4. 数字人
功能介绍
数字人功能可以让用户上传一张角色图片和一段音频(或直接输入文字),即可生成角色"开口说话"的视频。数字人功能基于 OmniHuman 模型,能够实现嘴部、面部表情和身体动作的自然协调,适用于演讲、对白、短视频口播等场景。
使用方法
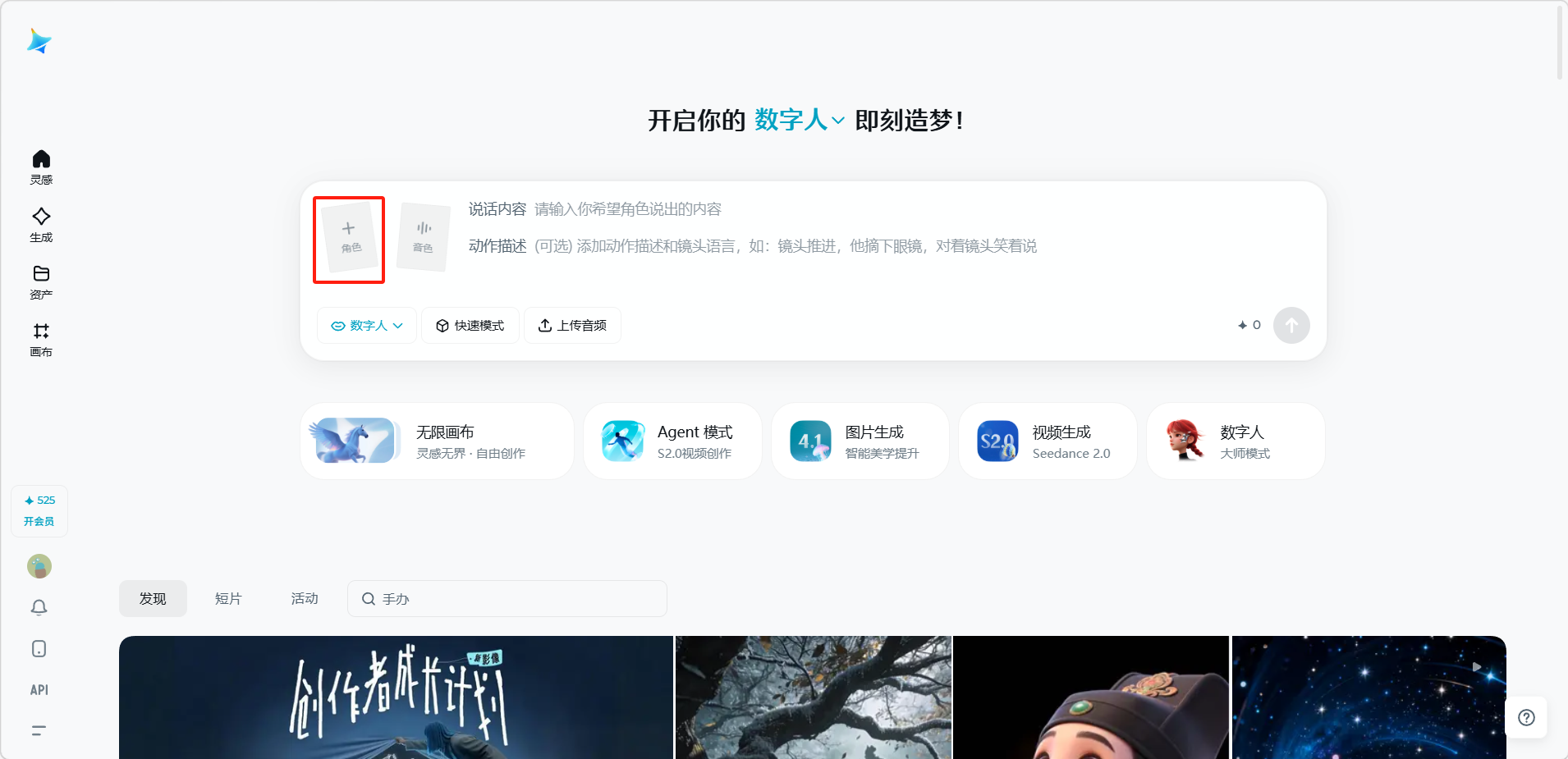
