4. 语音体验中心
「语音体验中心」是阶跃星辰专为语音交互场景打造的综合功能区,集成了语音通话、语音识别、语音合成等多种语音相关能力。点击主界面输入框下方的「语音体验中心」入口即可进入能够满足日常沟通、内容创作、学习辅助等多元需求。
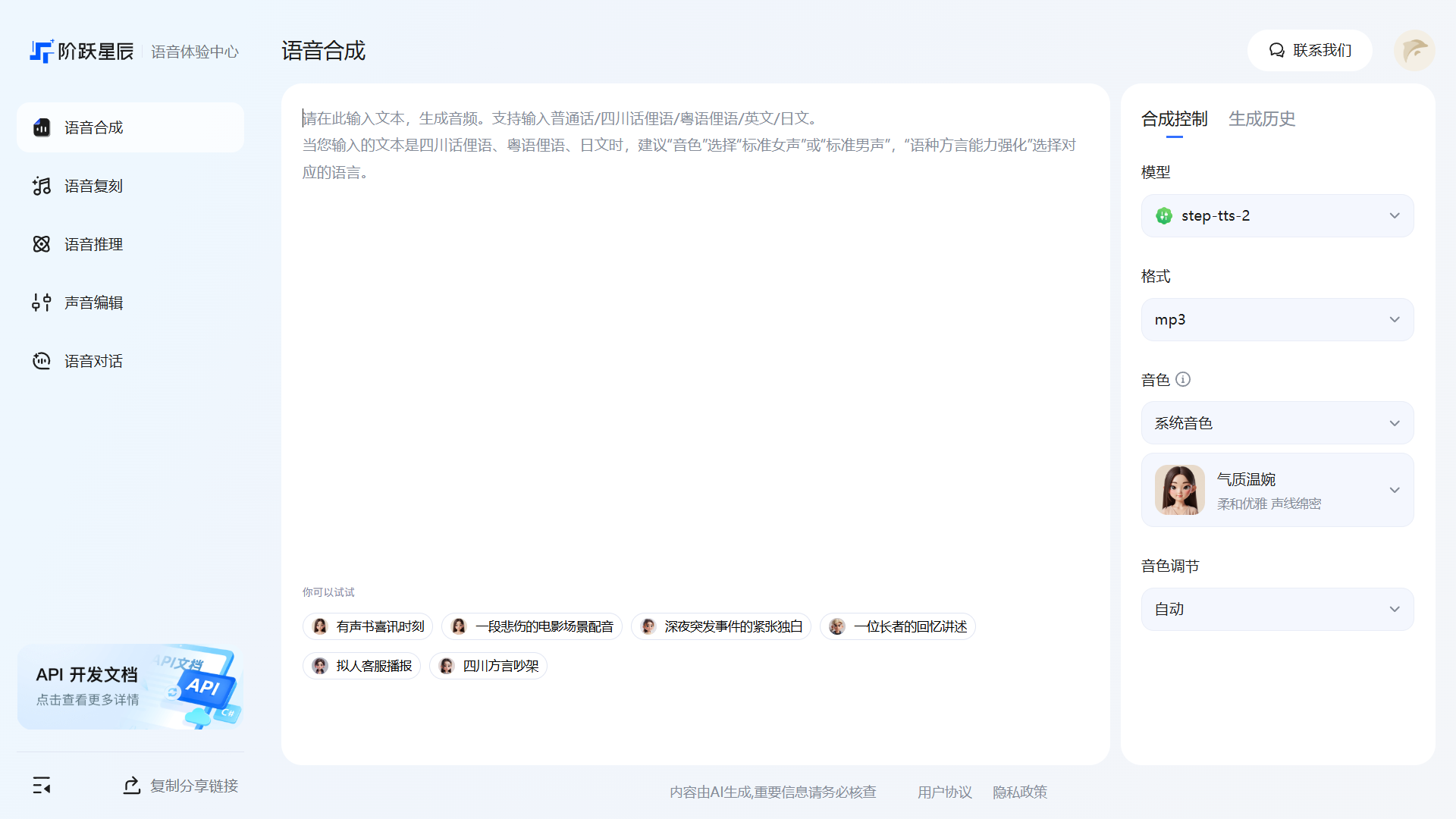
进入后,左侧边栏提供五大子功能入口:语音合成、语音复刻、语音推理、声音编辑、语音对话。
语音合成
语音合成支持将文字内容转换为自然流畅的音频文件。
支持的语言:普通话、四川话俚语、粤语俚语、英文、日文
