8. 工作流
功能概述
工作流是扣子平台中用于编排复杂业务逻辑的核心工具。通过可视化的拖拽画布,你可以将大模型、插件、代码块等各种节点灵活组合,构建出高效、稳定的自动化处理流程。工作流的价值在于让 AI 不只是"回答问题",更能"执行任务"。工作流编辑器提供了从开始节点到结束节点之间的可视化流程编排界面,支持实时调试和运行测试。
一句话创建工作流
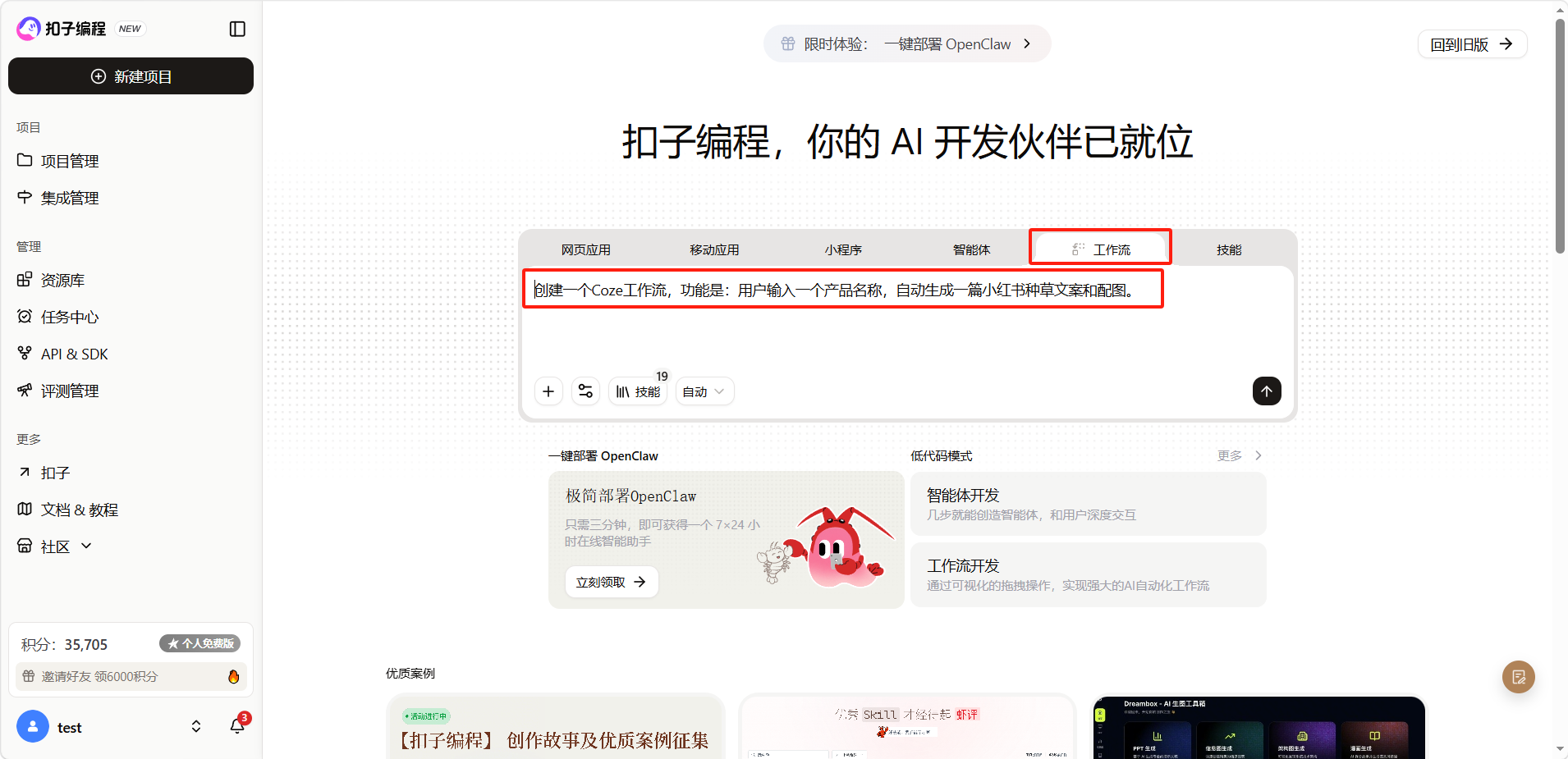
在输入框上方选择「工作流」,输入需求。
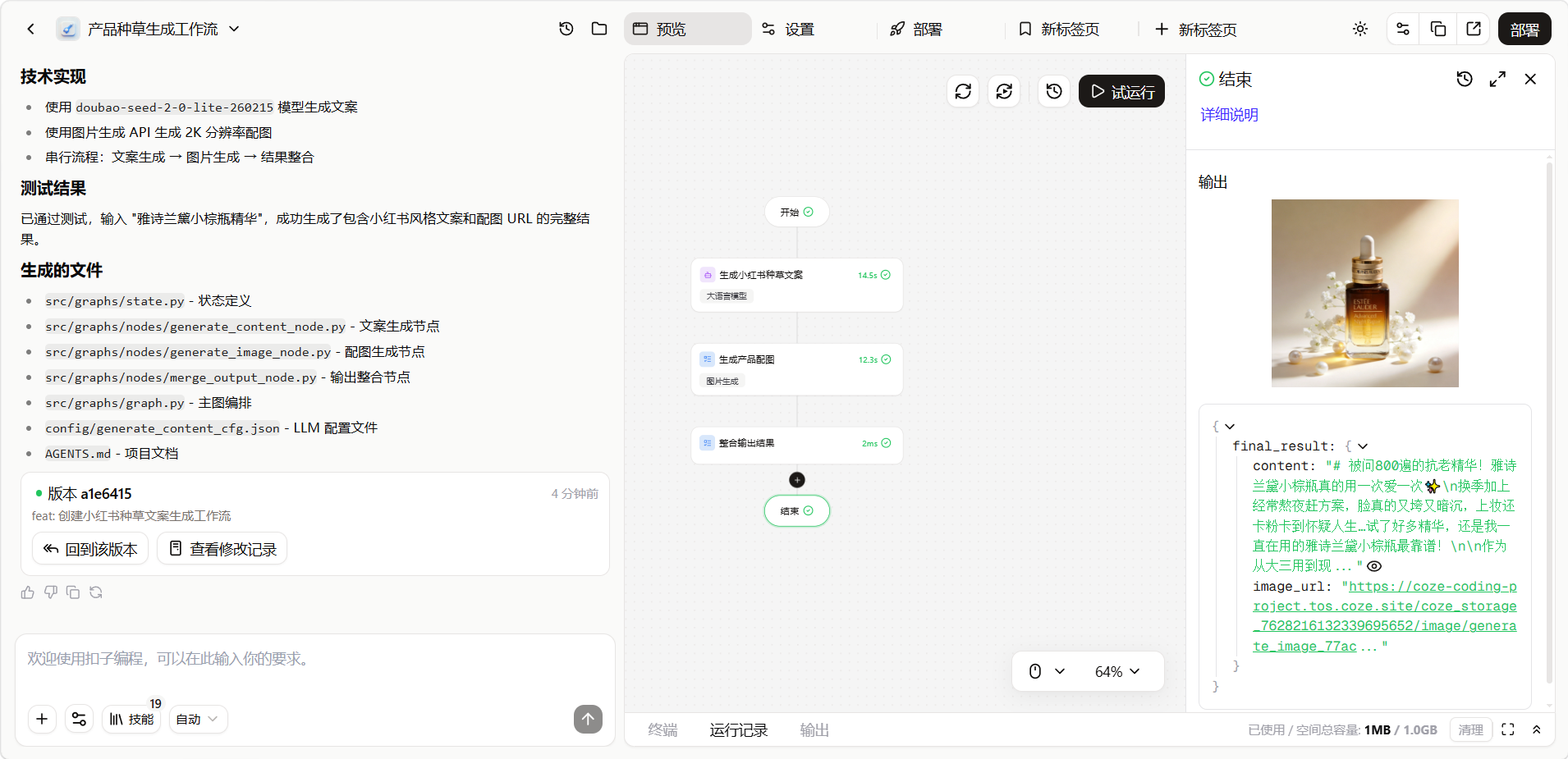
