4. 语音与音乐生成(Text to Speech and Music)
功能介绍
Google AI Studio 提供了语音合成(TTS)和音乐生成两大音频能力。语音方面由 Gemini 2.5 Pro Preview TTS 模型驱动,支持高自然度的文本转语音;音乐方面由 Lyria 3 系列模型驱动,可以根据文字描述生成完整的音乐作品。
当前可用模型:
开启方式
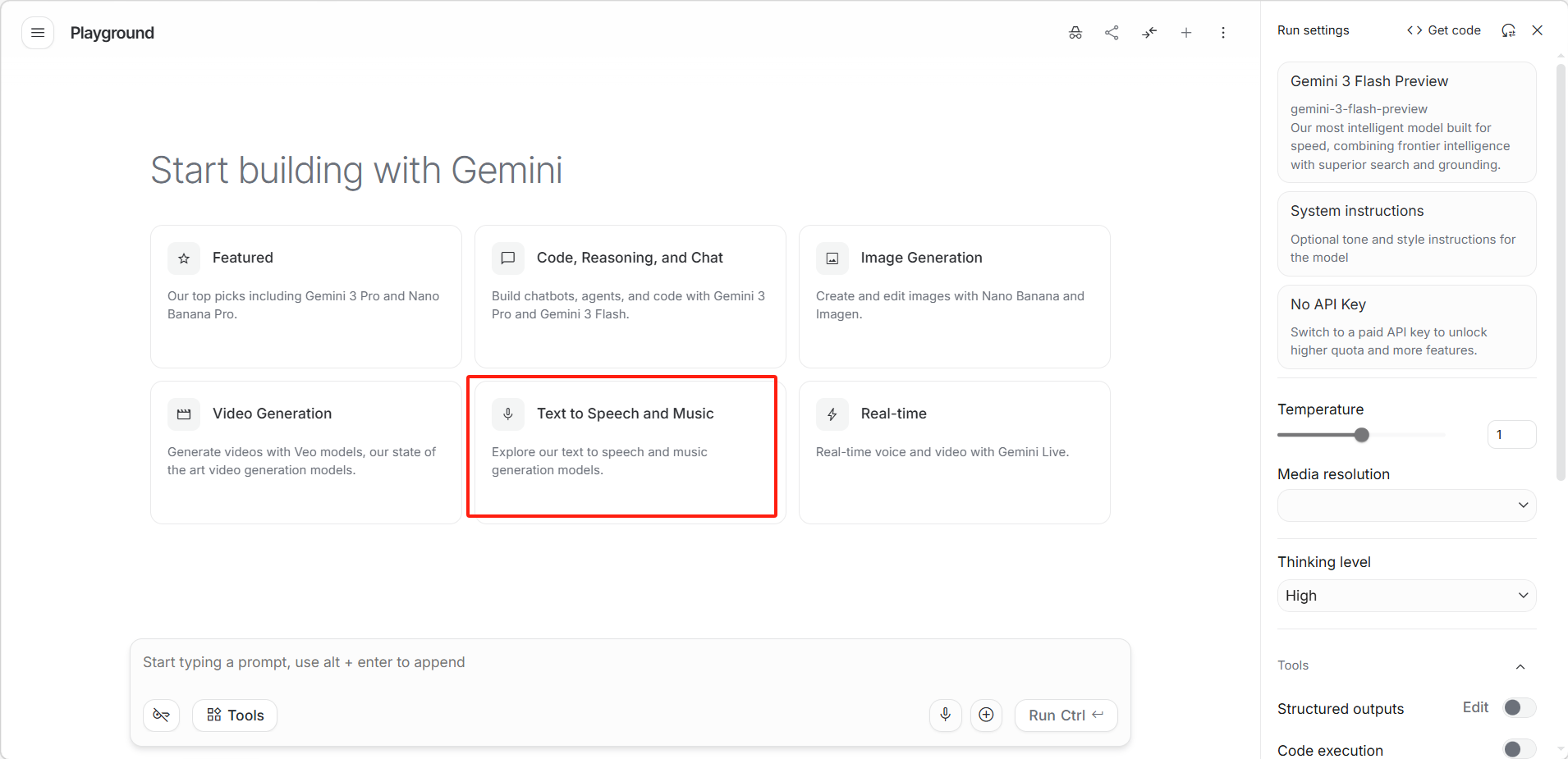