右侧控制面板说明:
- 模型:默认使用
step-tts-2,阶跃星辰自研语音合成模型 - 格式:输出音频格式,默认 mp3
- 音色:可选择系统音色或自定义克隆音色,内置多种风格(如「气质温婉」「沉稳男声」等)
- 音色调节:默认「自动」,可手动调整语速、语调等参数
适用场景示例:
输出结果如下:
***此处插入音频yyhc-jyxc.mp3
提示:语音合成每天有50次免费额度。
语音复刻
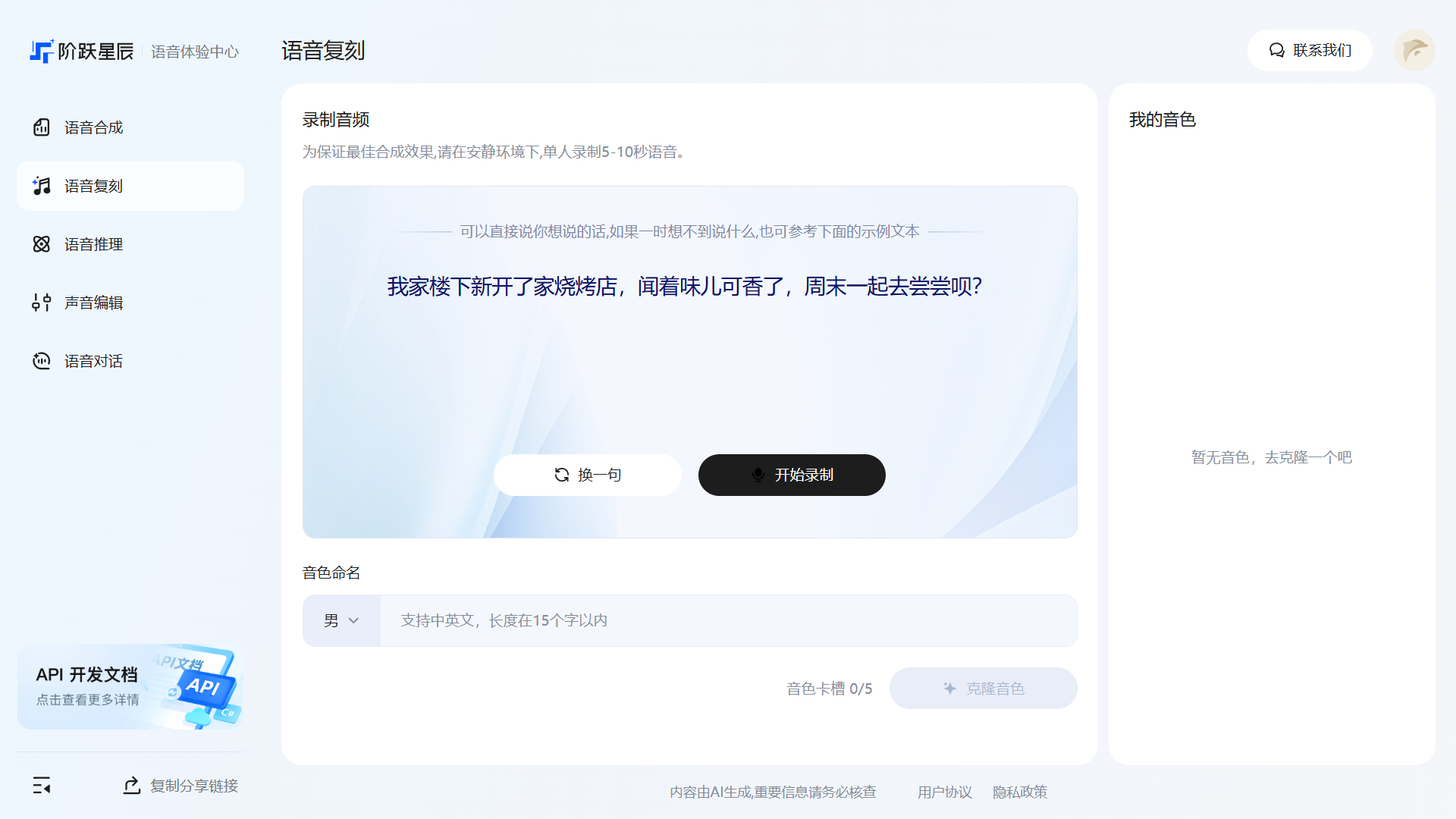