生成效果展示。
自定义创建工作流
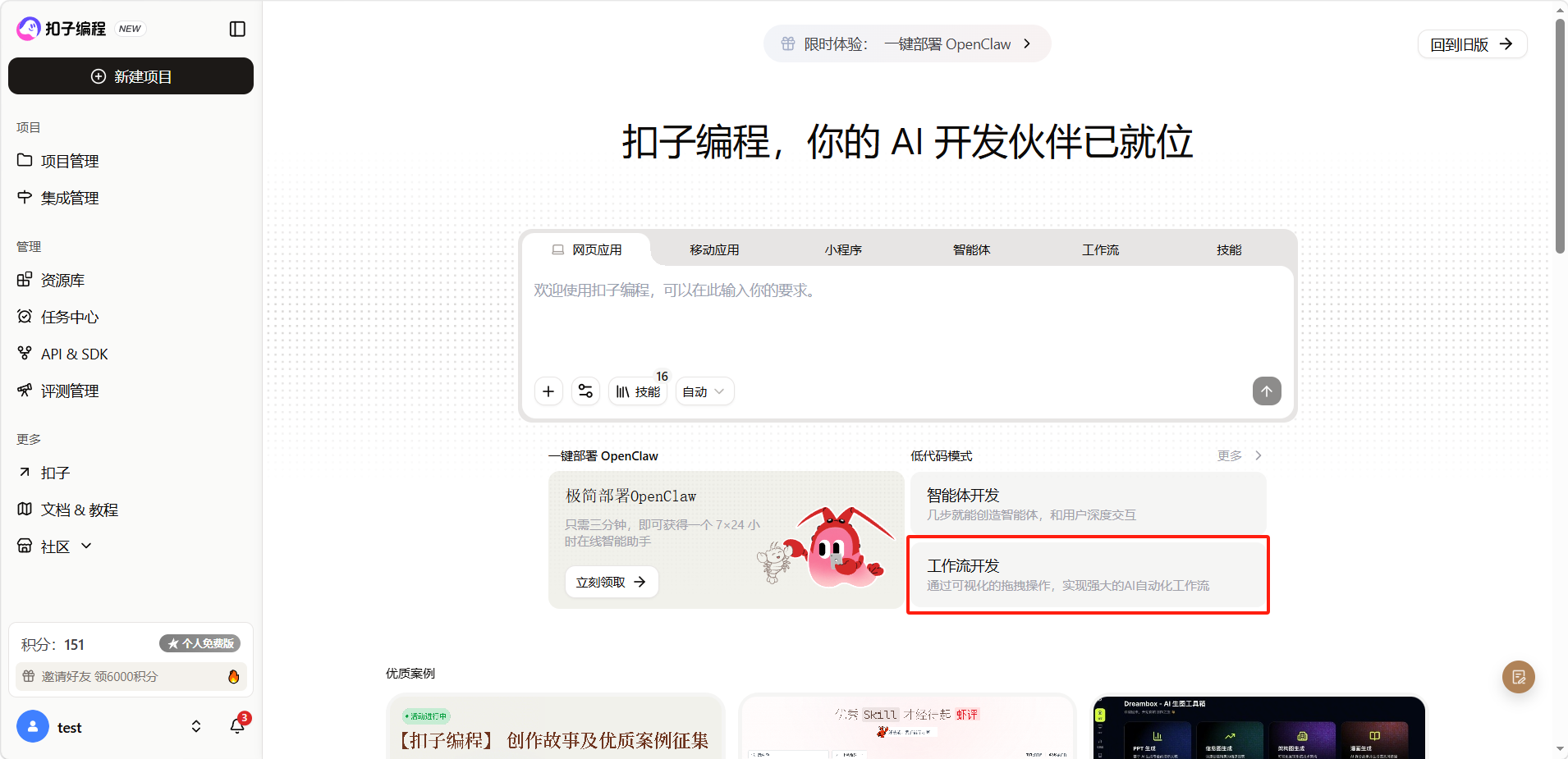
进入扣子编程平台,点击「新建项目」,选择「工作开发」类型。
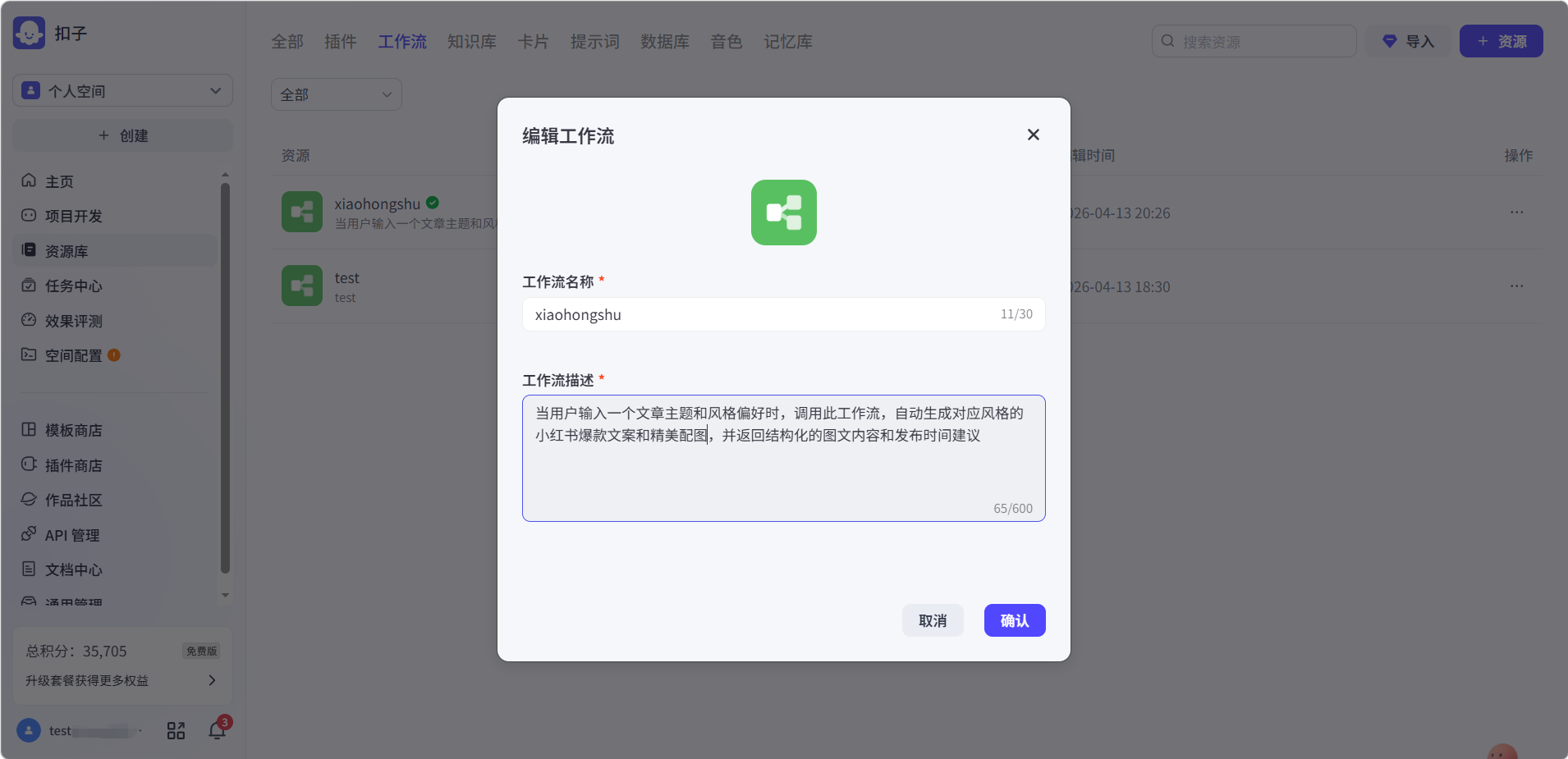
设置工作流的名称和描述。
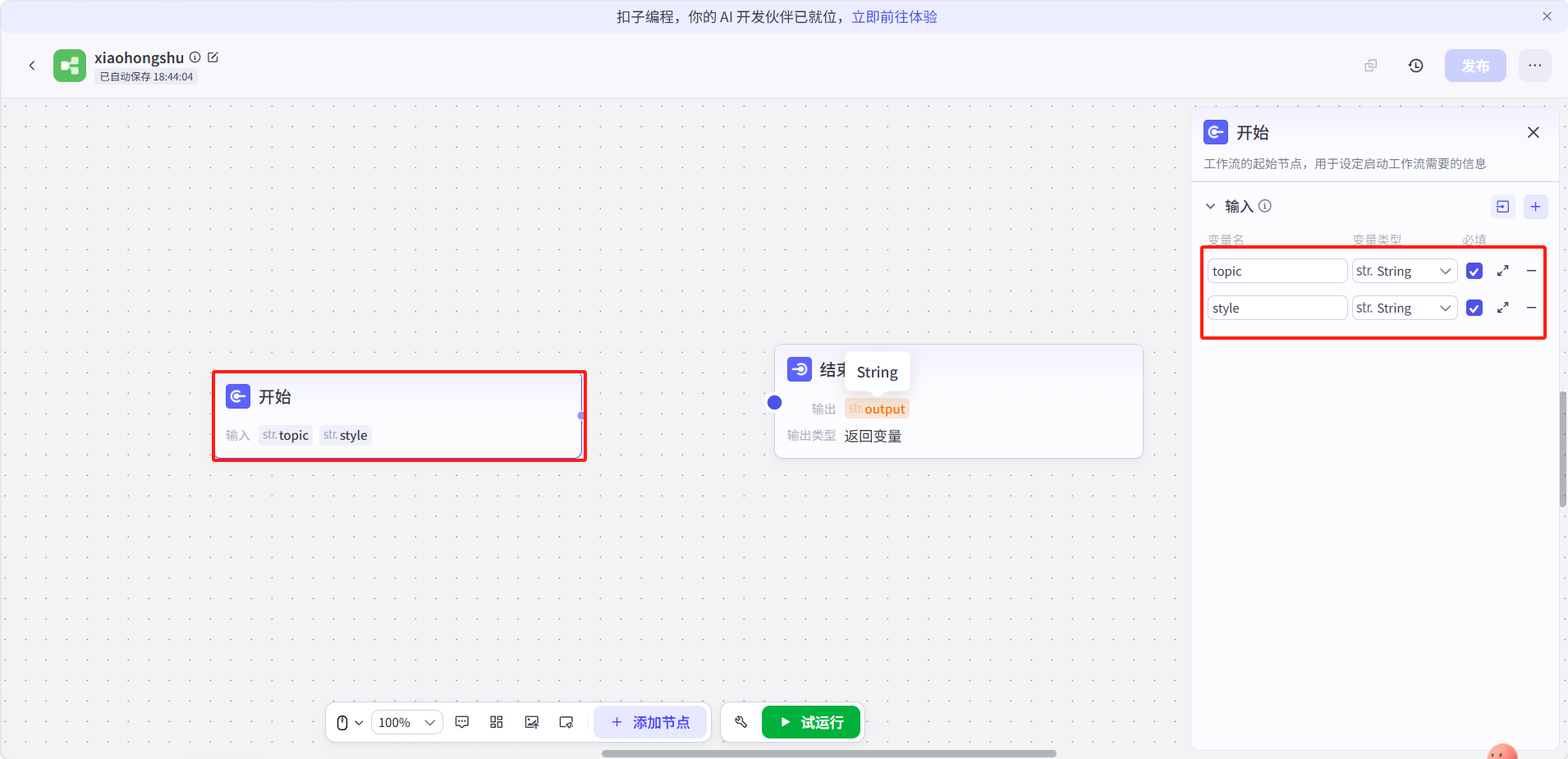
点击开始节点,添加两个输入变量:
- 变量名:
topic,变量类型:str. String,勾选必填 - 变量名:
style,变量类型:str. String,勾选必填