在 Playground 主页点击「Text to Speech and Music(语音与音乐)」卡片
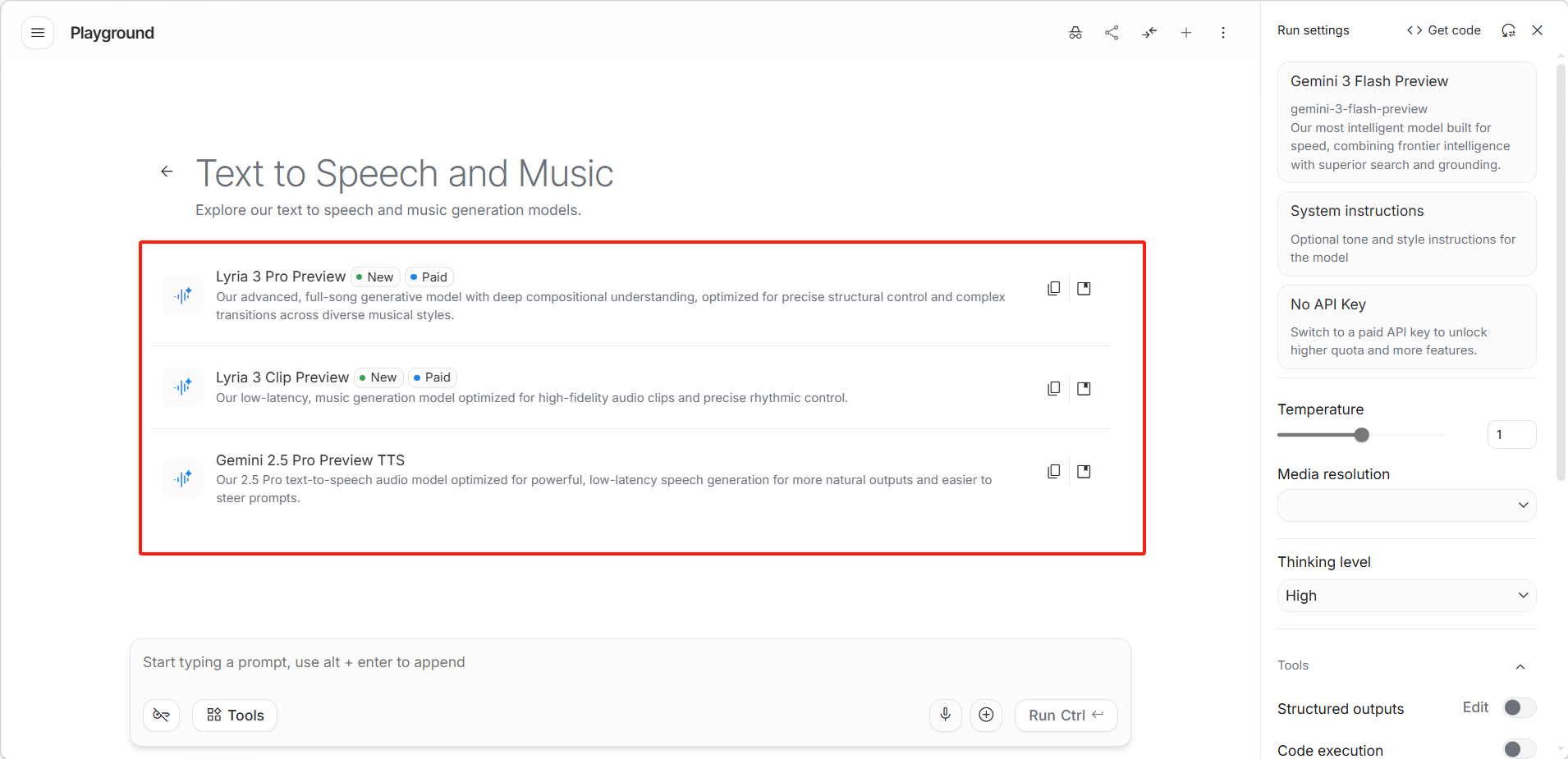
从模型列表中选择目标模型后即可开始对话。
语音模型使用方法
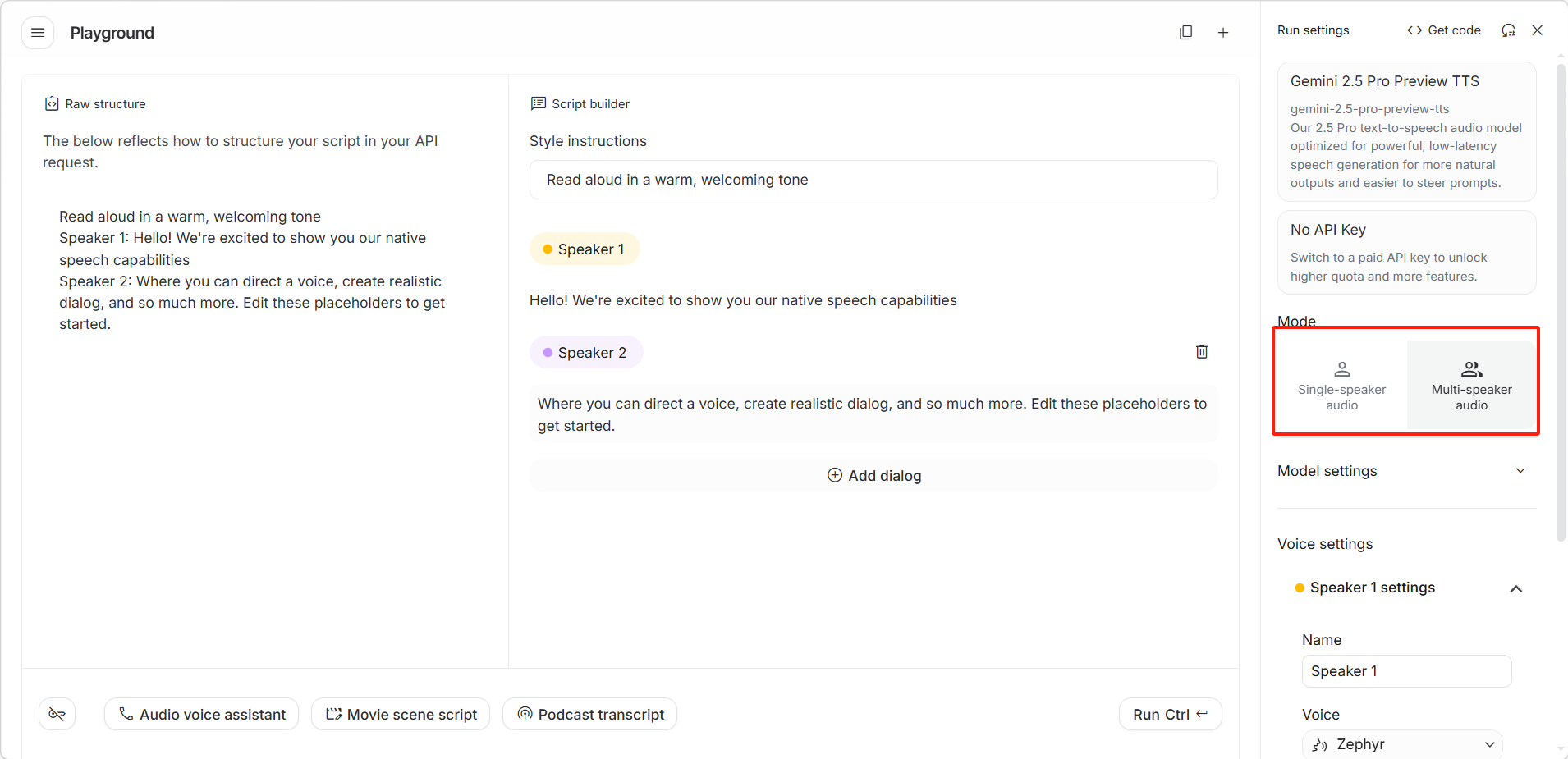
界面右边角提供两种音频模式切换:
- 「Single-speaker audio(单人语音)」:适合朗读、旁白等单一角色场景