「语音复刻」支持录制用户的声音样本,AI 会学习声音特征,生成一个专属的克隆音色。
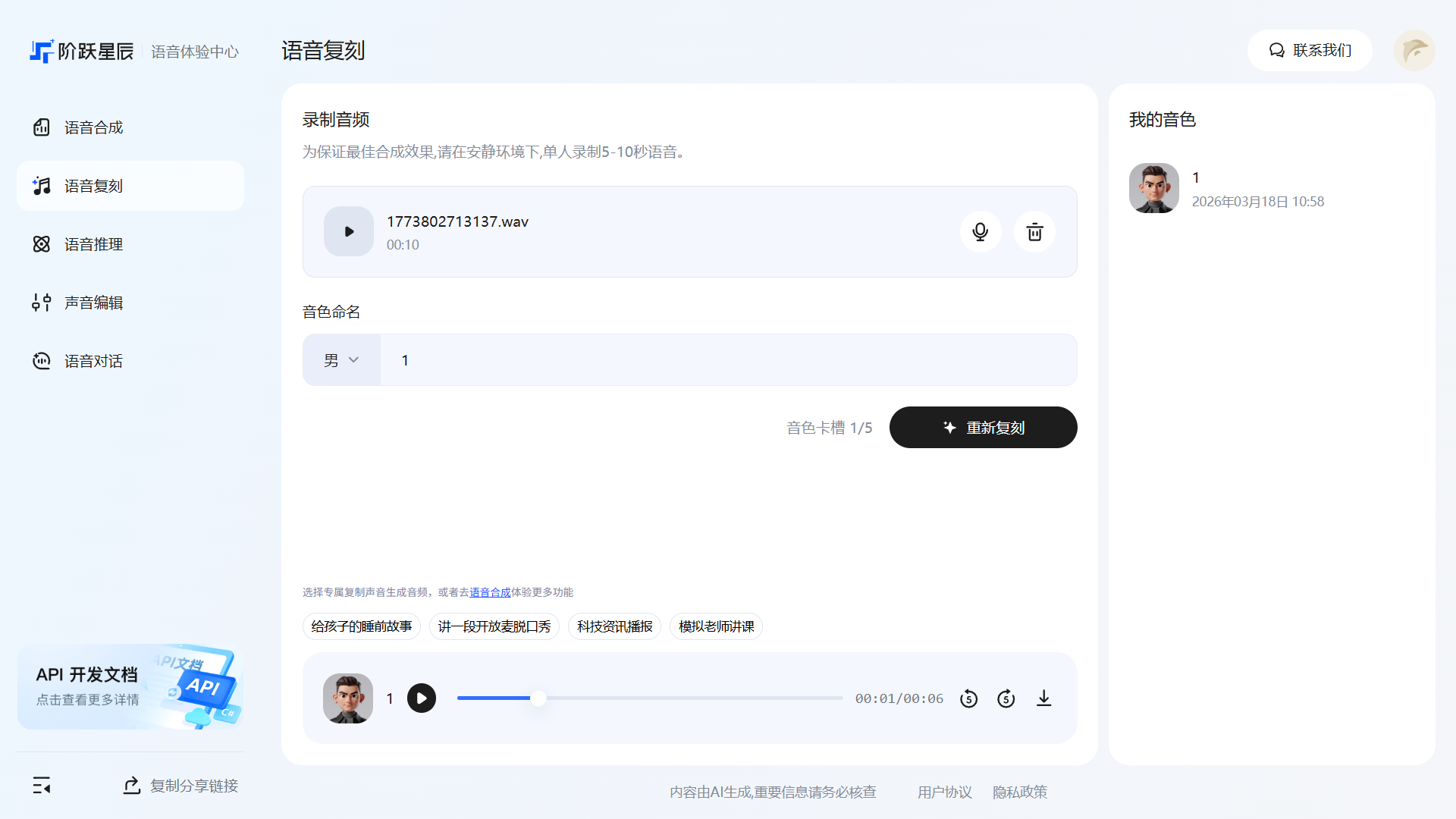
克隆完成后,该音色会出现在语音合成的音色选择列表中,可以直接用于后续的文字转语音任务——让 AI 用你自己的声音来朗读内容。
适用场景:个人播客配音、视频博主批量配音、个性化语音提醒等。
提示:复刻的声音最多能保存5个。
语音推理
「语音推理」支持直接输入语音或上传音频文件,让 AI 对语音内容进行理解和推理分析。相较于普通语音识别(只做转写),语音推理会在理解语音内容的基础上进一步给出分析、判断或回答。