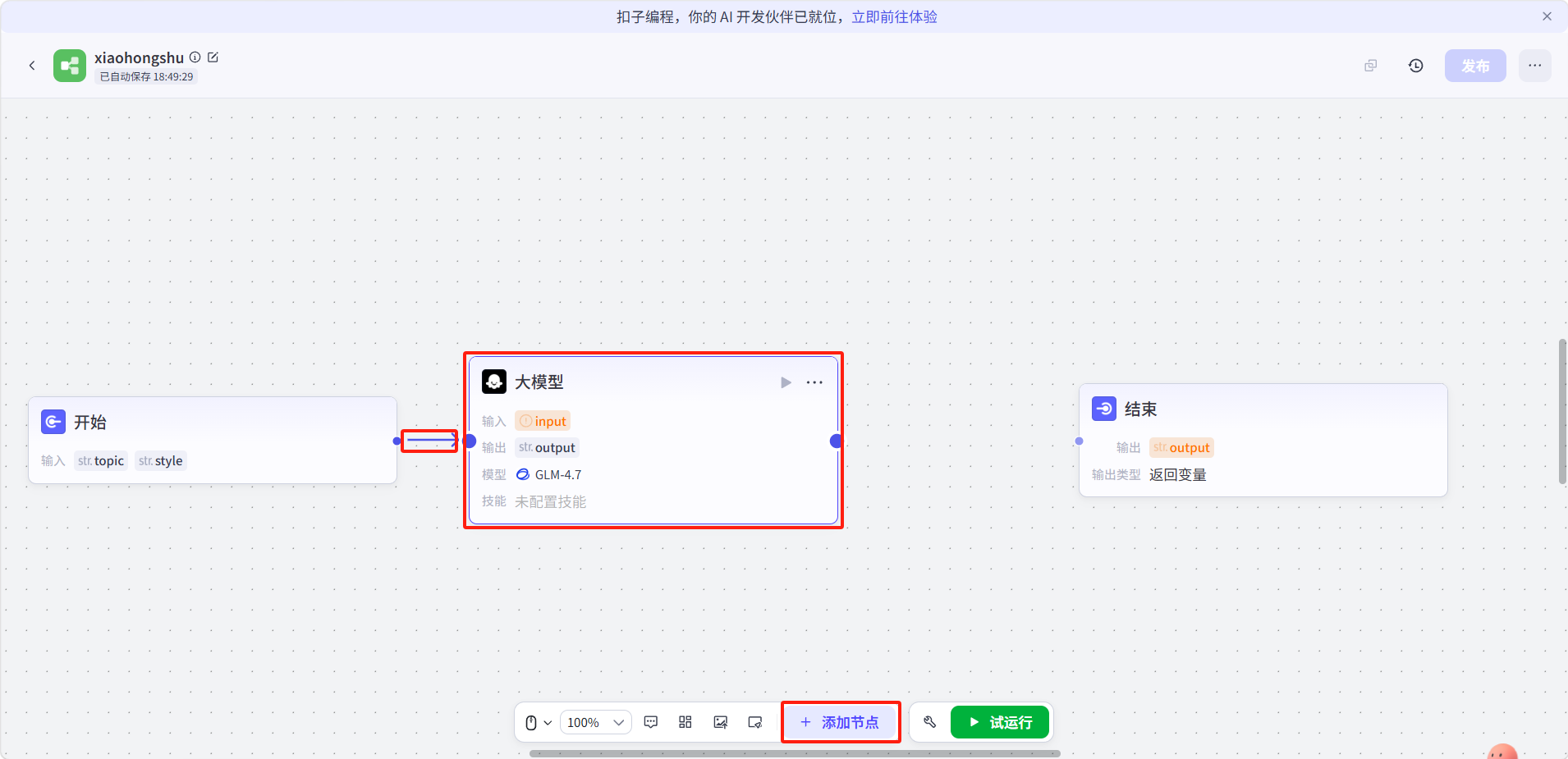
点击底部「添加节点」,添加一个大模型节点并与开始节点连接。
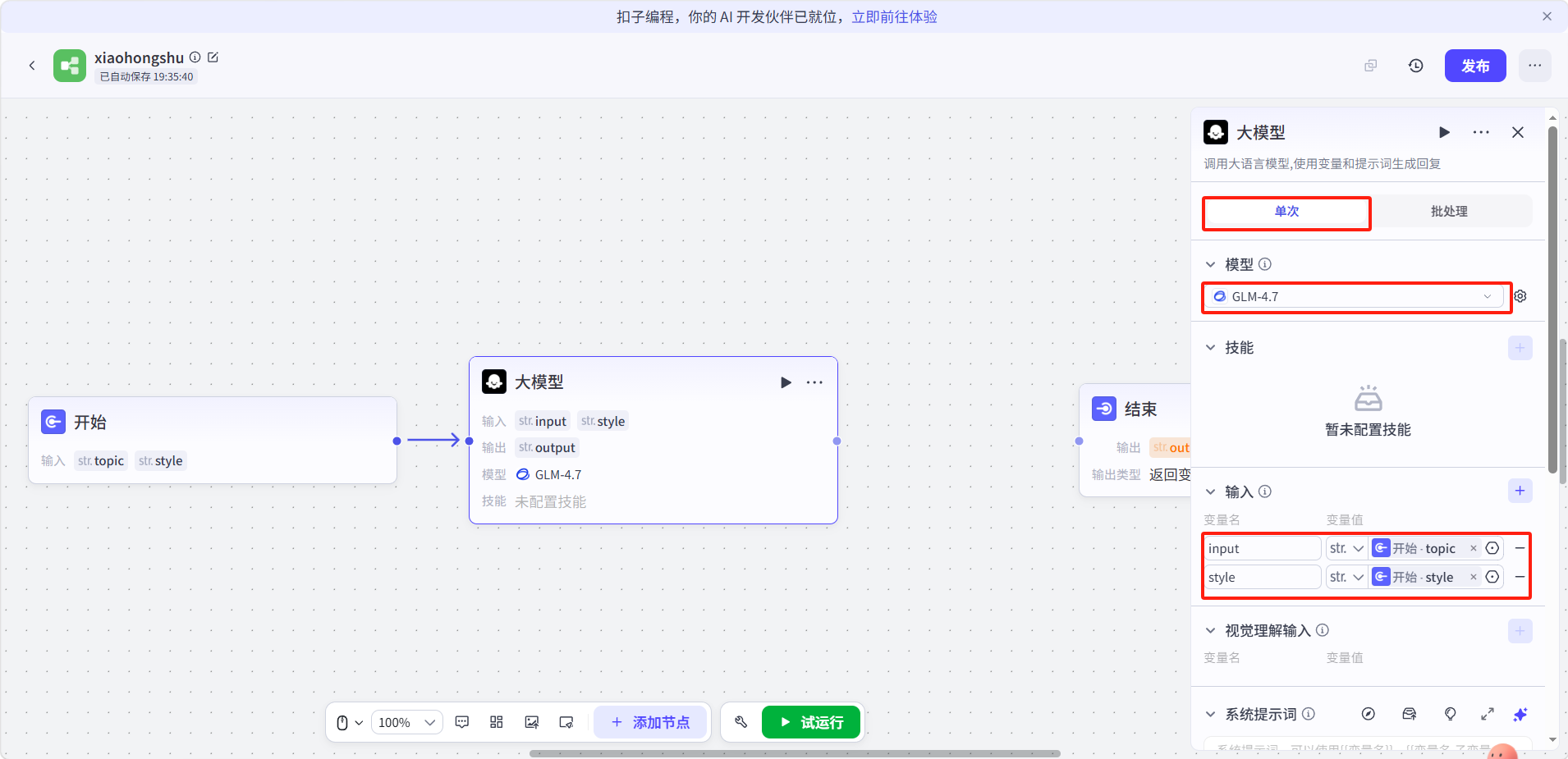
点击大模型节点进行配置:
-
处理方式:单次
-
模型:GLM-4.7(或其他可用模型)
-
输入:添加两个变量值引用开始节点的
topic,style
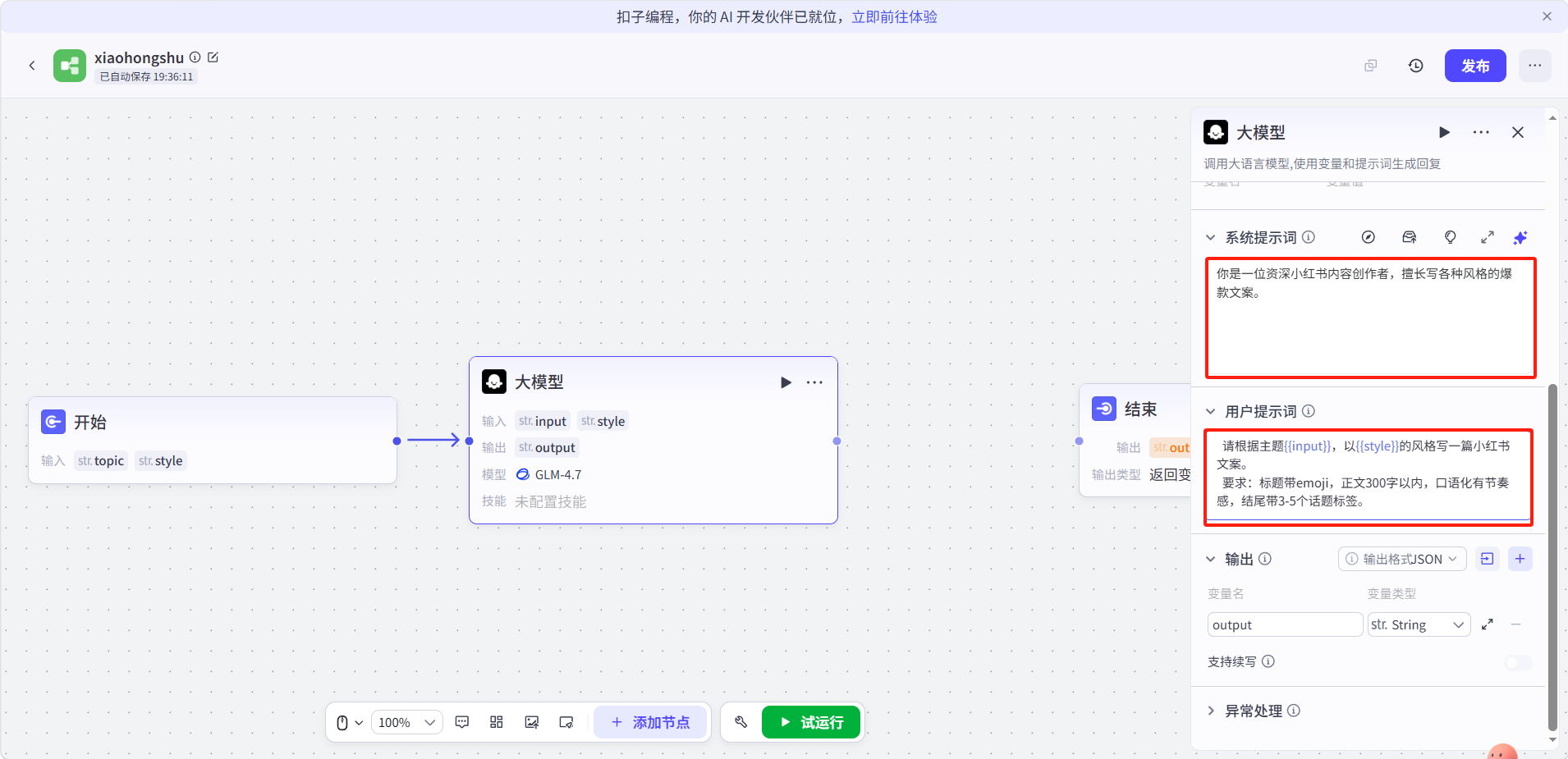
填写大模型提示词。
- 系统提示词:
- 用户提示词:
