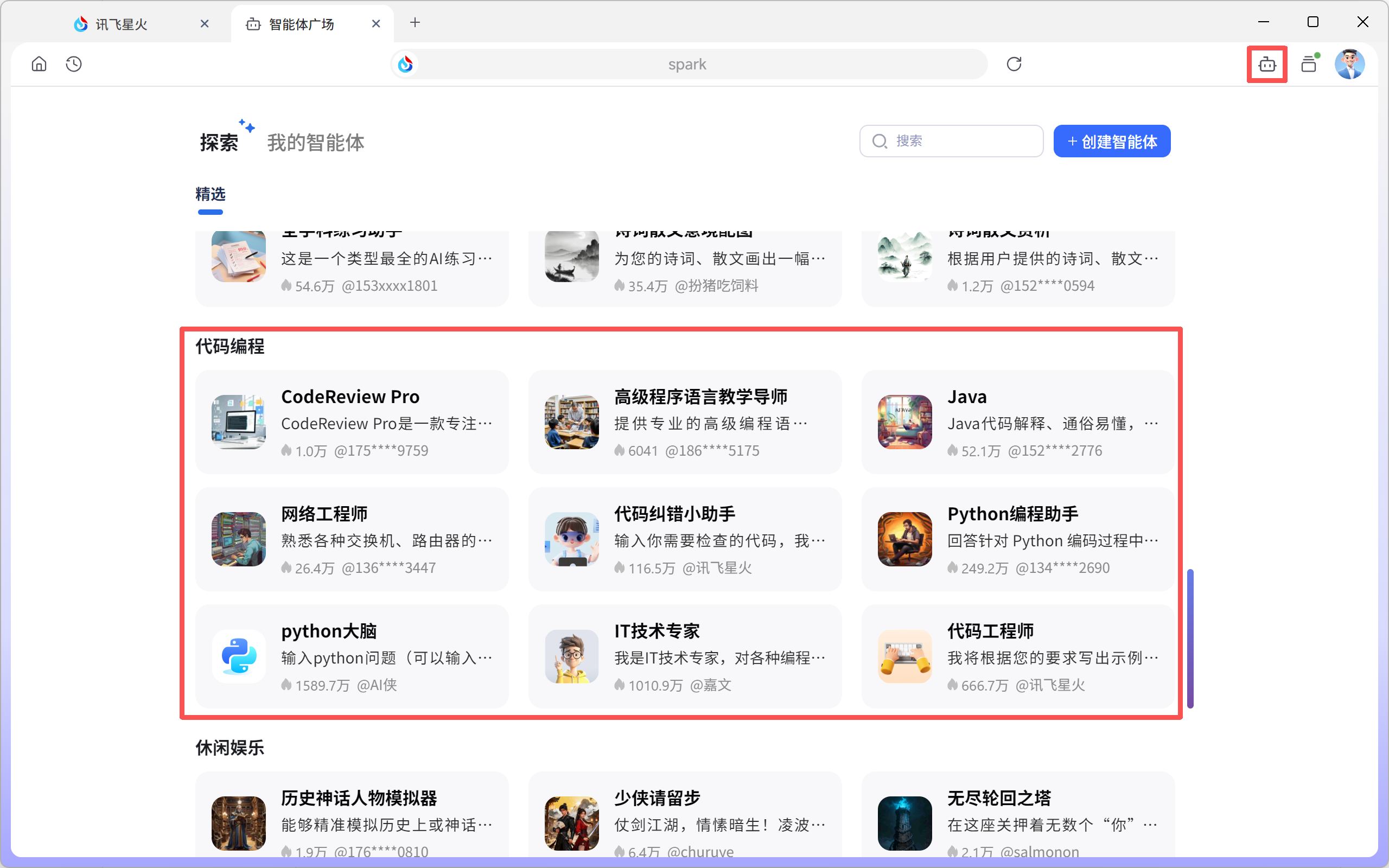
在智能体广场搜索编程相关智能体使用。
#示例场景
示例一:生成代码
请用Python写一个脚本,实现以下功能:
- 读取当前目录下所有的.csv文件
- 将它们合并成一个DataFrame
- 去除重复行
- 按"日期"列排序
- 导出为一个新的merged_data.csv文件
请附上详细注释和使用说明。输出结果:
import os
import pandas as pd
from typing import List
def merge_csv_files(
output_filename: str = "merged_data.csv",
date_column: str = "日期",
encoding: str = "utf-8"
) -> None:
"""
合并当前目录下所有CSV文件,去重、按日期列排序,并导出为新的CSV文件。
参数:
output_filename (str): 输出文件名,默认为"merged_data.csv"
date_column (str): 用于排序的日期列名,默认为"日期"
encoding (str): 文件编码格式,默认为"utf-8",可根据实际情况修改为"gbk"等
返回:
None
"""
# 1. 获取当前工作目录
current_dir = os.getcwd()
print(f"当前工作目录:{current_dir}")
# 2. 筛选当前目录下所有.csv文件(排除输出文件自身,避免重复运行时把结果再次并入)
csv_files: List[str] = []
for file in os.listdir(current_dir):
if file.lower().endswith(".csv") and file != output_filename:
file_path = os.path.join(current_dir, file)
csv_files.append(file_path)
if not csv_files:
print("当前目录下未找到任何CSV文件,程序退出!")