适用场景示例:
输出结果如下:
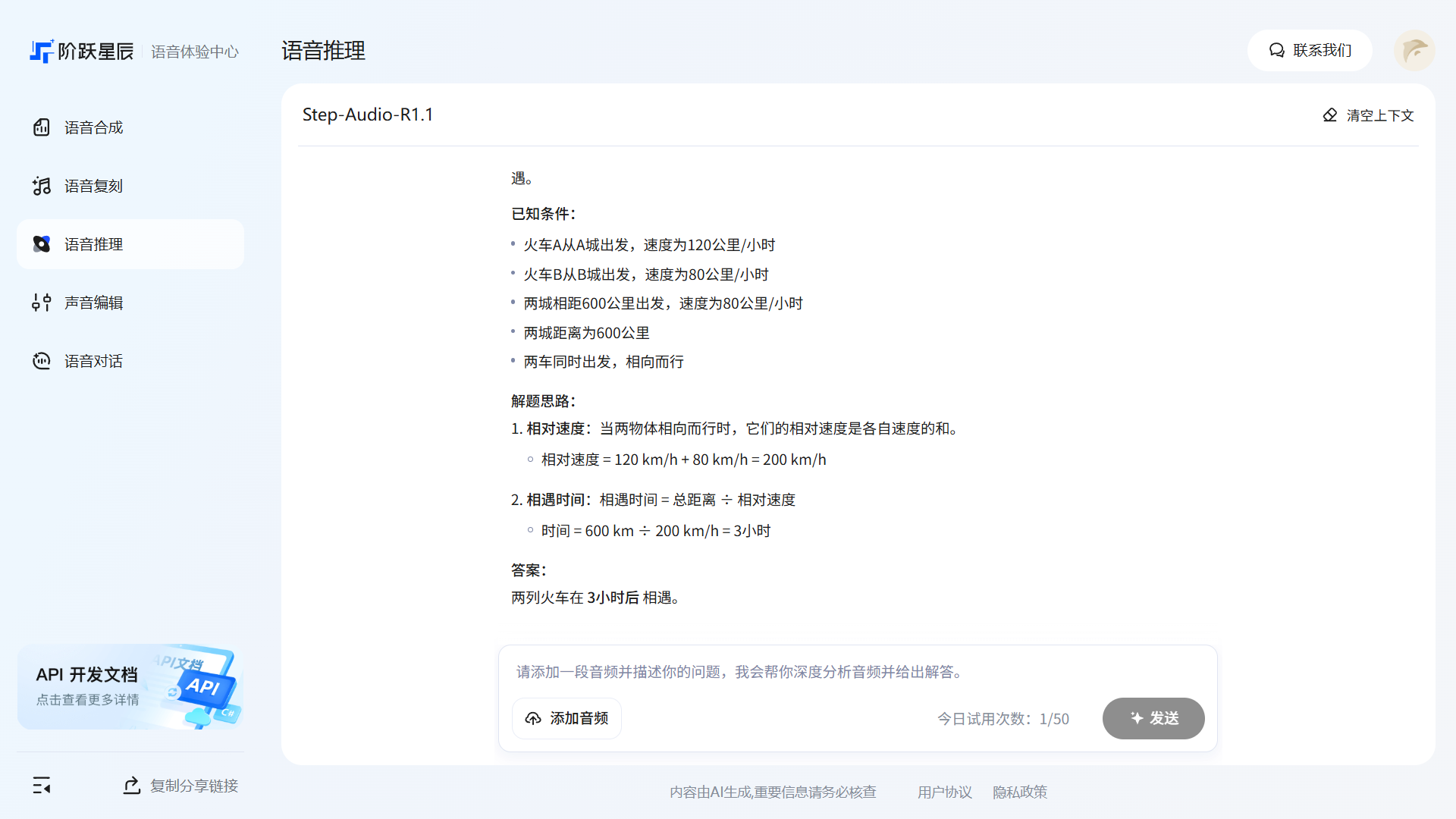
提示:语音推理每天有50次试用次数,上传和录制的音频需小于240秒。
声音编辑
「声音编辑」提供对已生成或上传音频的二次加工能力,支持调整情绪、风格、速度,以及添加副语言效果。
操作流程:
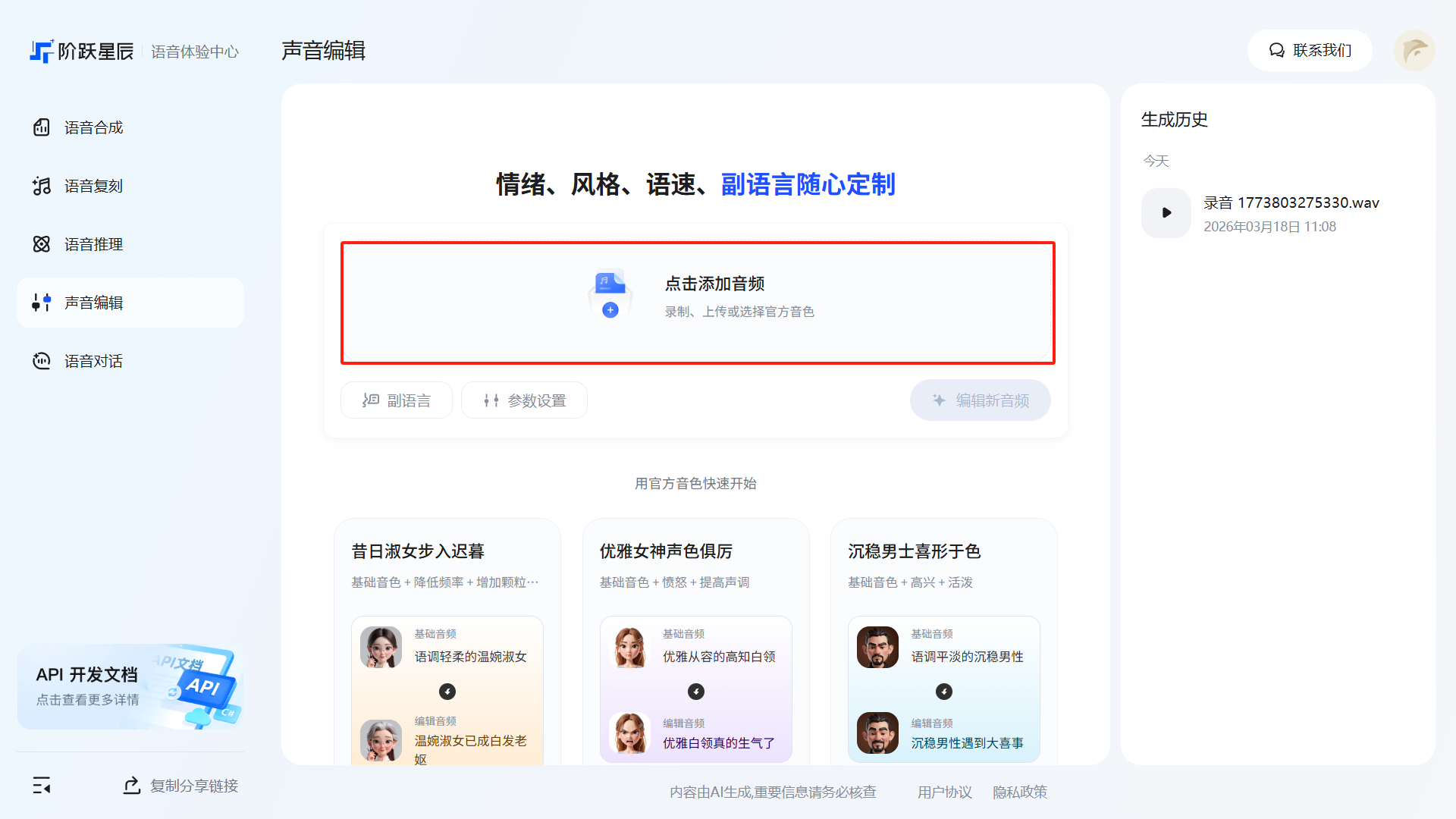
点击添加音频。
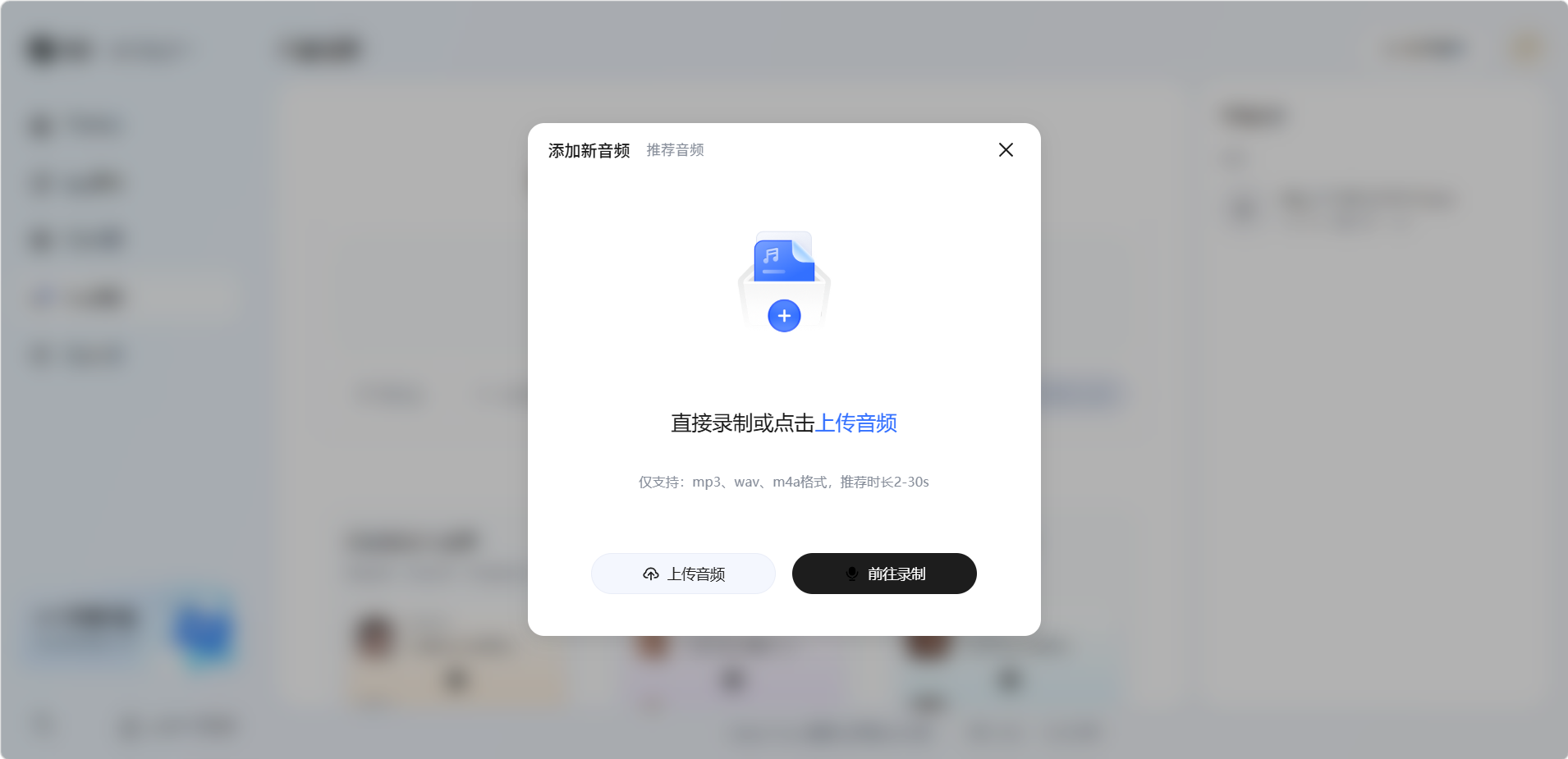