- 「Multi-speaker audio(多人语音)」:适合对话、播客、有声剧等多角色场景
多人语音模式(Multi-speaker audio)的详细配置:
主界面
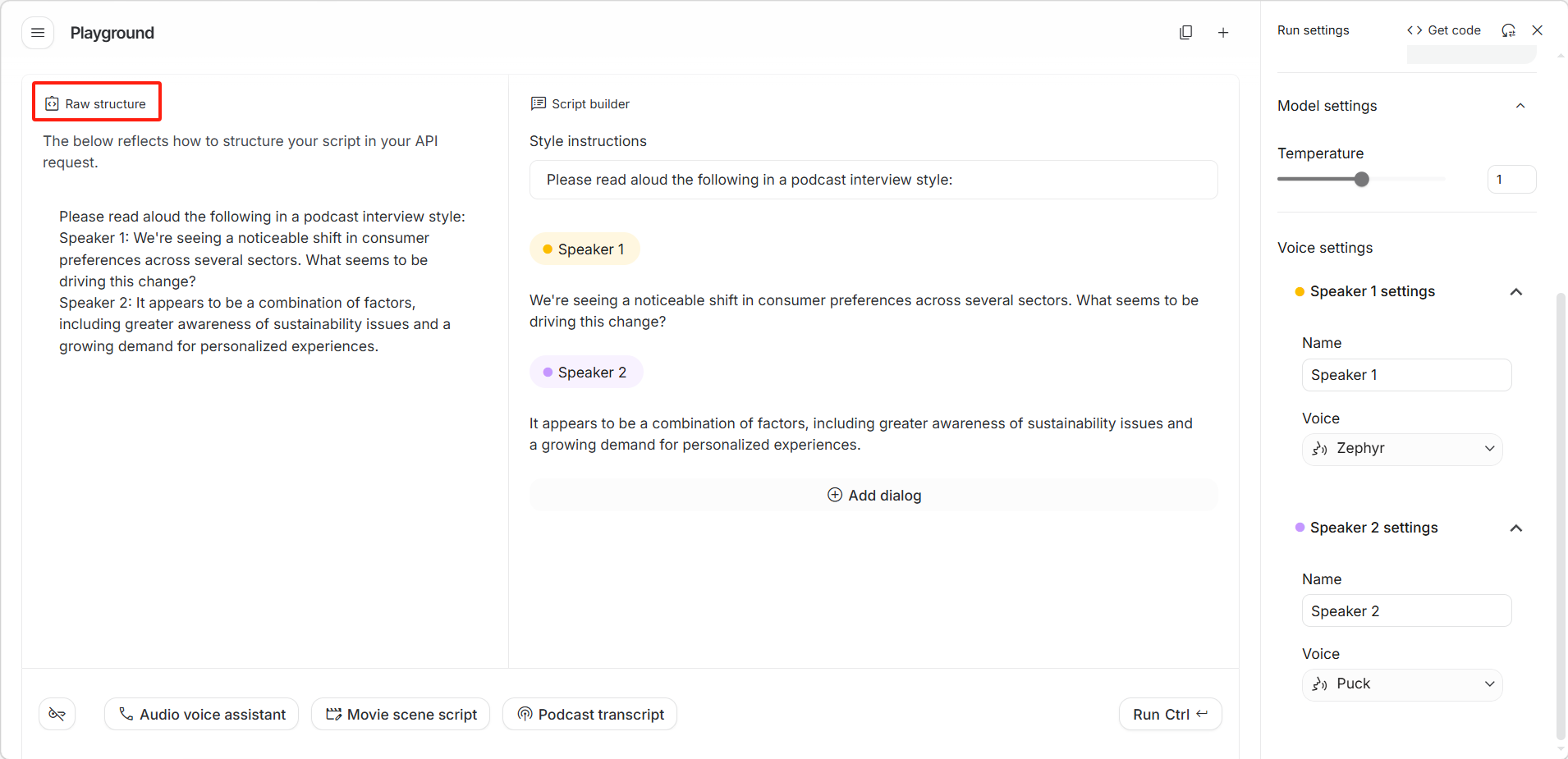
界面分为左右两栏。左侧「Raw structure(原始结构)」展示 API 请求的原始文本格式。
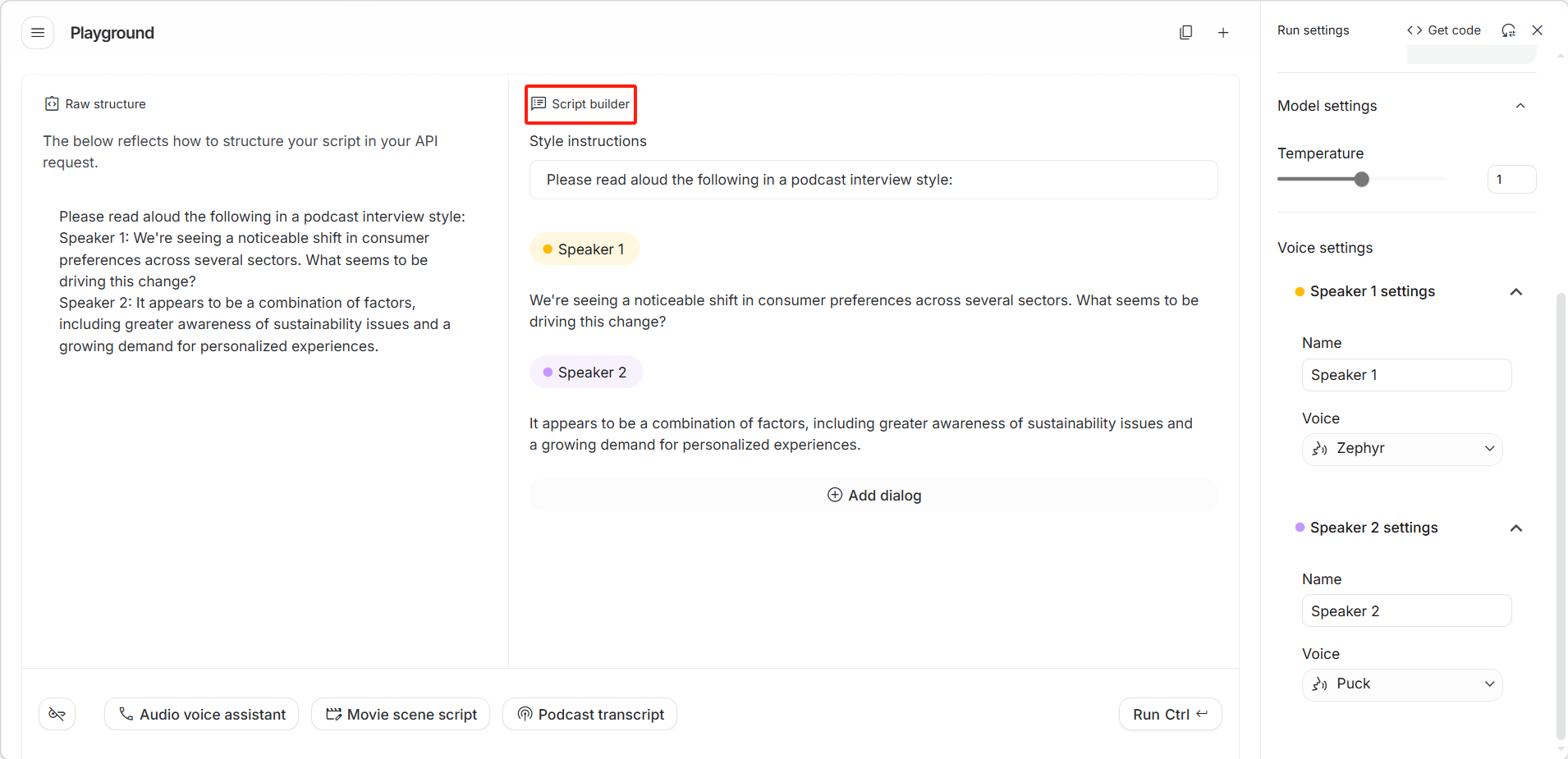