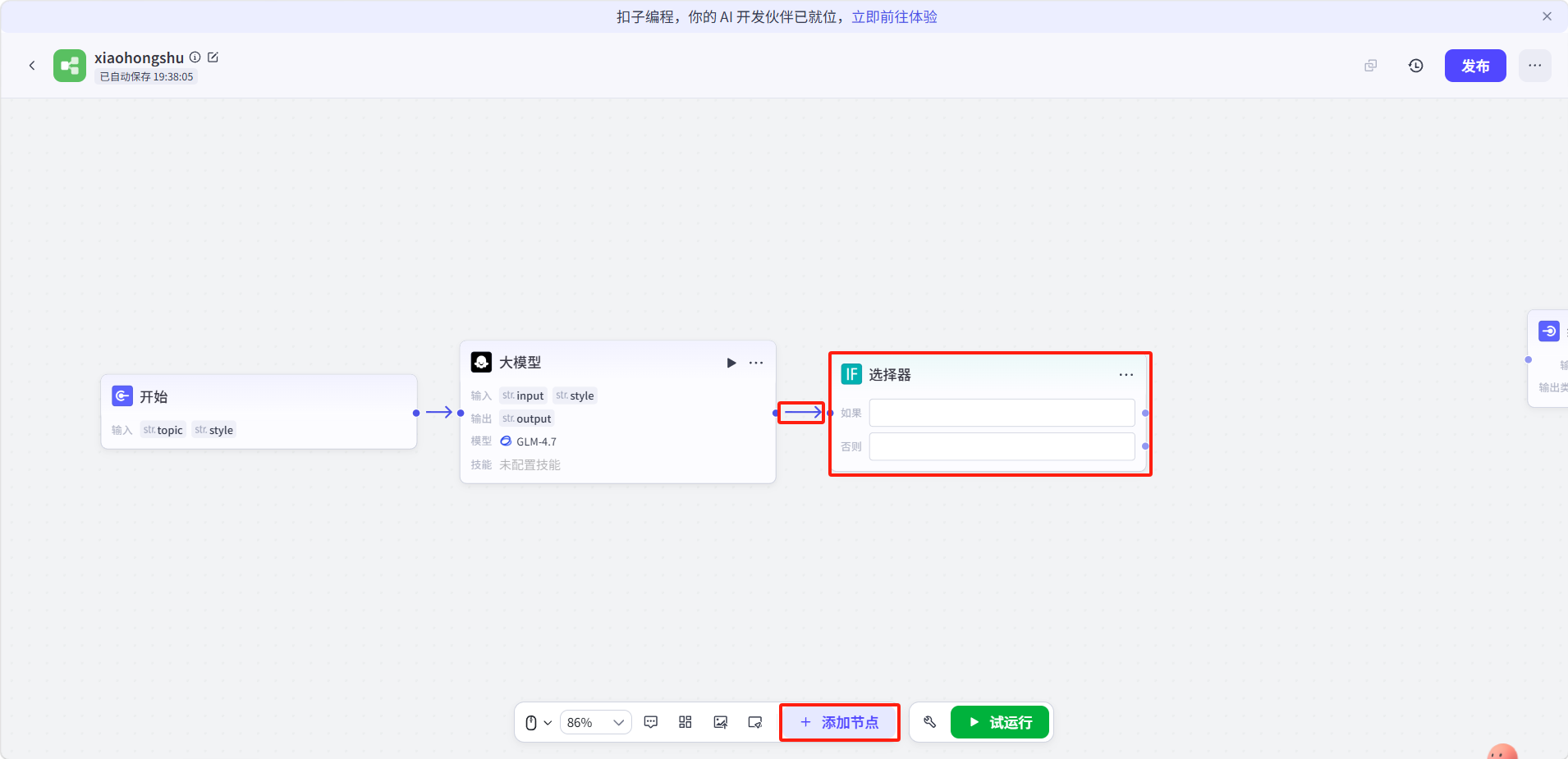
点击底部「添加节点」,添加一个选择器节点并与开大模型节点连接。
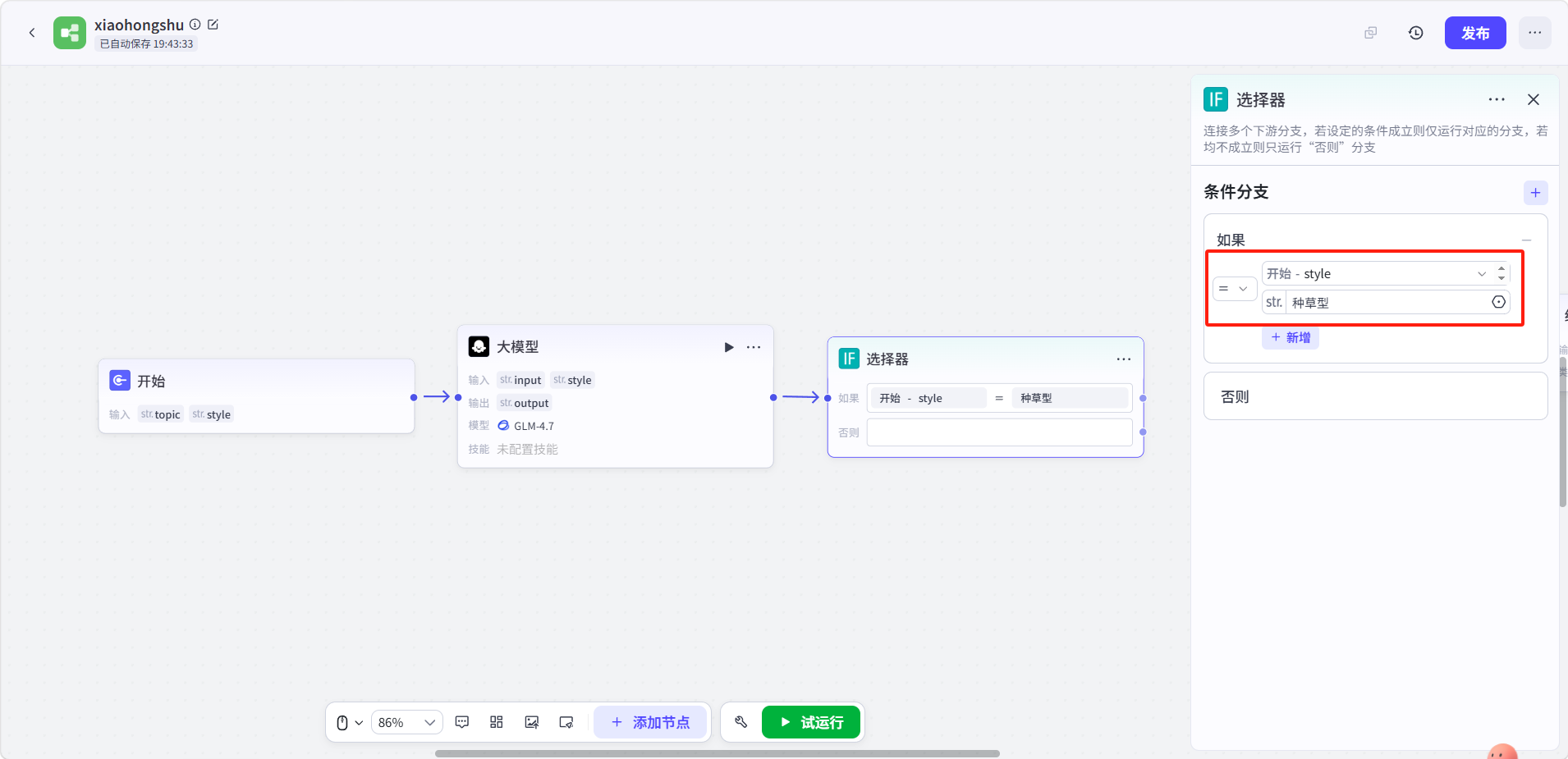
点击选择器节点进行配置:
-
条件分支 - 如果:选择引用开始节点的
style,条件设为等于,值填种草型 -
可以点击右上角 "+" 添加更多条件分支(如"教程型")
-
否则:作为默认分支处理
"如果"分支(种草型)→ 连接到图像生成节点(生成配图)
"否则"分支 → 直接连接到变量聚合节点(纯文案不配图)