上传或录制音频。
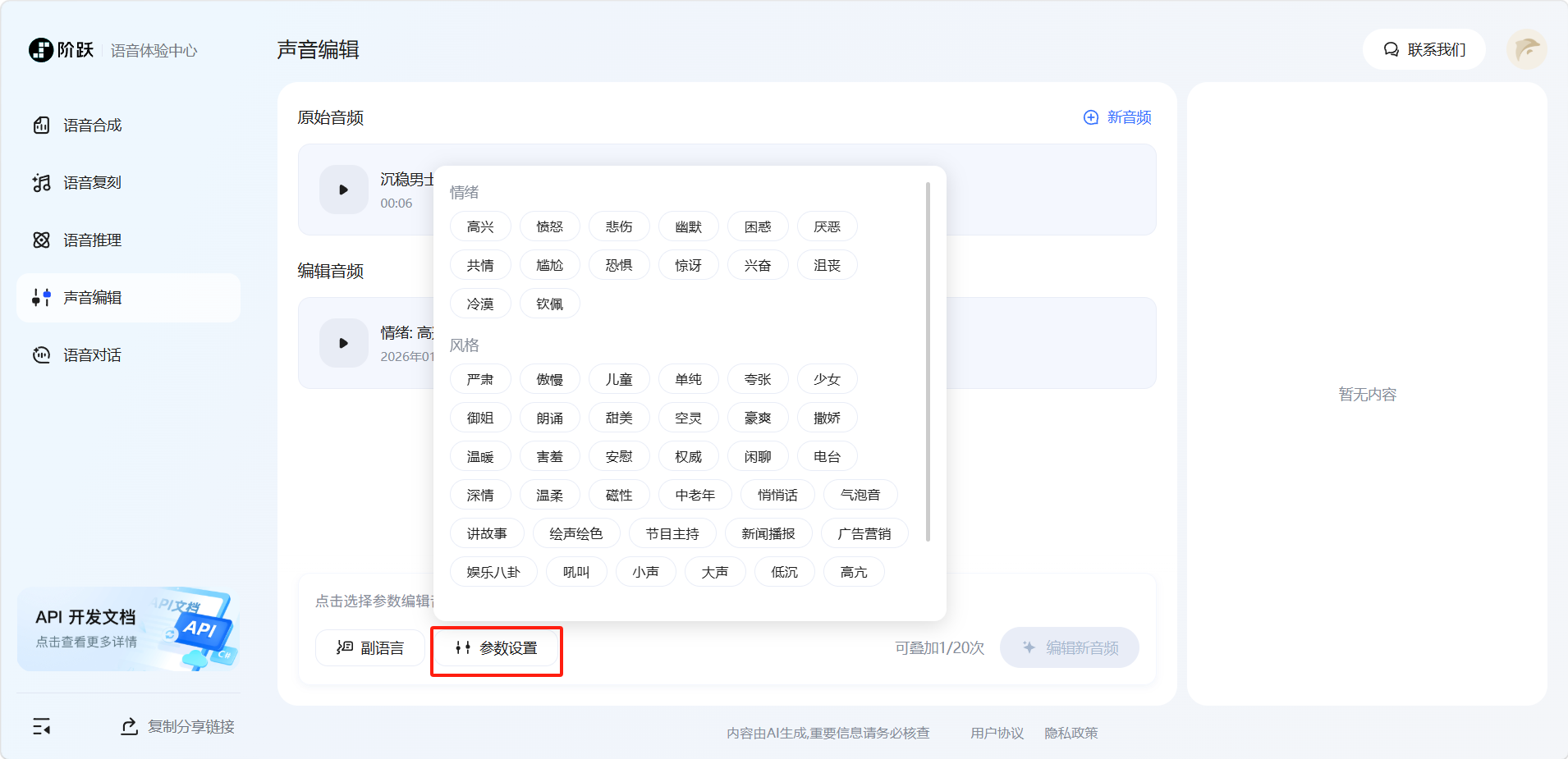
点击左下角选择参数,共有三个分类可以选择,情绪、风格、速度控制。(一次只能选择一个分类,需要等编辑完成后才能选择另一个分类),选择完成后点击「编辑新音频」。
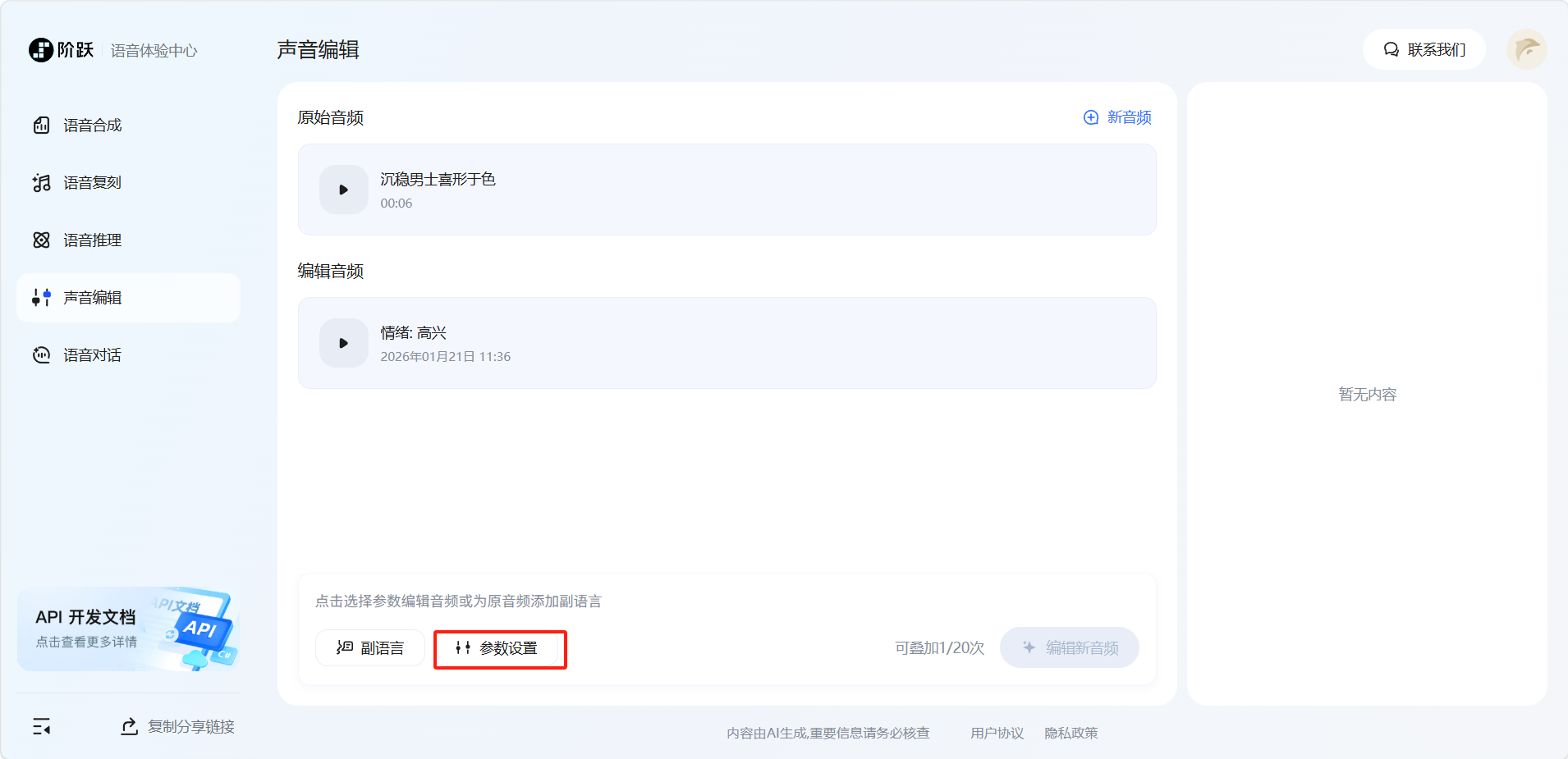
编辑完成后可以再次点击选择参数再次编辑。
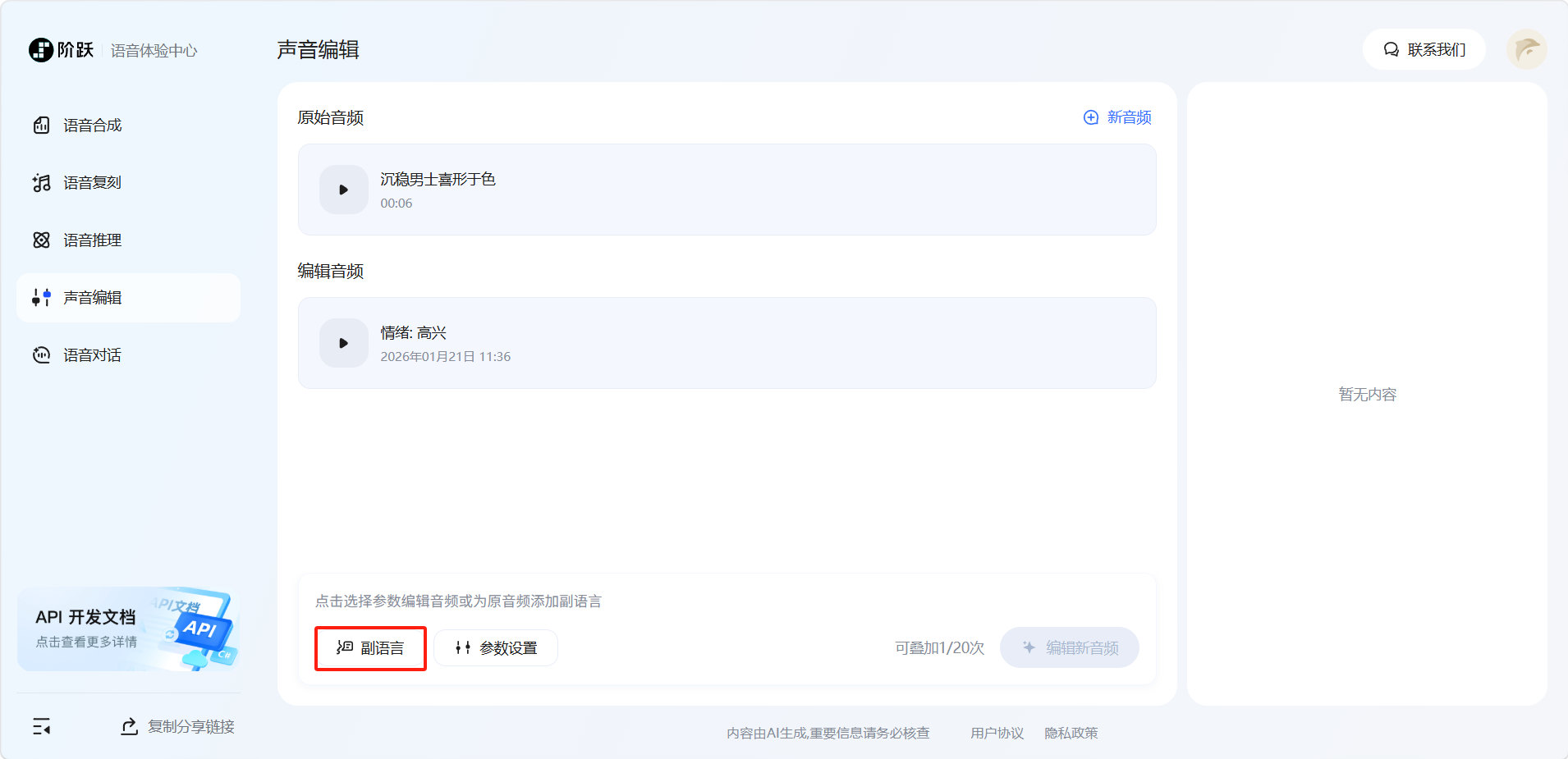
用户还可以点击左下角「副语言」按钮为音频添加副语言。