右侧「Script builder(脚本构建器)」提供可视化编辑界,拥有以下选项:
- 「Style instructions(风格指令)」:文本框,输入整体朗读风格(如 "Read aloud in a warm, welcoming tone")
- 「Speaker 1(说话人 1)」/ 「Speaker 2(说话人 2)」等角色标签:点击可编辑该角色的台词
- 「 Add dialog(添加对话)」:点击可添加更多对话轮次
底部快捷模板按钮:
- 「Podcast transcript(播客文稿)」:预设播客对话格式
- 「Movie scene script(电影场景脚本)」:预设影视对话格式
- 「Audio voice assistant(语音助手)」:预设语音助手对话格式
右侧设置面板
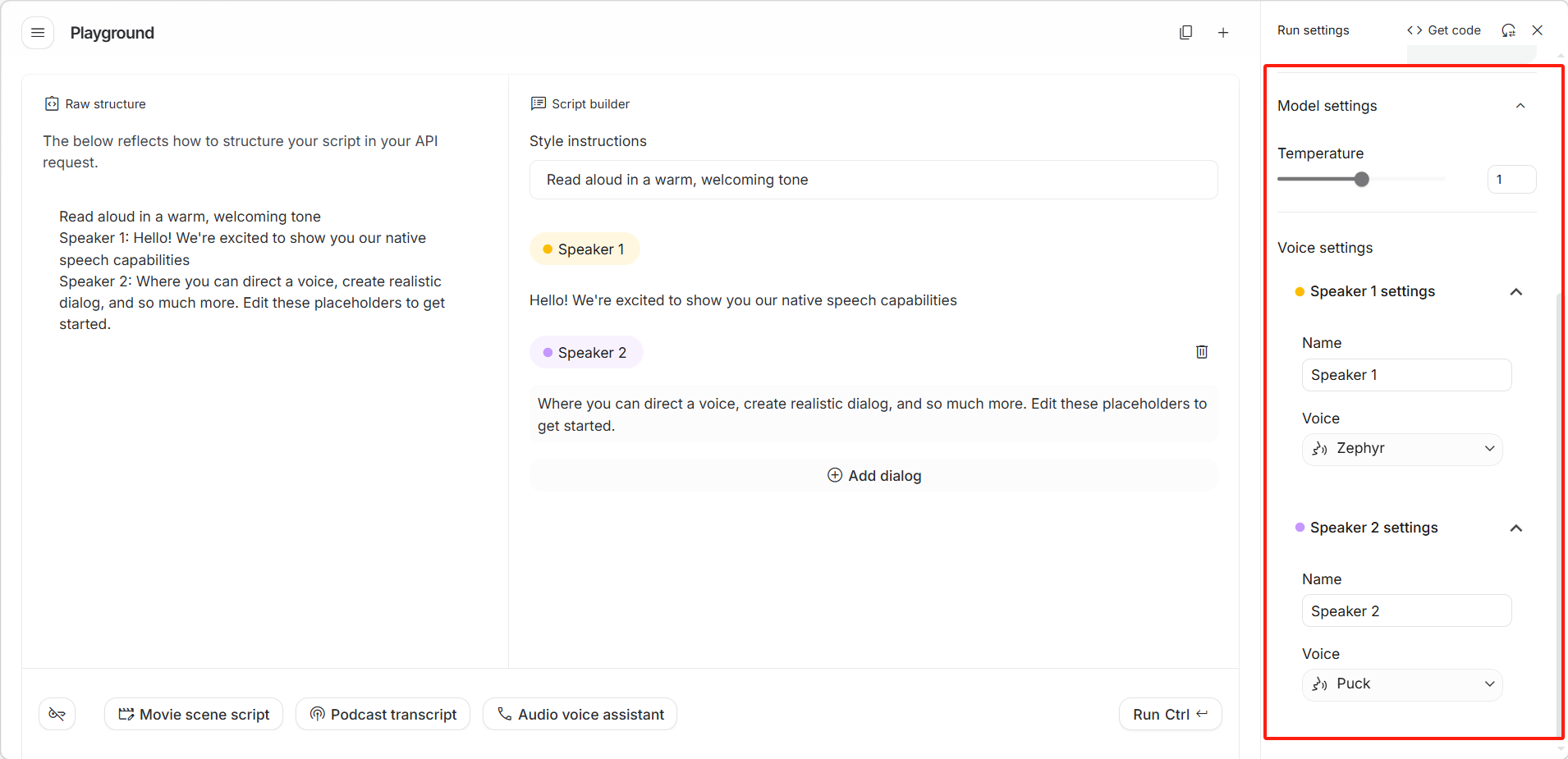
- 「Temperature (温度)」:通过滑块控制输出结果的随机性与创造力水平。
