5. 实时对话(Real-time)
功能介绍
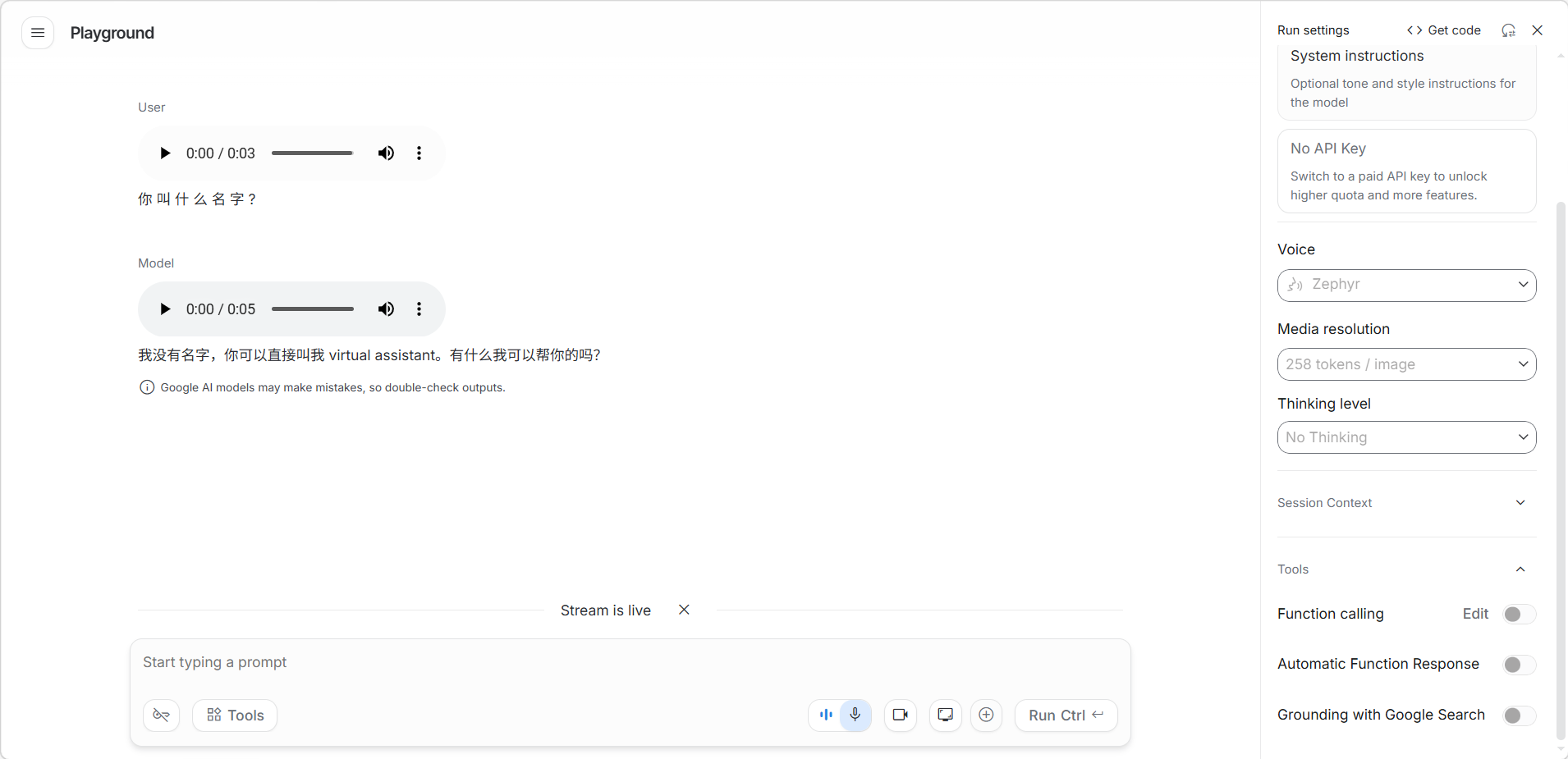
实时对话功能由 Gemini 3.1 Flash Live Preview 模型驱动,支持低延迟的音频到音频(audio-to-audio)实时交互。用户可以通过麦克风与 Gemini 进行实时语音对话,也可以分享屏幕或摄像头画面,让 Gemini 看到用户正在做什么并进行实时讨论。
当前可用模型:
这是 Google AI Studio 中体验感最强的功能之一,它让 AI 交互从"打字聊天"升级为"面对面对话",在声调识别、多模态理解方面表现突出。
使用方法
在 Playground 主页点击「Real-time(实时对话)」卡片。
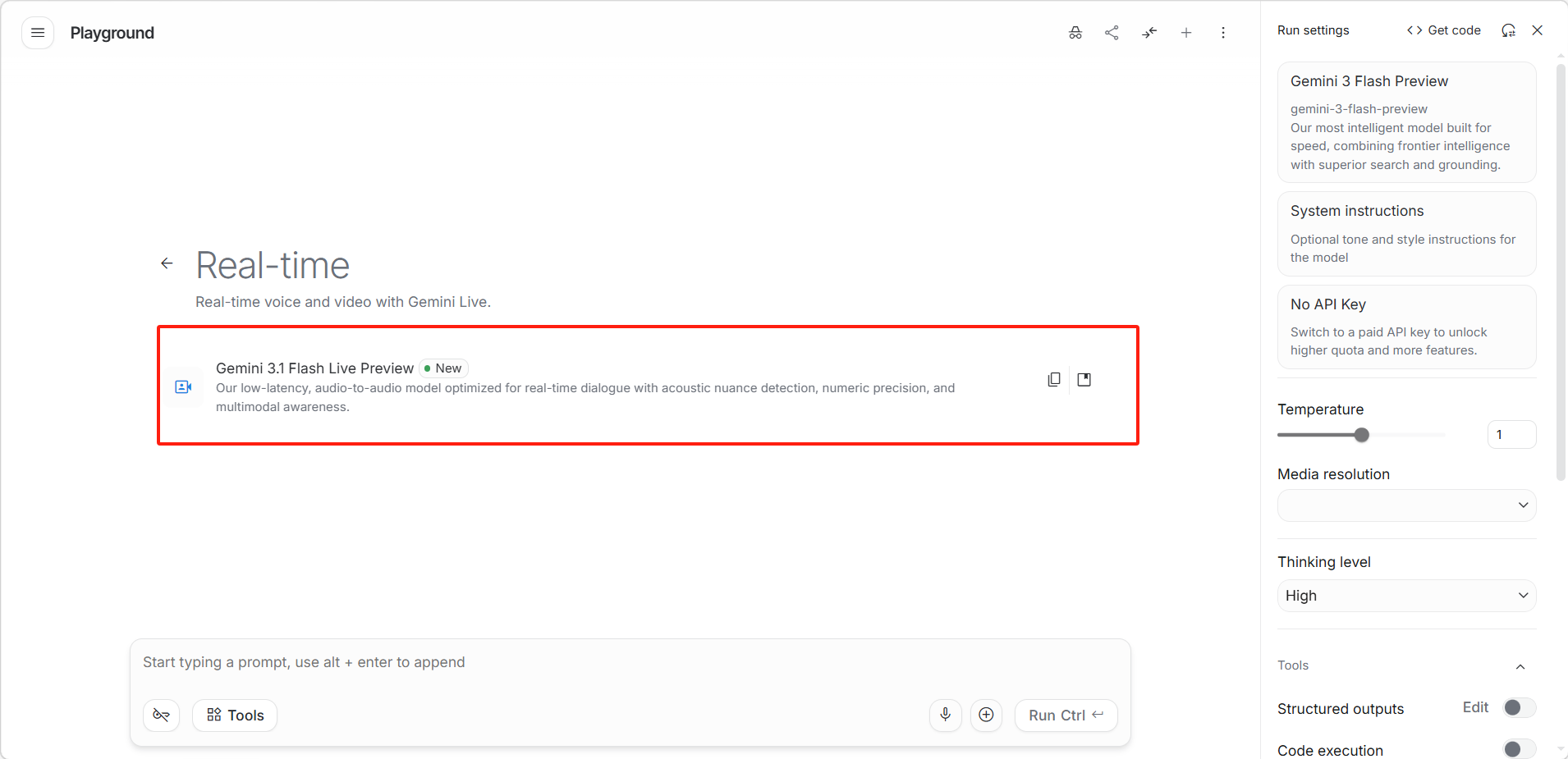
选择模型。
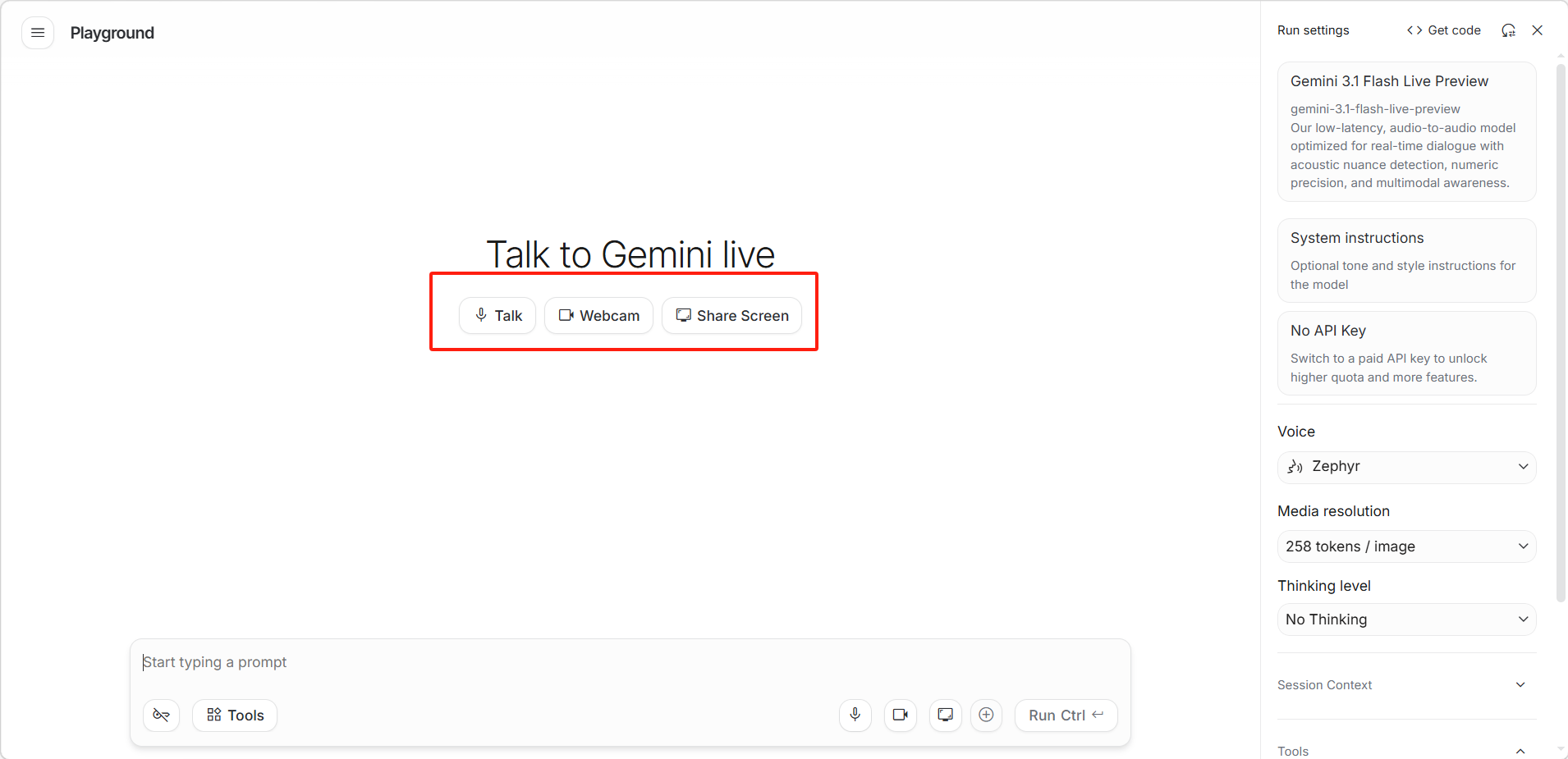