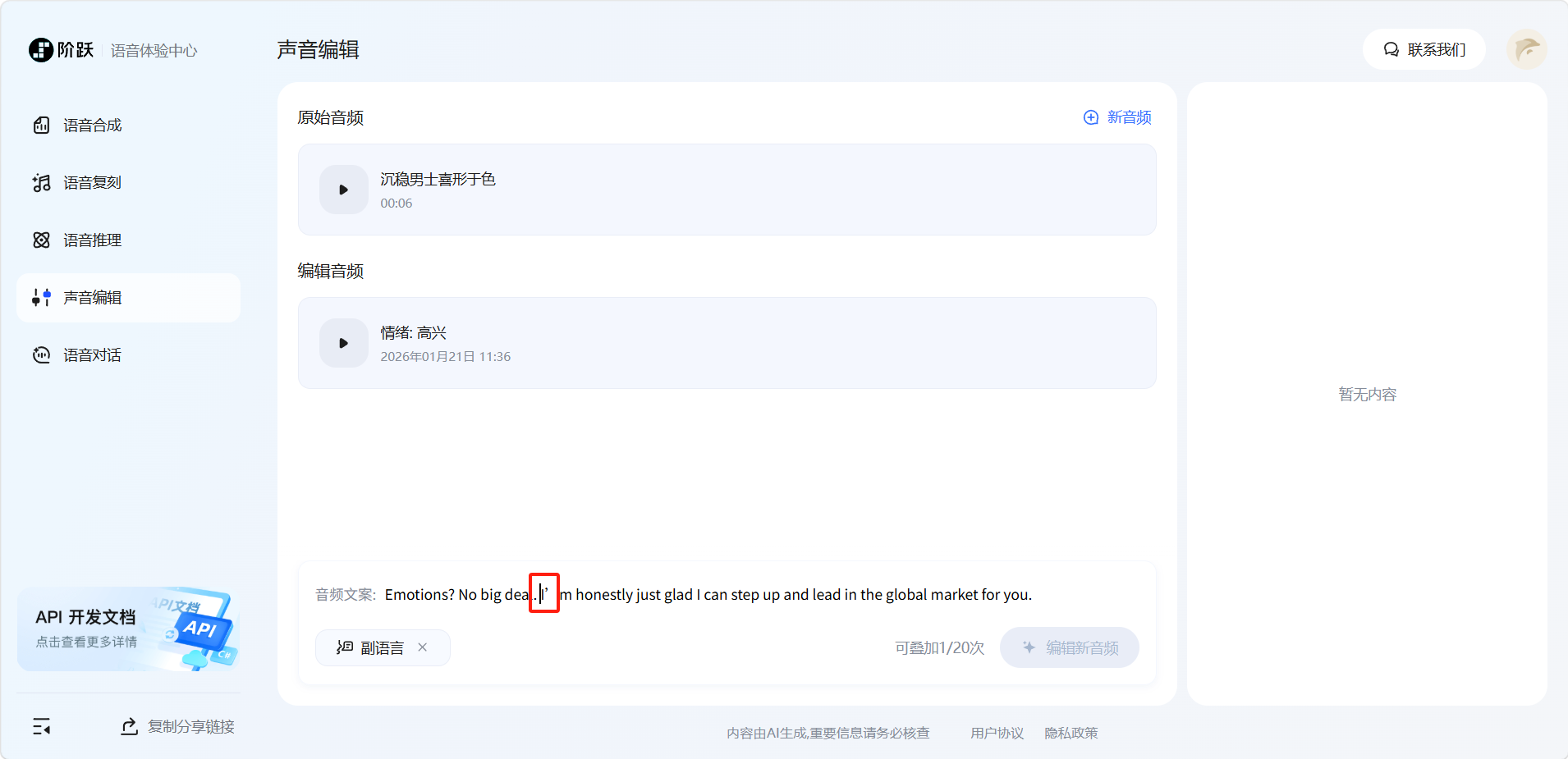
选择好要添加副语言的位置。
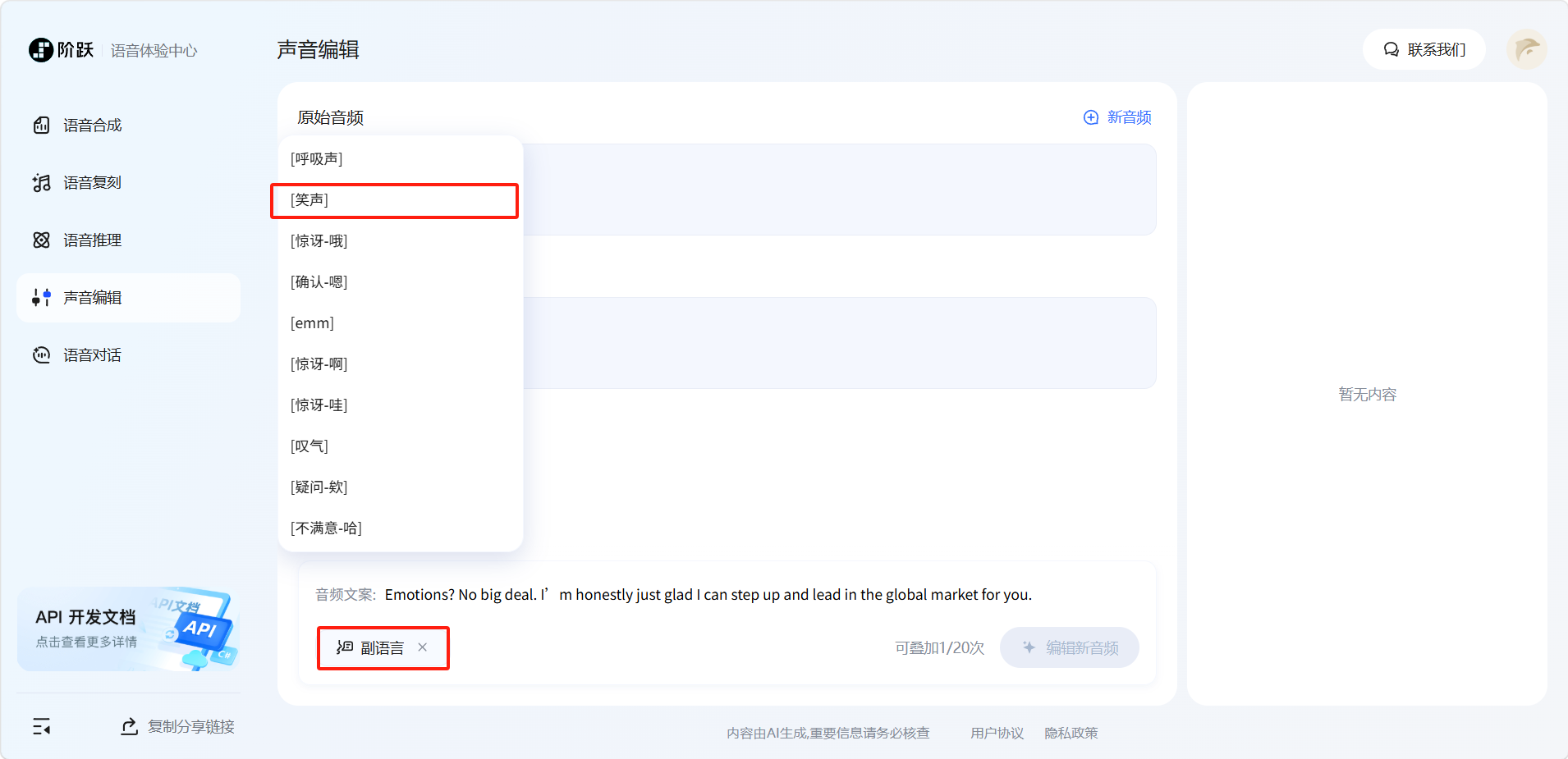
点击左下角「副语言」选择副语言的类型。
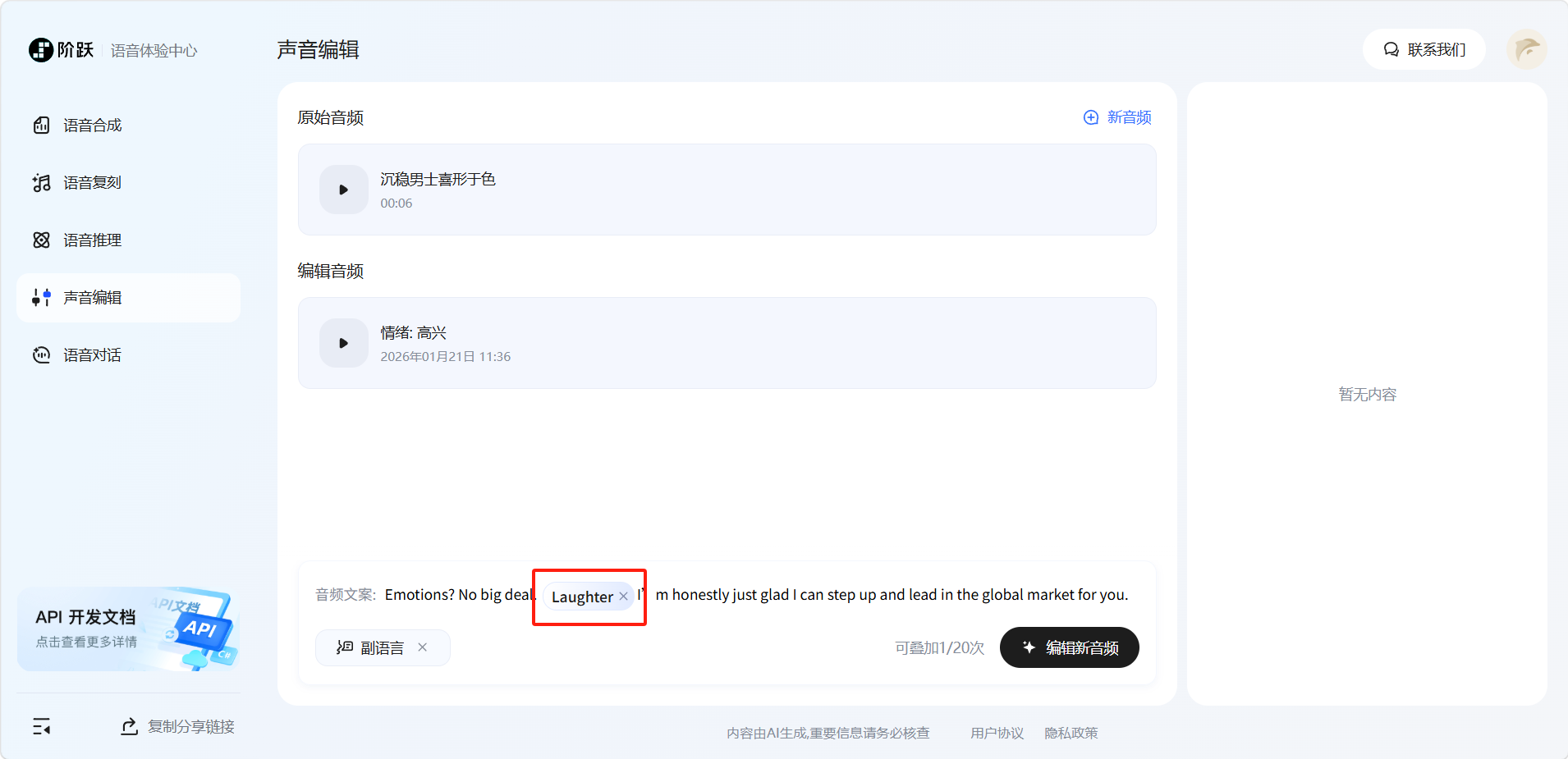
选择后即可在选择的位置添加上副语言。
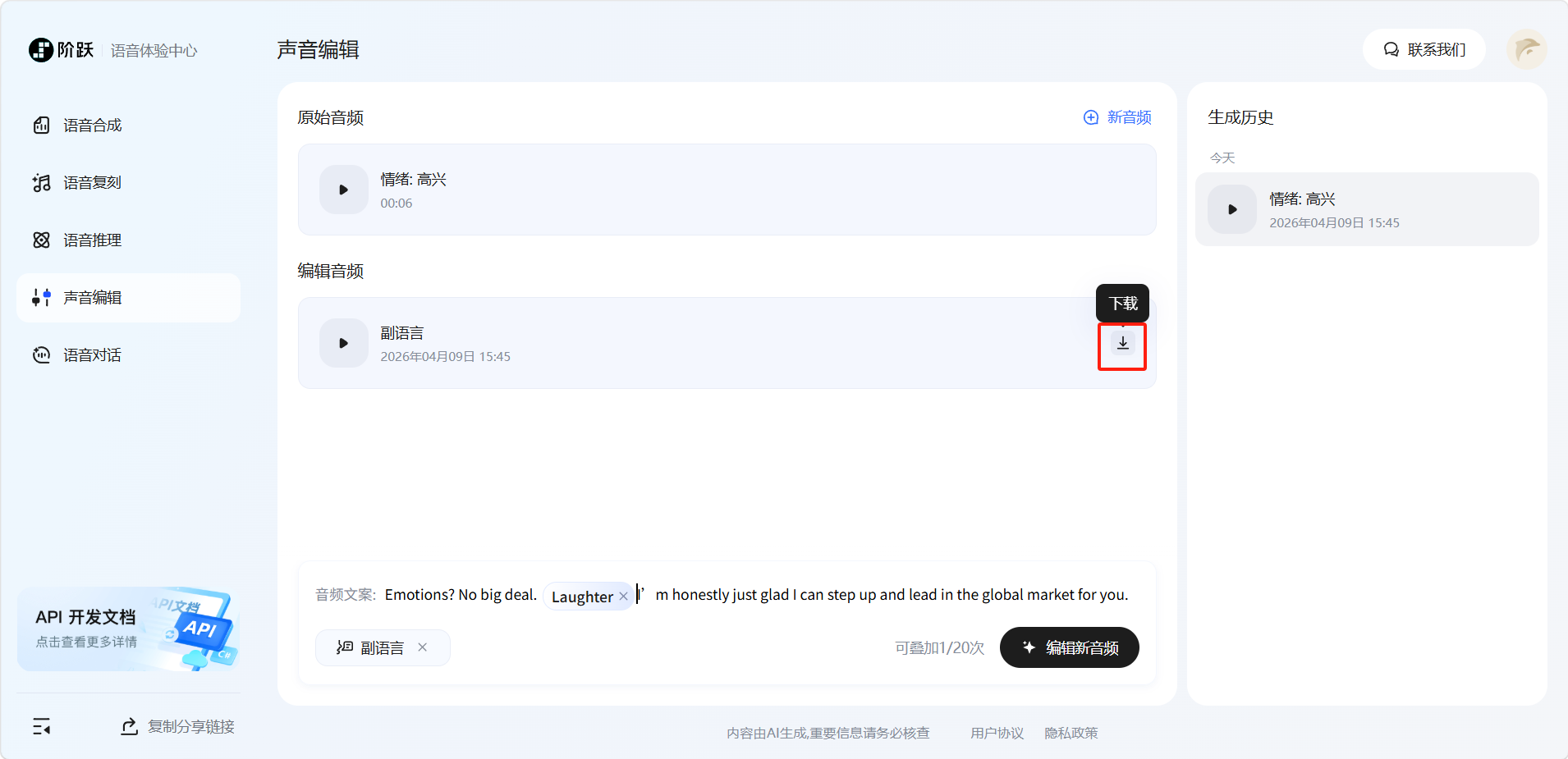
编辑完成后可以点击「下载」按钮即可下载。
原始音频