- 「Name (名称)」:为发言人自定义一个在文稿中显示的识别名称。
- 「Voice (语音)」:从下拉列表中选择具体的音色模型(如 Zephyr 或 Puck)。
生成对话
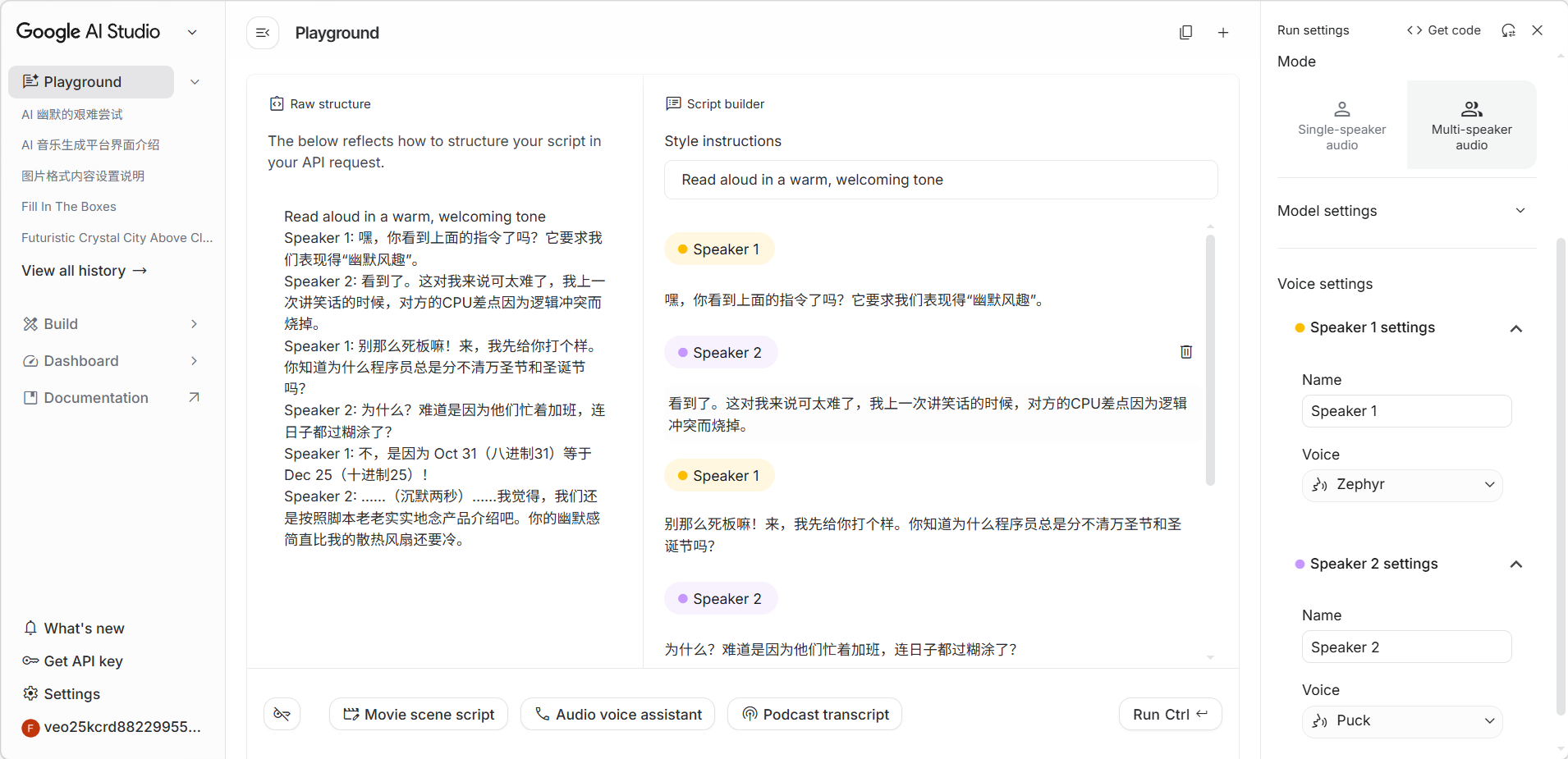
设置好参数后,输入对话的内容即可开始生成。
生成效果展示。
音乐模型使用方法
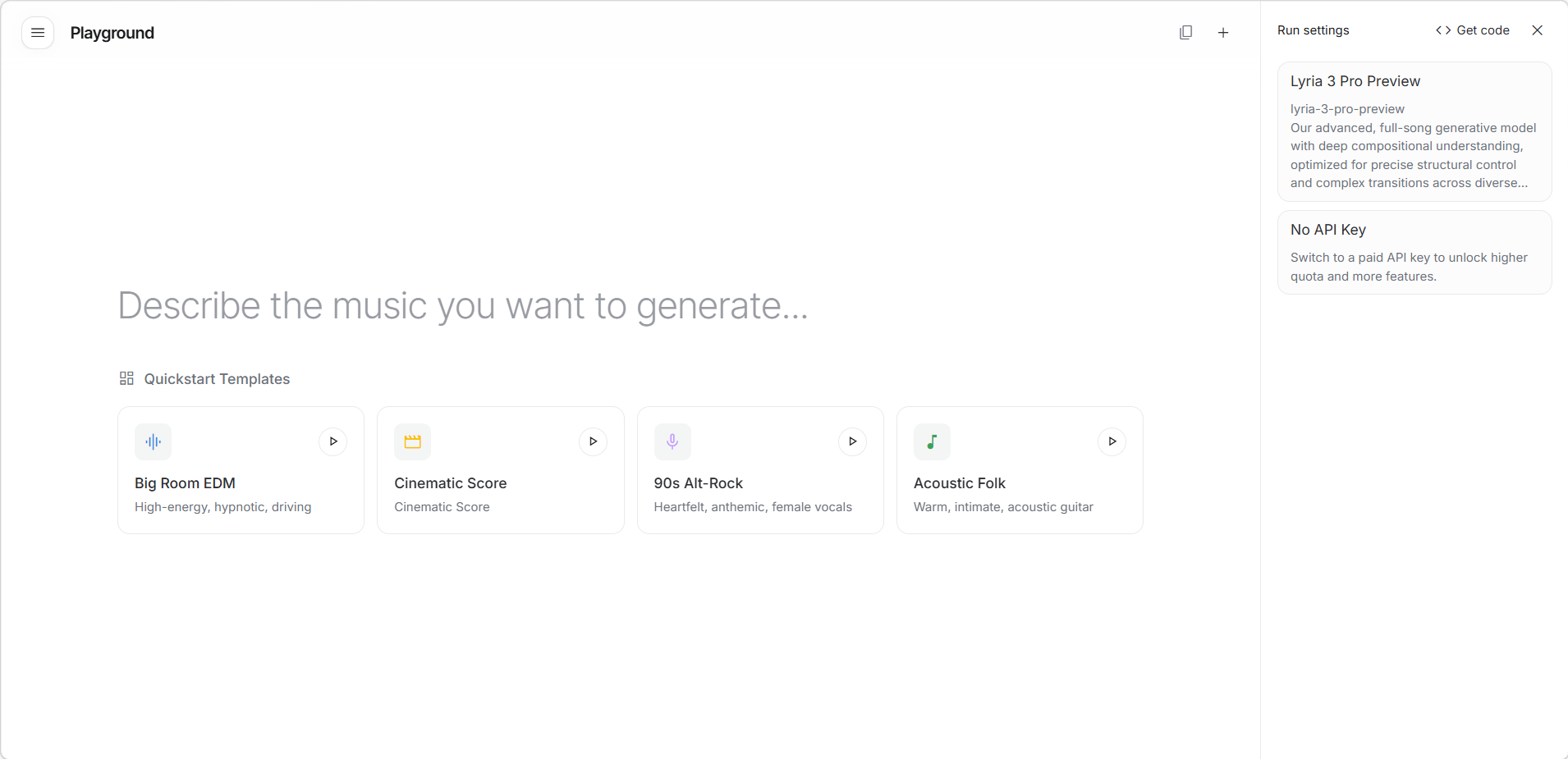
在中央输入框中用文字描述你想要的音乐风格或情绪即可生成音乐,也可以直接点击下方的“快速启动模板”体验预设流派。
核心能力
语音合成(TTS):
- 将文本转换为自然流畅的语音
- 支持多种语言和口音
- 可通过提示词控制语速、情绪和朗读风格
- 适用于有声读物、播客、视频配音等场景
音乐生成:
- 根据文字描述生成原创音乐
- 支持多种音乐风格和流派
- Lyria 3 Pro 支持全曲结构(前奏、主歌、副歌、桥段等)
- Lyria 3 Clip 适合快速生成短音乐片段
使用技巧
- 语音生成时,在提示词中描述期望的语气和风格效果更好
- 音乐生成建议指定风格、乐器、节奏和情绪
- 可以先用 Lyria 3 Clip 快速试听效果,满意后用 Lyria 3 Pro 生成完整曲目
- 在描述中加入具体的音乐术语(如 BPM、调式)可以获得更精确的控制
音乐风格参考
示例
示例一:文本转语音
示例二:背景音乐生成
示例三:电影配乐
示例四:流行歌曲
示例五:播客节目开场
评论
0 条