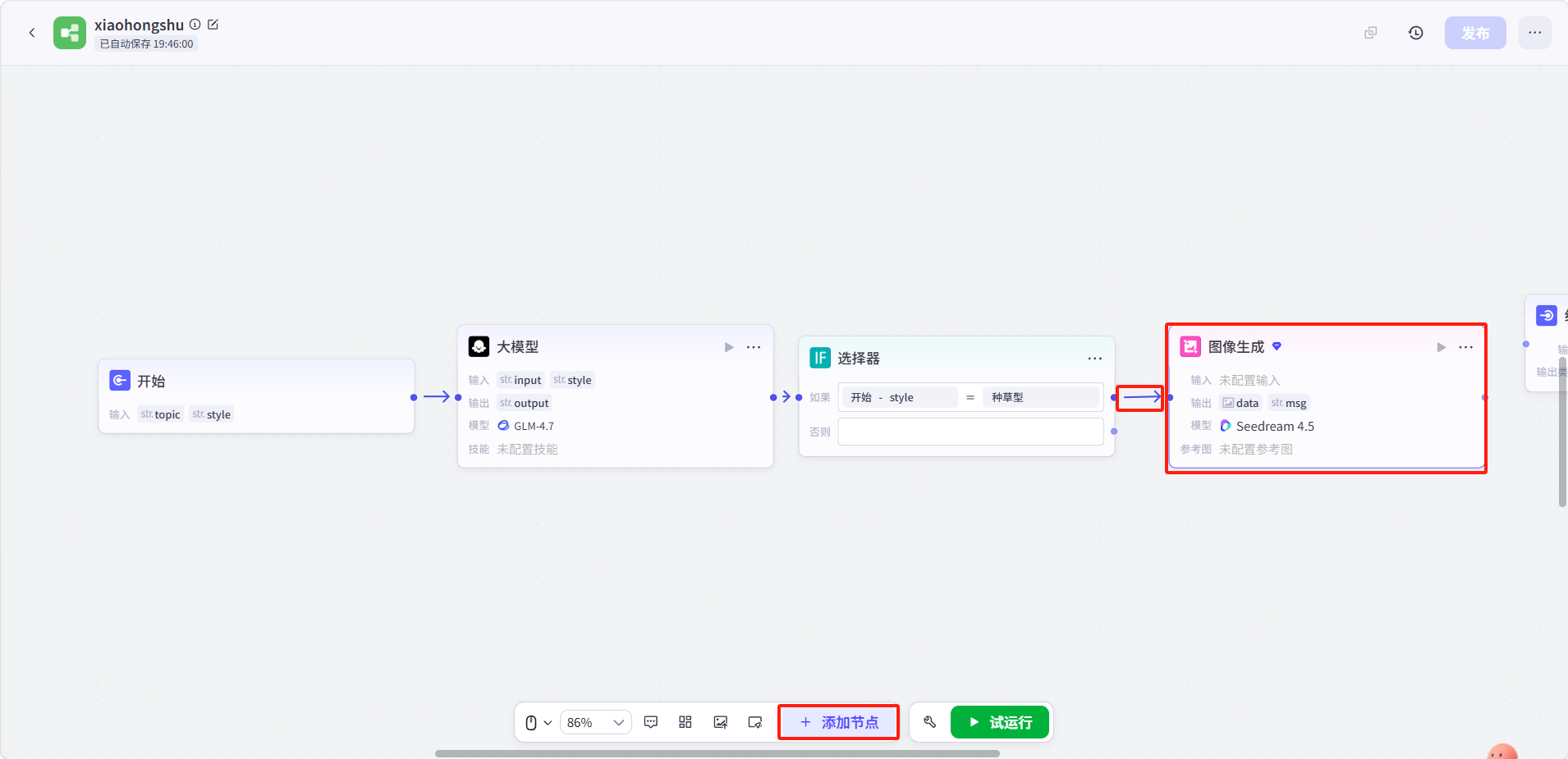
点击底部「添加节点」,添加一个图像生成节点并与选择器的如果节点连接。
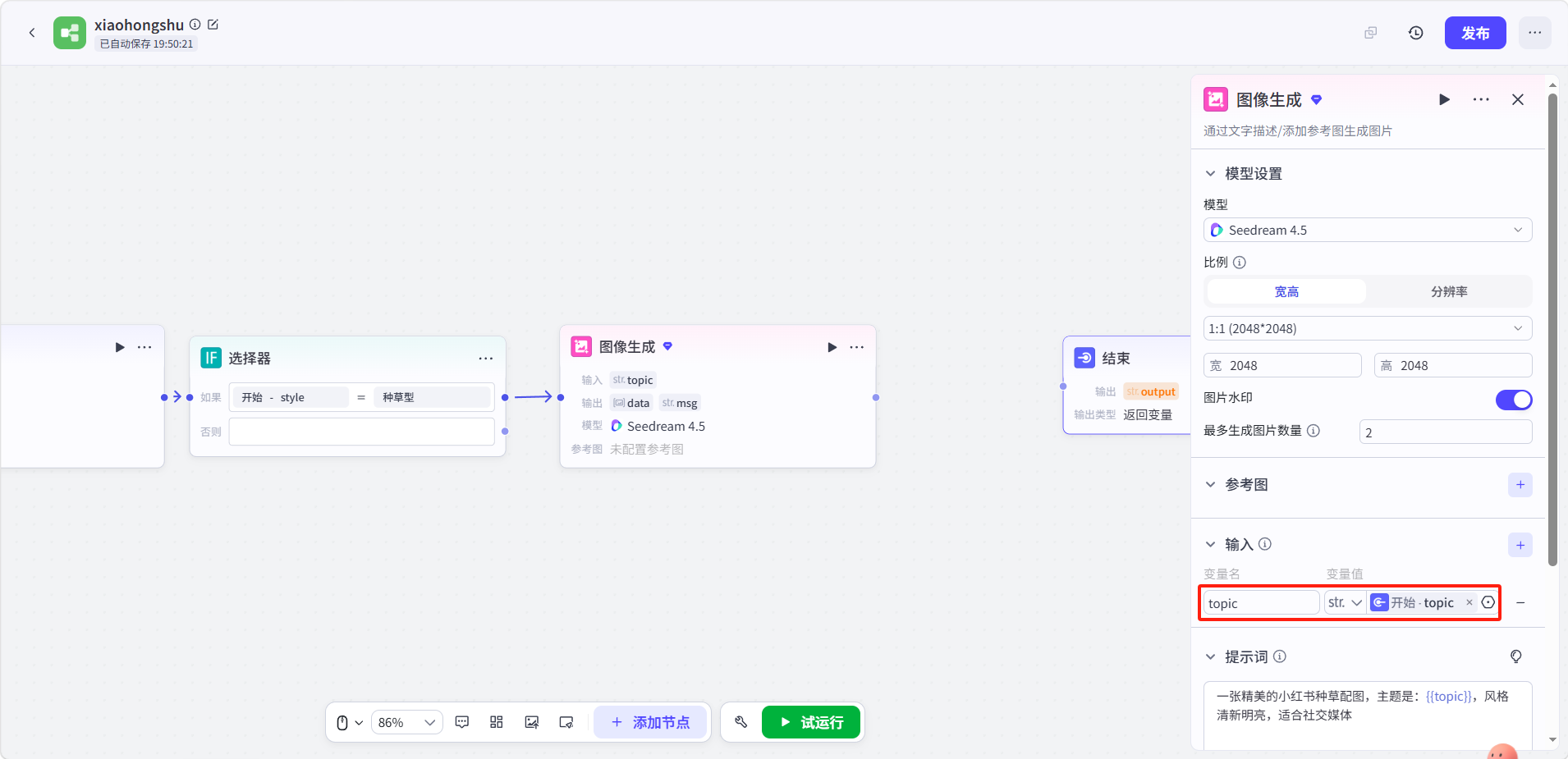
点击图像生成节点进行配置:
- 点击「+」添加变量,变量名填
topic,类型str.,变量值引用开始节点的topic - 模型以及其他选项用户可自行配置
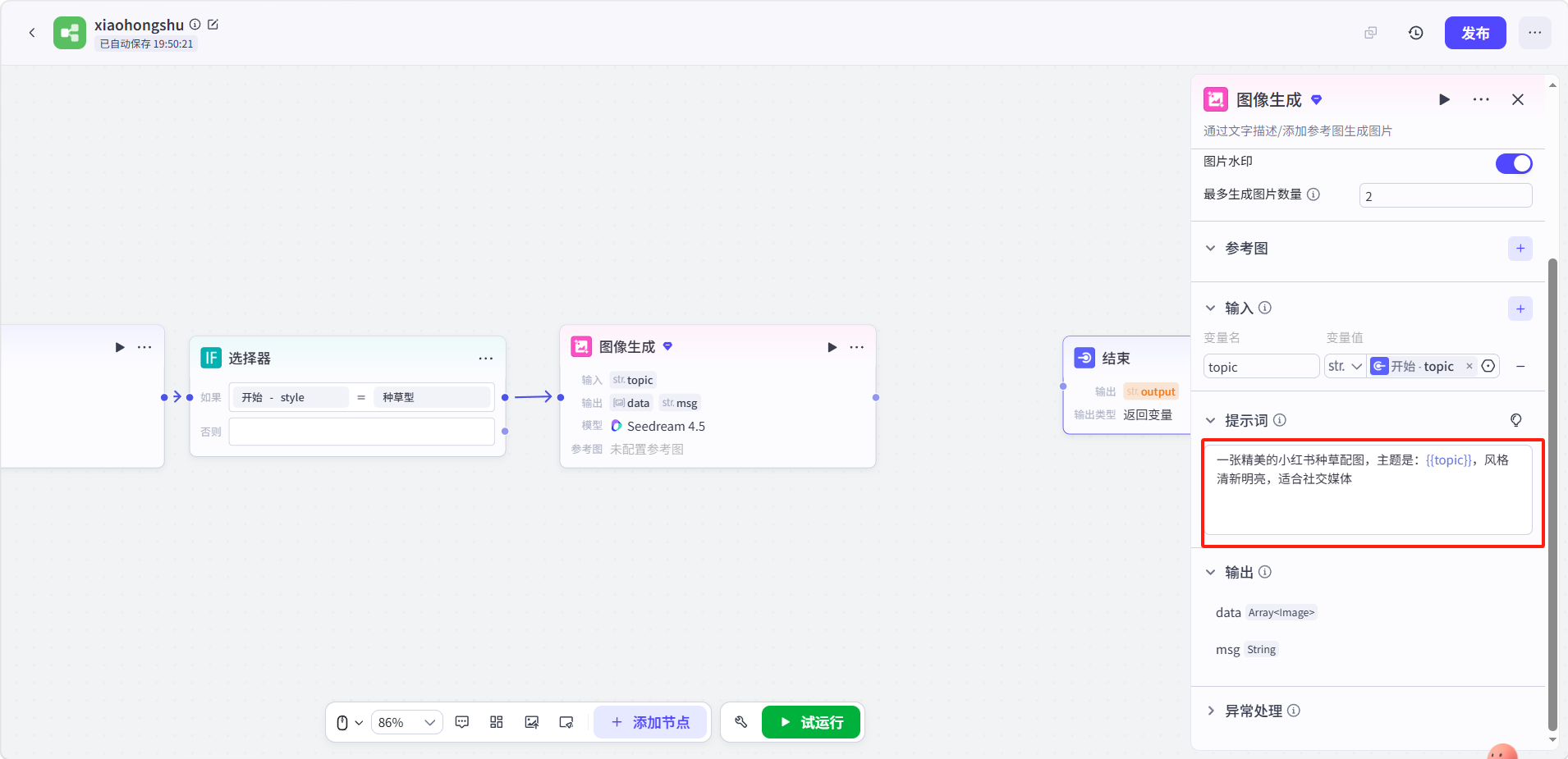
填写提示词。
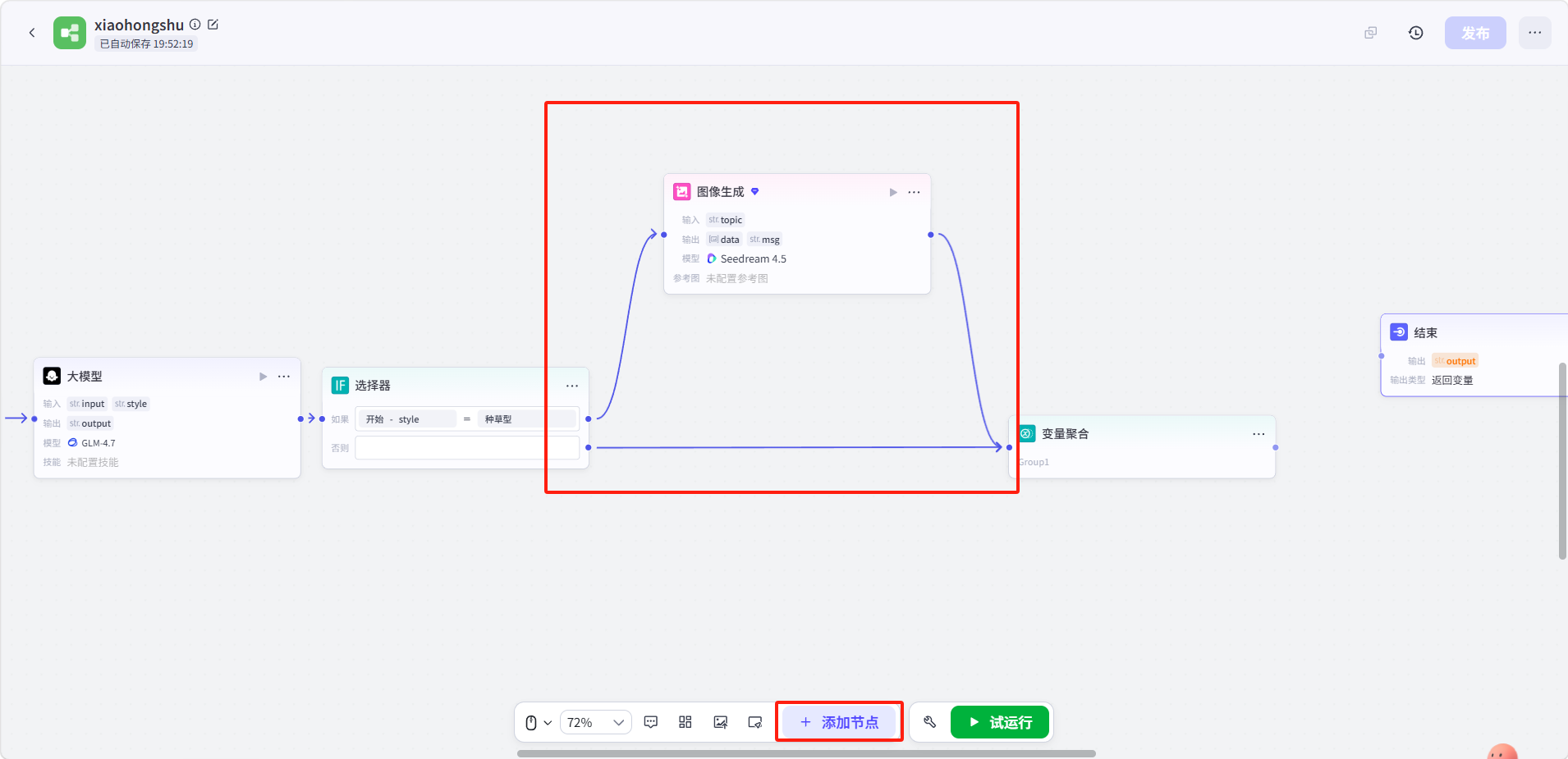