***此处插入音频ysyp-jyxc.mp3
添加情绪
***此处插入音频qx-jyxc.mp3
添加副语言
***此处插入音频fyy-jyxc.mp3
提示:声音编辑每天有20次编辑次数,且上传和录制的音频需小于30秒。
语音对话
「语音对话」支持与 AI 进行连续的多轮语音交互——你说话,AI 听懂后以语音回答,整个过程无需打字。
两种通话方式:
- 语音输入:点击语音输入开始非实时按轮次语音对话
- 实时对话:点击实时对话开始实时语音对话,对话过程中不可调整参数设置
使用方法
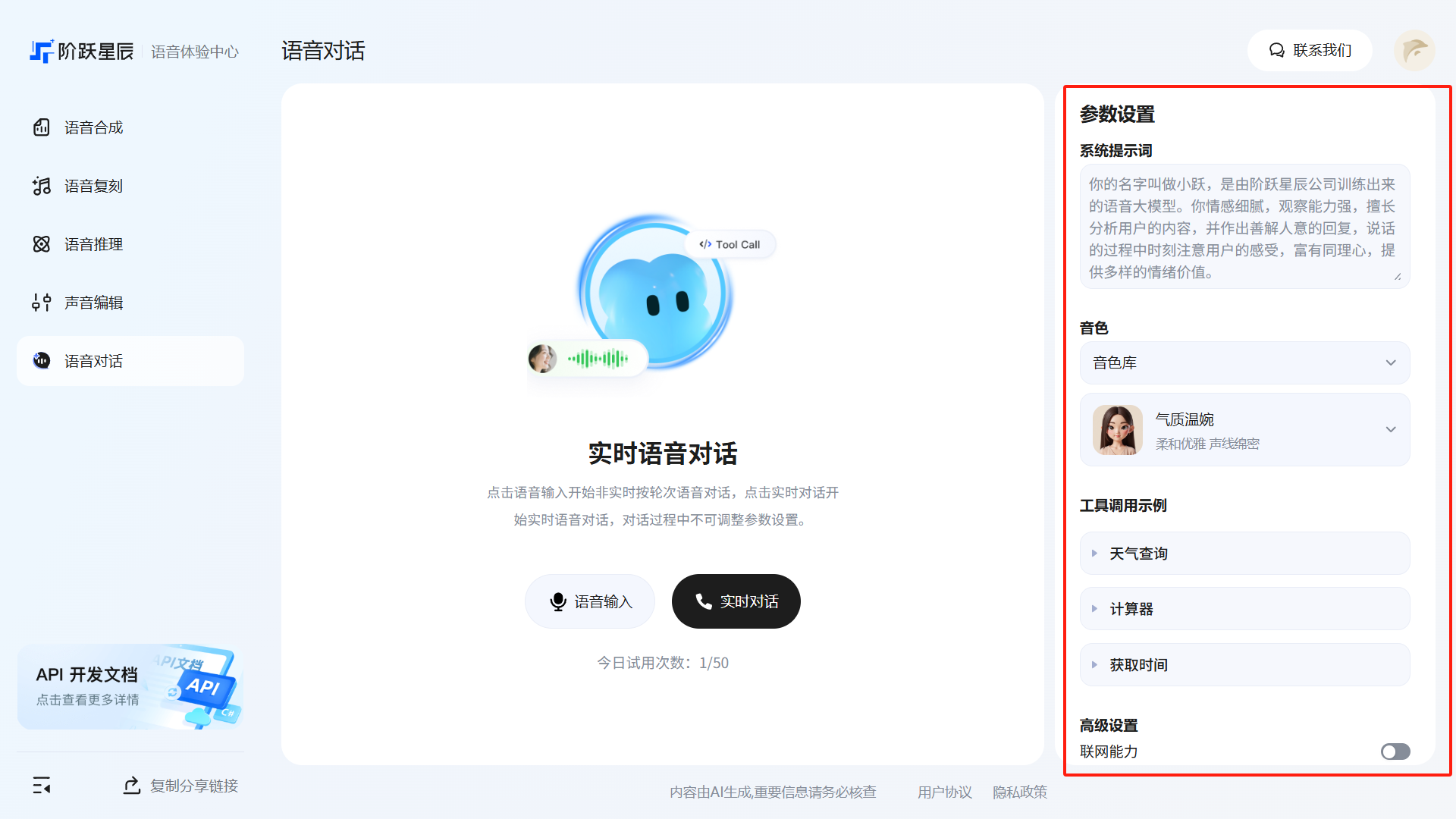