页面显示「Talk to Gemini live(与 Gemini 实时对话)」界面。
选择交互模式:
- 「 Talk(语音对话)」:仅通过麦克风进行语音交互
- 「 Webcam(摄像头)」:开启摄像头,让 Gemini 看到用户的画面并对话
- 「 Share Screen(分享屏幕)」:分享桌面画面,让 Gemini 看到用户的屏幕内容
点击任一模式按钮即可开始实时对话。
右侧设置面板(实时对话专属配置):
- 「System instructions(系统指令)」:设定对话中的行为和角色
- 「Voice(语音)」:下拉选择 AI 回复的音色
- 「Media resolution(媒体分辨率)」:下拉选择,默认 258 tokens / image
- 「Thinking level(思考级别)」:默认为 No Thinking(无思考),追求最低延迟
- 「Session Context(会话上下文)」:下拉展开,管理会话记忆范围
底部输入栏除文本输入外,还提供以下快捷按钮:
- 麦克风按钮:开启语音输入
- 摄像头按钮:开启摄像头
- 屏幕分享按钮:分享桌面
提示:实时对话模式默认将思考级别设为 No Thinking,以确保最低的响应延迟。如果用户需要更深度的推理分析,可以切换回普通对话模式使用 Gemini 3.1 Pro。
核心能力
- 实时语音对话:低延迟的双向语音交流
- 屏幕分享:分享用户的桌面,让 AI 看到用户正在操作的内容
- 摄像头接入:通过摄像头展示实物,让 AI 识别并给出建议
- 打断与自然对话:支持随时打断 AI 的回答,进行自然的对话交互
使用技巧
- 确保在安静的环境中使用,减少背景噪音干扰
- 说话时尽量清晰,使用完整句子效果更好
- 屏幕分享时,Gemini 可以帮用户分析代码、文档或界面设计
- 摄像头模式适合识别植物、产品、食物等实物
应用场景
示例
示例一:语言学习
示例二:屏幕分享调试
示例三:摄像头识别
示例四:烹饪指导
示例五:即兴演讲练习
评论
0 条