return
print(f"找到 {len(csv_files)} 个CSV文件:")
for file in csv_files:
print(f" - {file}")
# 3. 读取并合并所有CSV文件
merged_df = pd.DataFrame() # 创建一个空的DataFrame用于累积合并结果
for file_path in csv_files:
try:
# 读取CSV文件,根据实际编码调整encoding参数
df = pd.read_csv(file_path, encoding=encoding)
print(f"成功读取文件:{file_path},数据行数:{len(df)},列数:{len(df.columns)}")
# 将当前文件数据追加到总DataFrame中
merged_df = pd.concat([merged_df, df], ignore_index=True, sort=False)
except Exception as e:
print(f"读取文件 {file_path} 失败:{str(e)},跳过该文件!")
if merged_df.empty:
print("所有CSV文件均为空或读取失败,合并后的数据为空,程序退出!")
return
# 4. 去除重复行
initial_rows = len(merged_df)
merged_df.drop_duplicates(inplace=True)
after_dedup_rows = len(merged_df)
print(f"去重前数据行数:{initial_rows},去重后数据行数:{after_dedup_rows},共去除 {initial_rows - after_dedup_rows} 行重复数据")
# 5. 检查是否存在日期列,若存在则按日期列排序
if date_column in merged_df.columns:
try:
# 尝试将日期列转换为datetime类型,确保正确排序
merged_df[date_column] = pd.to_datetime(merged_df[date_column])
# 按日期列升序排序
merged_df.sort_values(by=date_column, inplace=True)
print(f"已按'{date_column}'列进行排序(升序)")
except Exception as e:
print(f"无法将'{date_column}'列转换为日期格式进行排序,原因:{str(e)}")
# 即使转换失败,仍尝试按原字符串排序
merged_df.sort_values(by=date_column, inplace=True)
print(f"已按'{date_column}'列进行原字符串排序(升序)")
else:
print(f"警告:数据中未找到名为'{date_column}'的列,跳过排序步骤")
# 6. 重置索引(可选,使索引从0开始连续)
merged_df.reset_index(drop=True, inplace=True)
# 7. 导出合并后的数据到新的CSV文件
output_path = os.path.join(current_dir, output_filename)
try:
merged_df.to_csv(output_path, index=False, encoding=encoding)
print(f"合并完成!结果已保存到:{output_path},总行数:{len(merged_df)},总列数:{len(merged_df.columns)}")
except Exception as e:
print(f"导出结果失败:{str(e)}")
if __name__ == "__main__":
"""
脚本主入口。
可根据需要修改以下参数:
- output_filename: 输出文件名
- date_column: 用于排序的日期列名
- encoding: 文件编码(若CSV文件是gbk编码,需修改为"gbk")
"""
merge_csv_files(
output_filename="merged_data.csv",
date_column="日期",
encoding="utf-8"
)示例二:代码解释
请逐行解释以下Python代码的功能和逻辑:
[粘贴代码]
要求:
1. 先用一段话概括这段代码的整体功能
2. 然后逐行/逐块解释关键逻辑
3. 指出代码中使用的设计模式或算法示例三:代码纠错
以下C++代码在运行时出现了死锁问题,请帮我排查:
[粘贴代码]
要求:
1. 指出可能导致死锁的具体位置
2. 解释死锁产生的原因
3. 给出修改后的代码
4. 说明如何避免类似问题示例四:学习新技术
我是Python初学者,想学习如何用Flask搭建一个简单的Web API。
请给我一个完整的示例项目
评论
0 条