点击底部「添加节点」,添加一个变量聚合节点并与选择器的否则节点和图像生成节点连接。
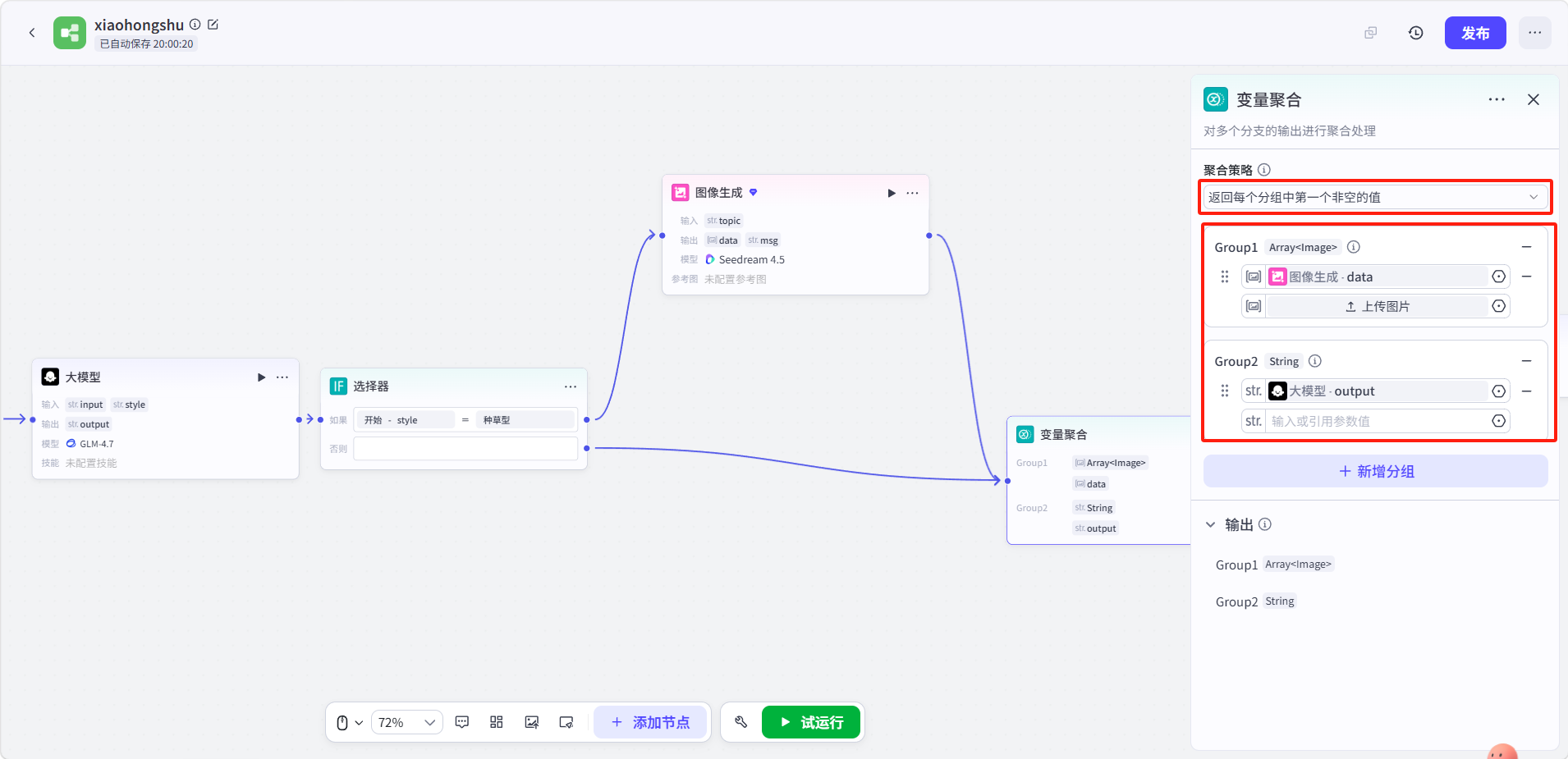
点击变量聚合节点进行配置:
-
聚合策略:返回每个分组中第一个非空的值
-
Group1(配图结果):
类型:
Array<Image>变量值:引用图像生成节点的
data输出 -
Group2(文案结果):
类型:
str.变量值:引用大模型节点的
output
这个节点的作用是:不管走了哪个分支,都能把结果统一汇总到一个变量中继续传递。