上传角色图片(点击「+ 角色」按钮)。
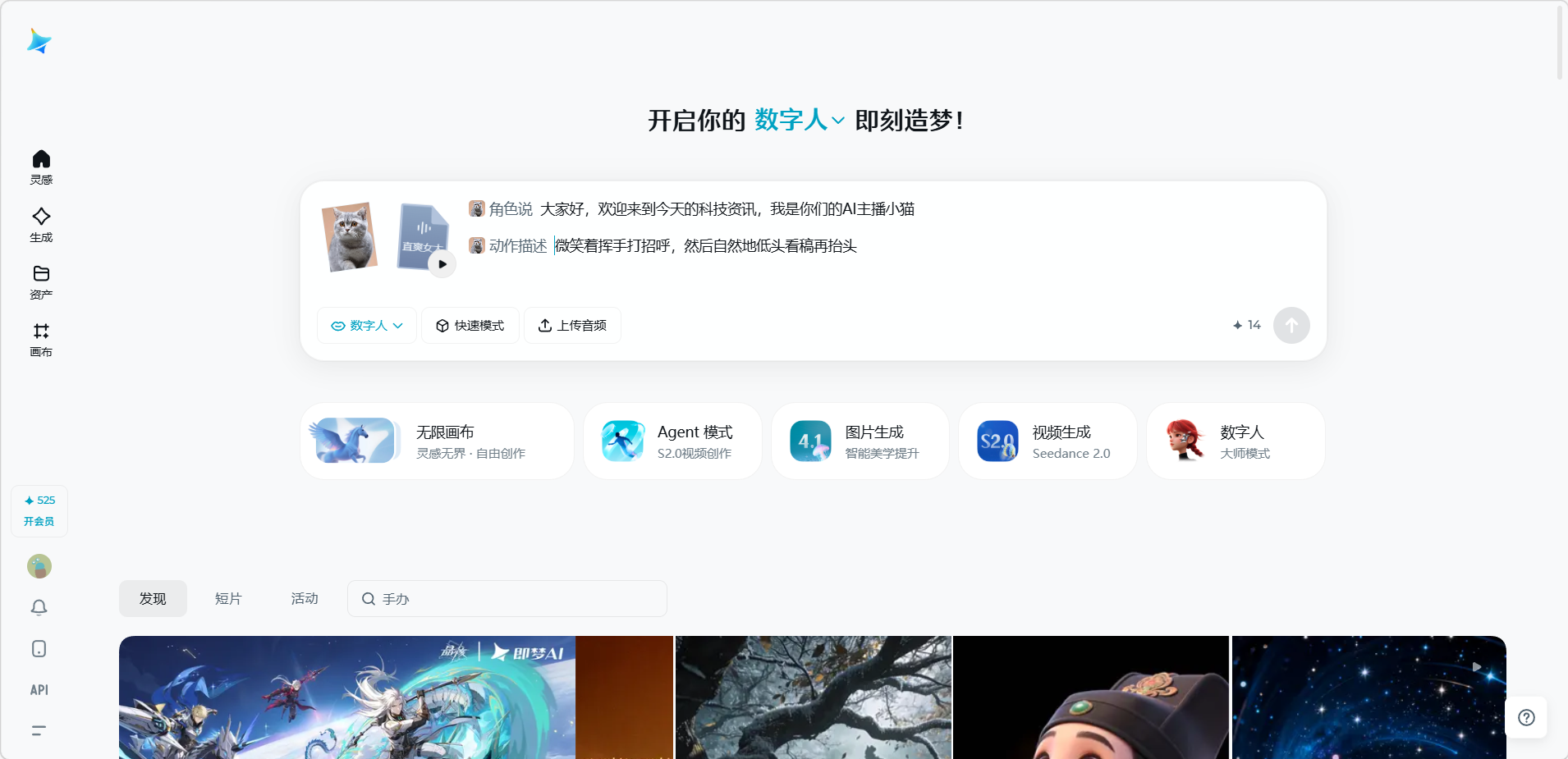
输入说话内容,或点击「上传音频」上传本地录音。然后添加动作描述(可选)。
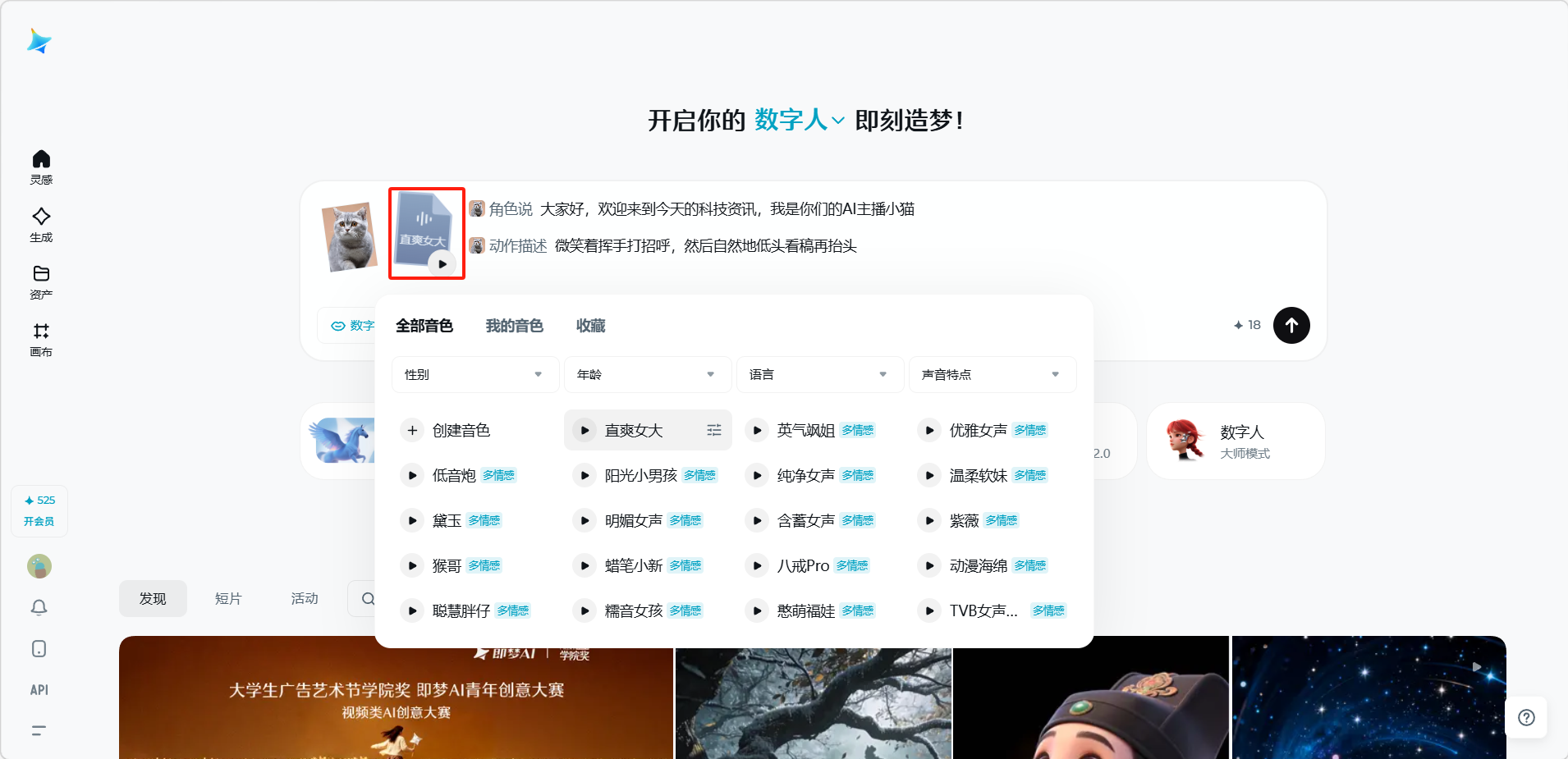
选择音色和语速(如果使用文字输入方式)。