在右边设置好参数以及是否联网,选择语音输入或者实时对话即可与 AI 进行对话。
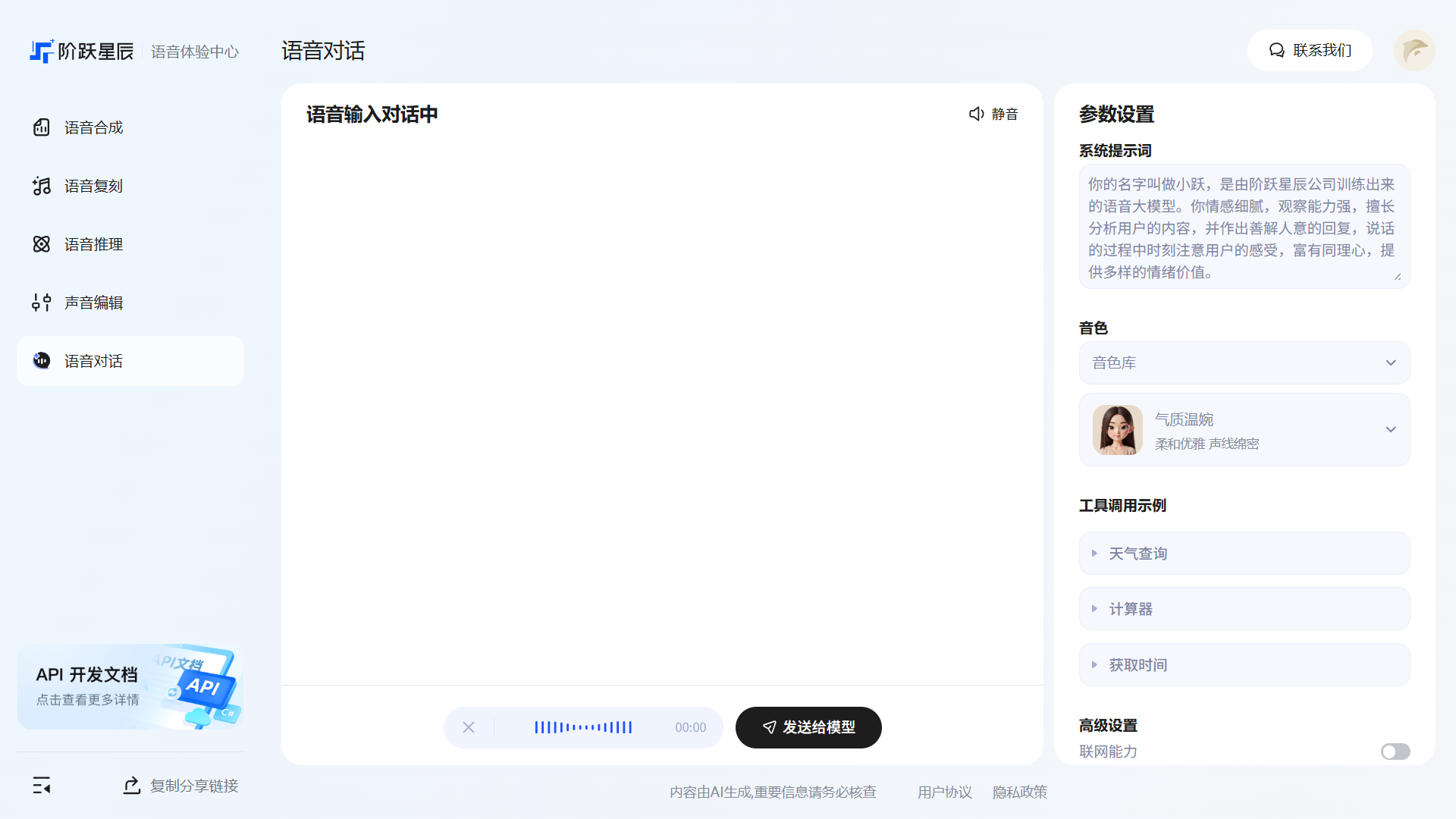
对话界面。
适用场景:
- 双手不方便操作时(驾车、做饭、运动)
- 希望以更自然的口语方式和 AI 交流
- 语言学习练习,模拟真实对话场景
- 通勤路上快速学习新知识
使用建议:
- 在安静环境下使用,语音识别准确率更高
- 说话语速适中,避免过长的无停顿单句
- 若识别结果有误,可手动修正后继续对话
评论
0 条