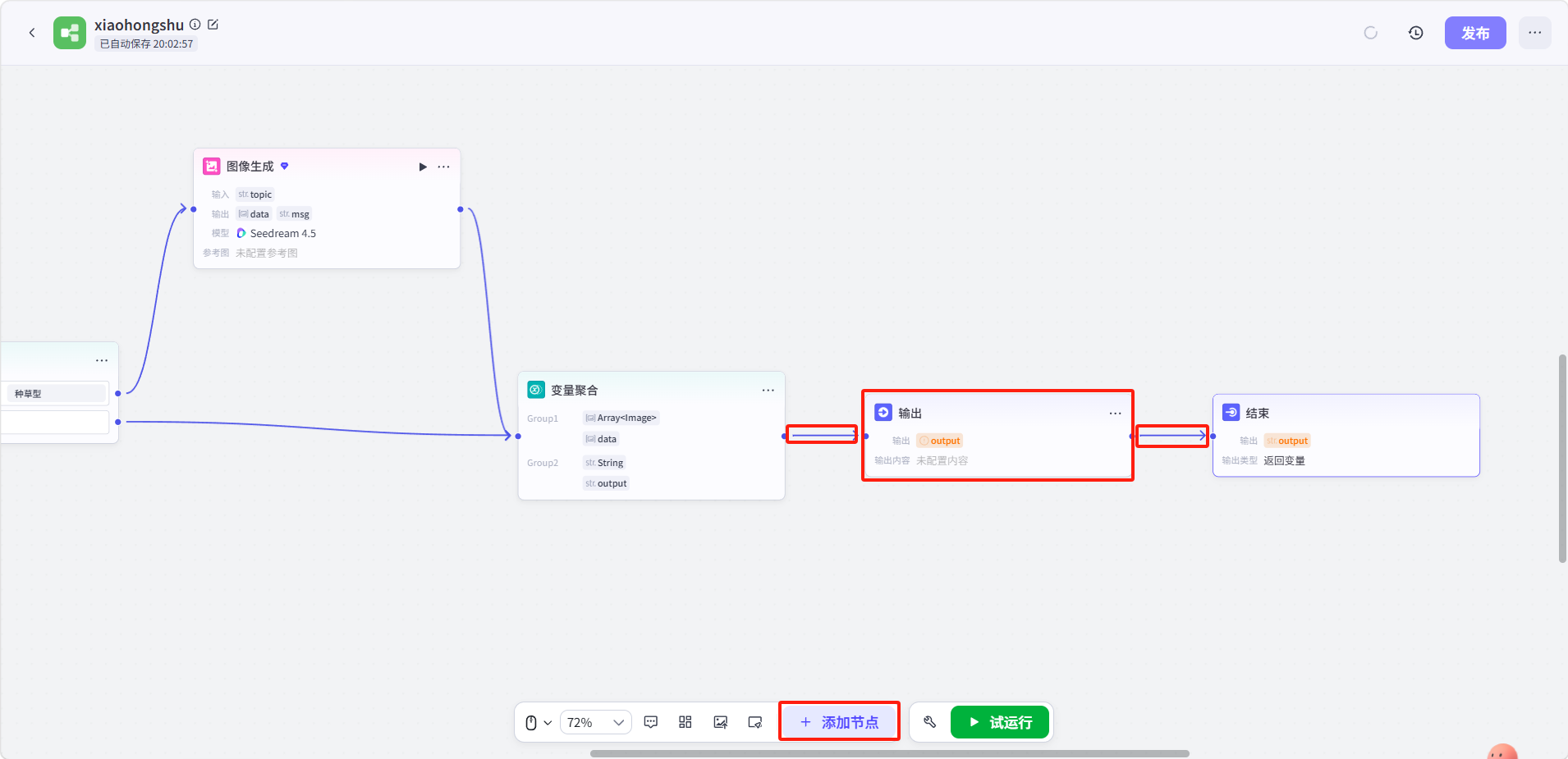
点击底部「添加节点」,添加一个输出节点并与变量聚合节点和结束节点连接。
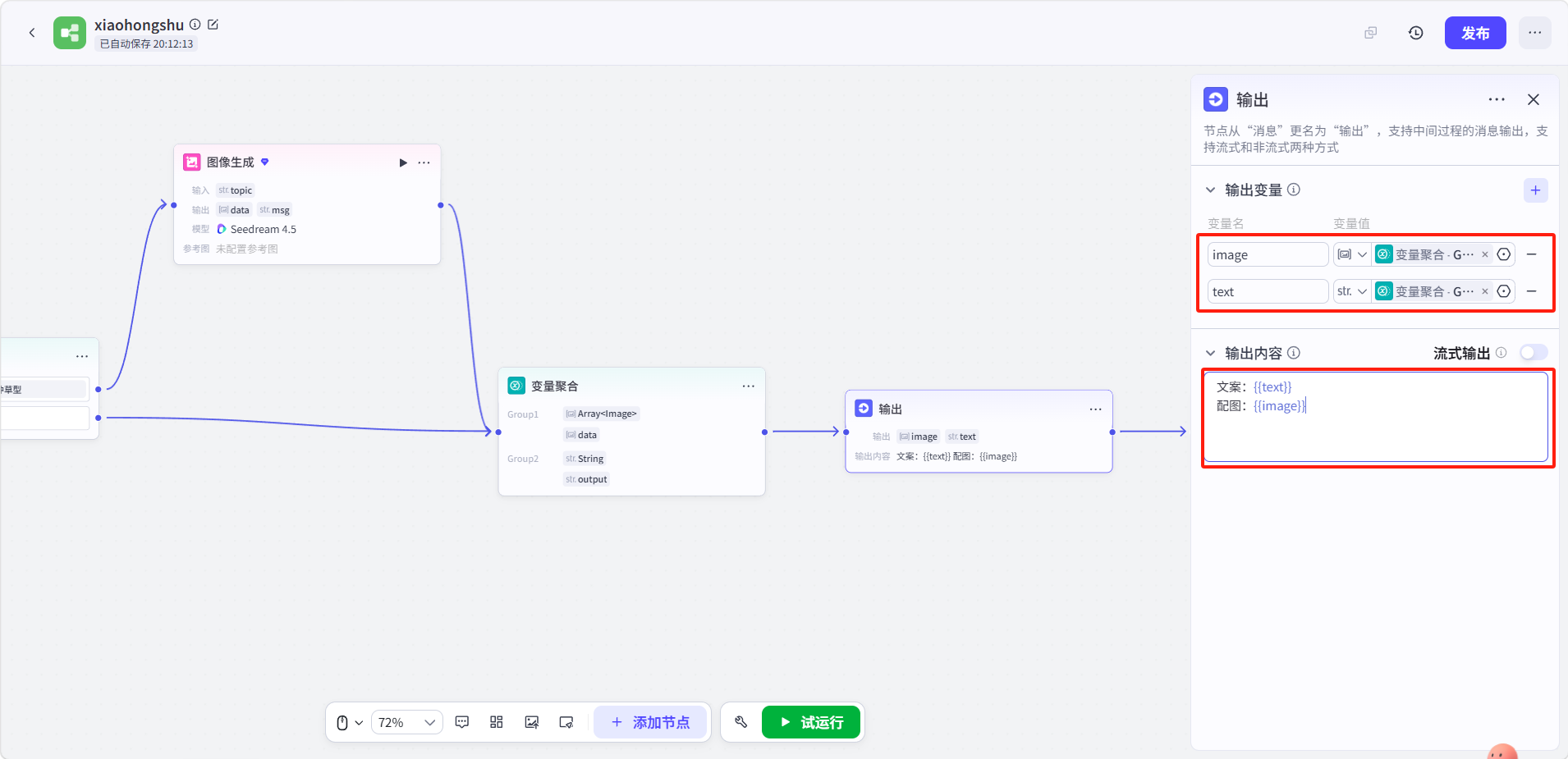
点击输出节点配置两个变量并填写输出内容:
-
变量名:
image:类型Array<Image>,引用 → 变量聚合 →Group1 -
变量名:
text:类型str.,引用 → 变量聚合 →Group2 -
输出内容:
文案:{{text}} 配图:{{image}}