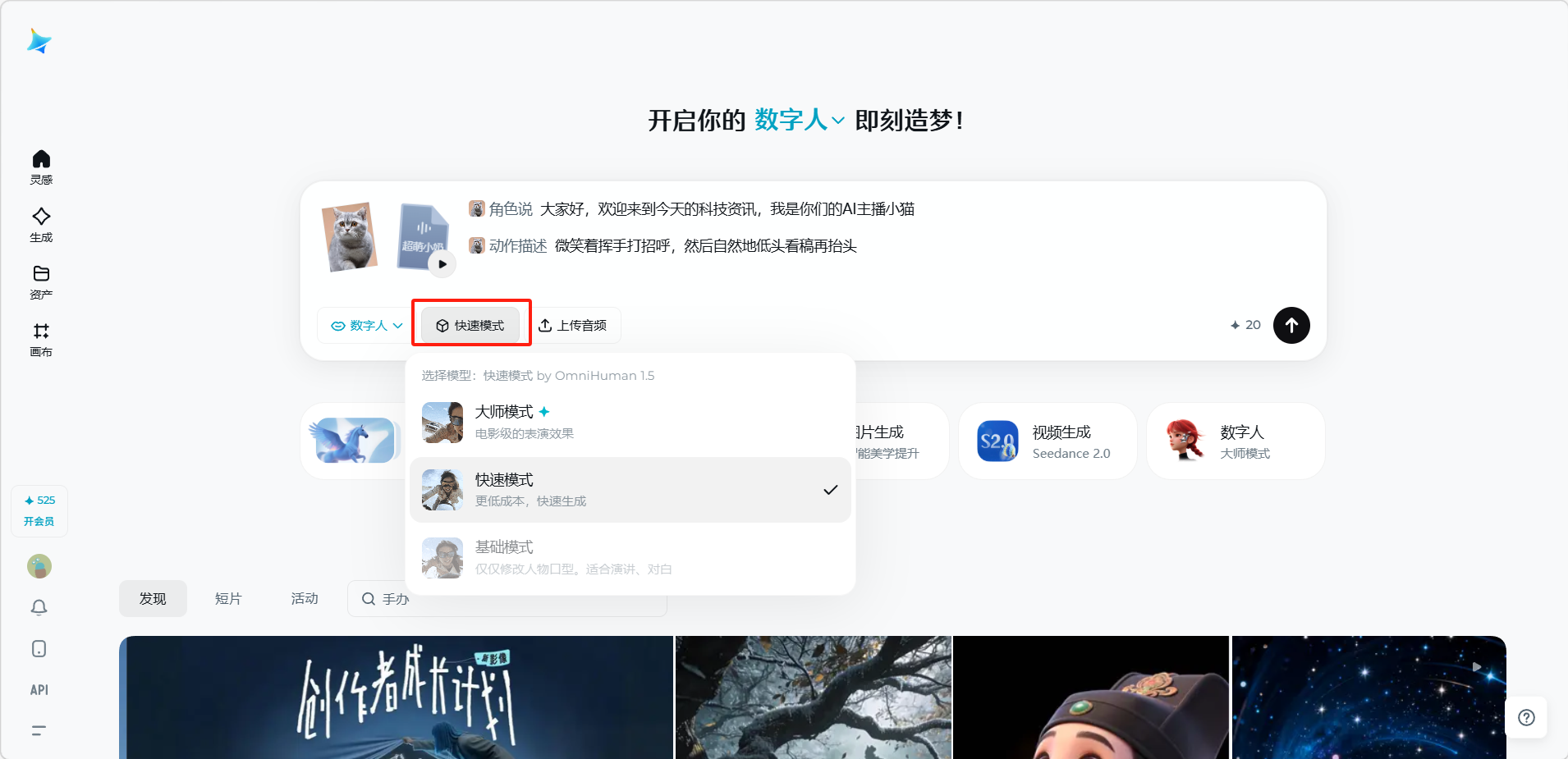
选择模式,点击发送按钮开始生成。
生成效果展示。
模式对比
使用技巧
- 上传的角色图片建议选择正面或微侧面的清晰照片,面部占比适中
- 大师模式的生成效果最好,但积分消耗也最高,建议先用快速模式预览效果
- 根据字数的不同,消耗的积分也不同,大约2字/积分(大师模式约3字消耗8积分)
- 动作描述虽然是可选项,但加上后可以让视频更生动(如"镜头推进""摘下眼镜""对着镜头笑着说")
注意事项
- 数字人功能支持克隆自己的声音,但需要完成声音采集流程
- 大师模式仅赠送一次免费试用机会,之后需要消耗积分
- 基础模式只会修改口型,不会产生额外的面部表情和身体动作
示例一
示例二
示例三
示例四
示例五
评论
0 条