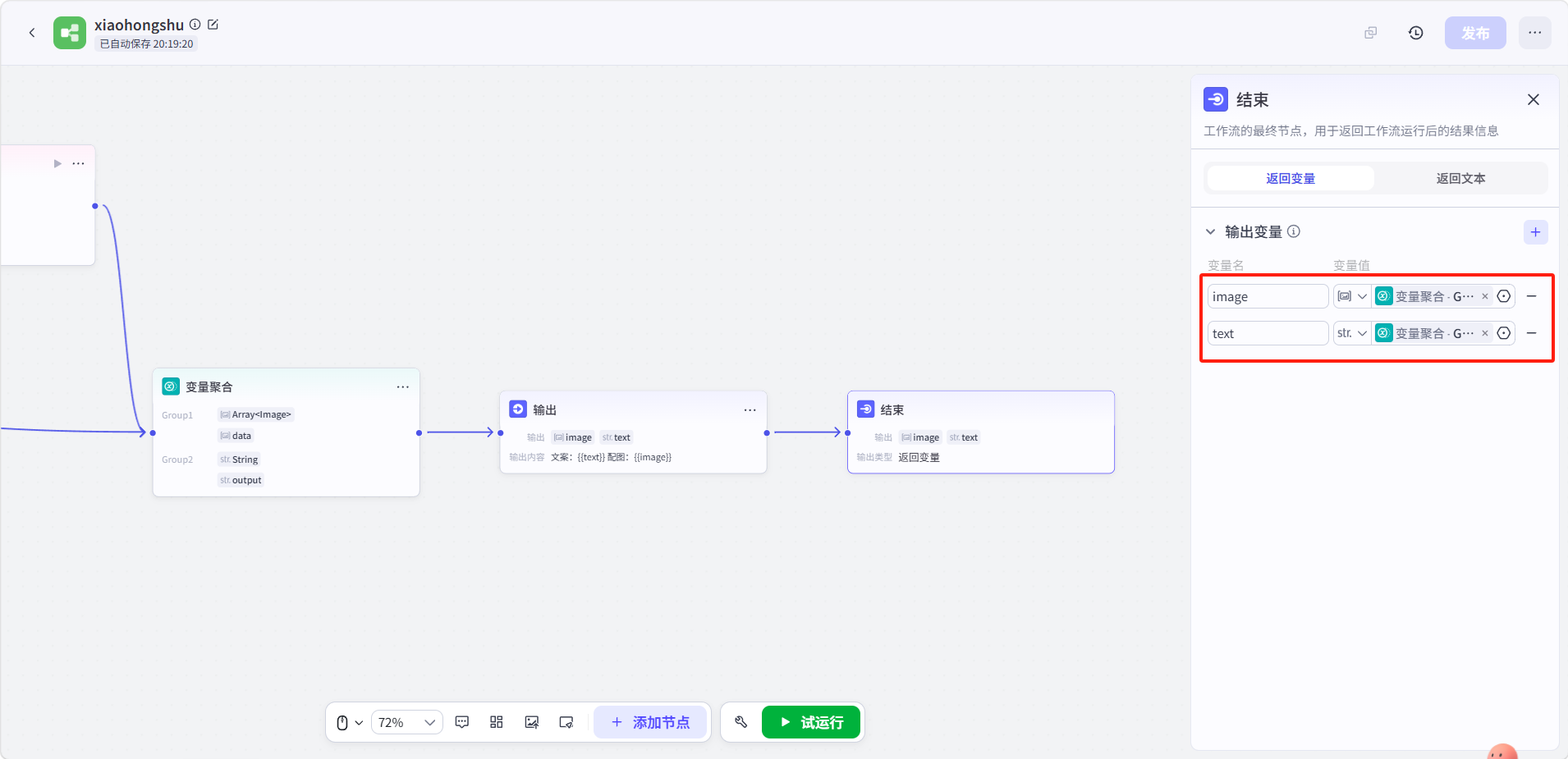
点击结束节点配置两个变量:
-
变量名:
image,类型Array<Image>,引用 → 变量聚合 →Group1 -
变量名:
output:类型str.,引用 → 变量聚合 →Group2
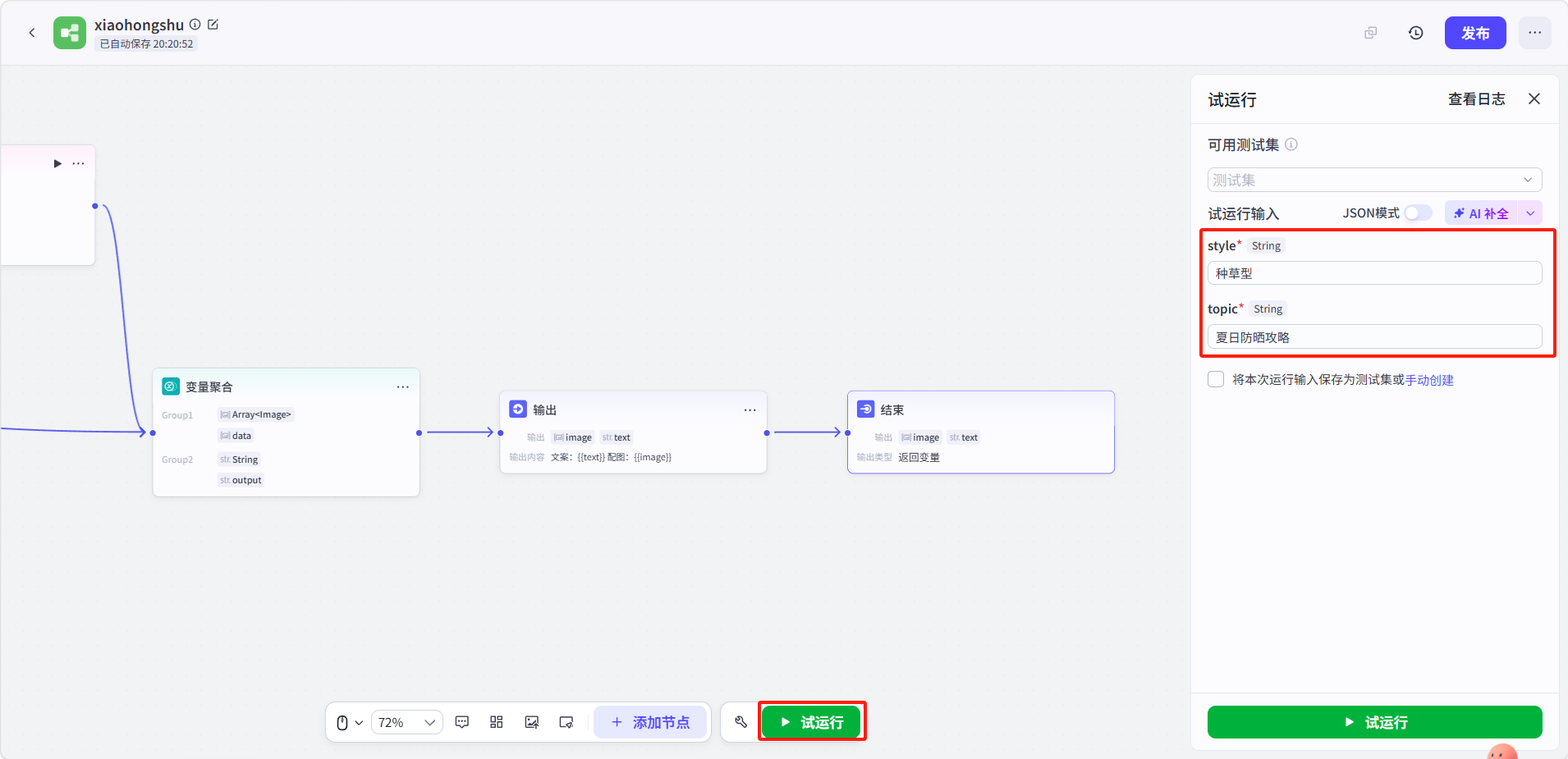
点击底部 「试运行」,输入:
-
style:
种草型 -
topic:
夏日防晒攻略
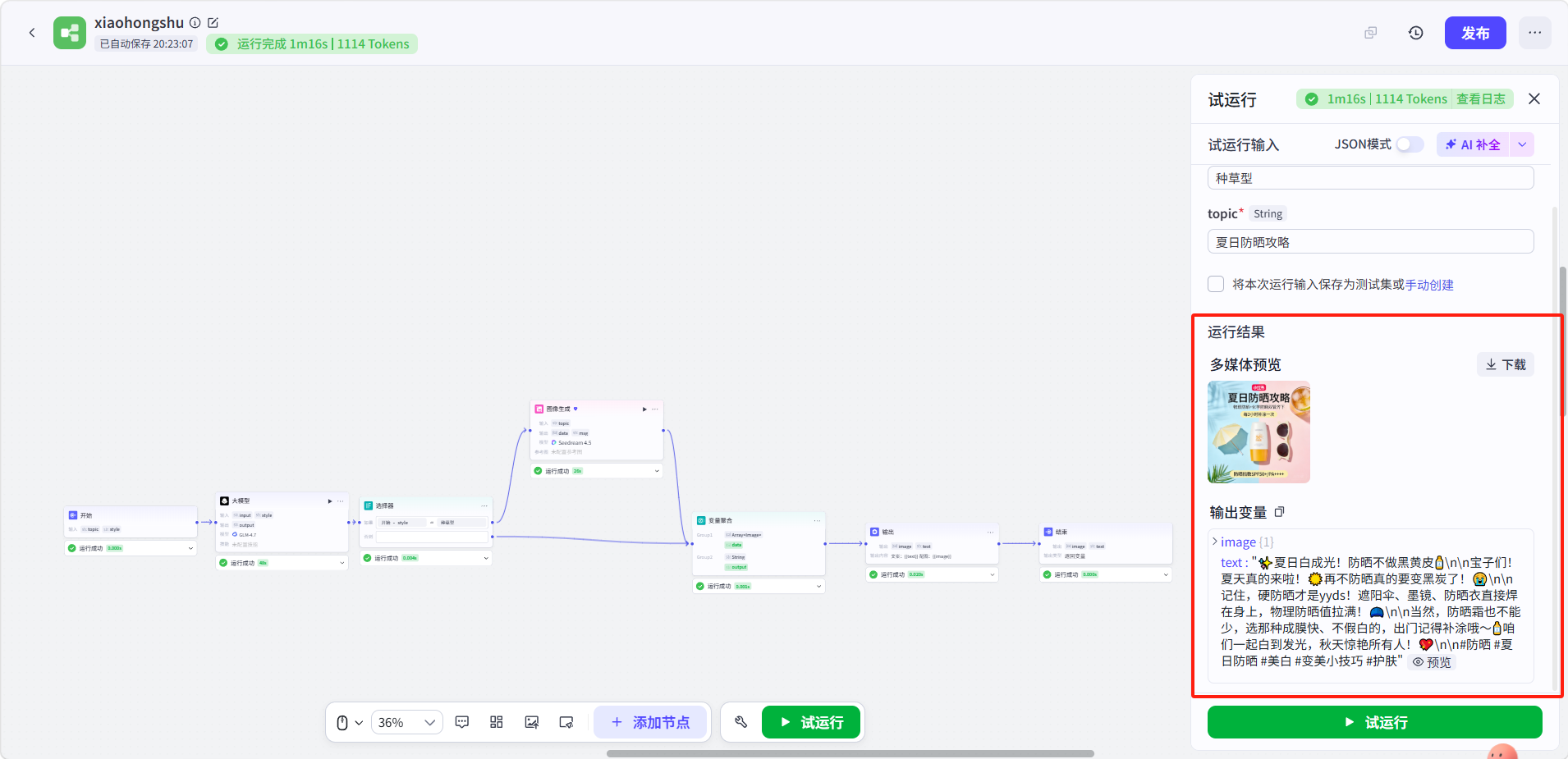
运行效果展示。
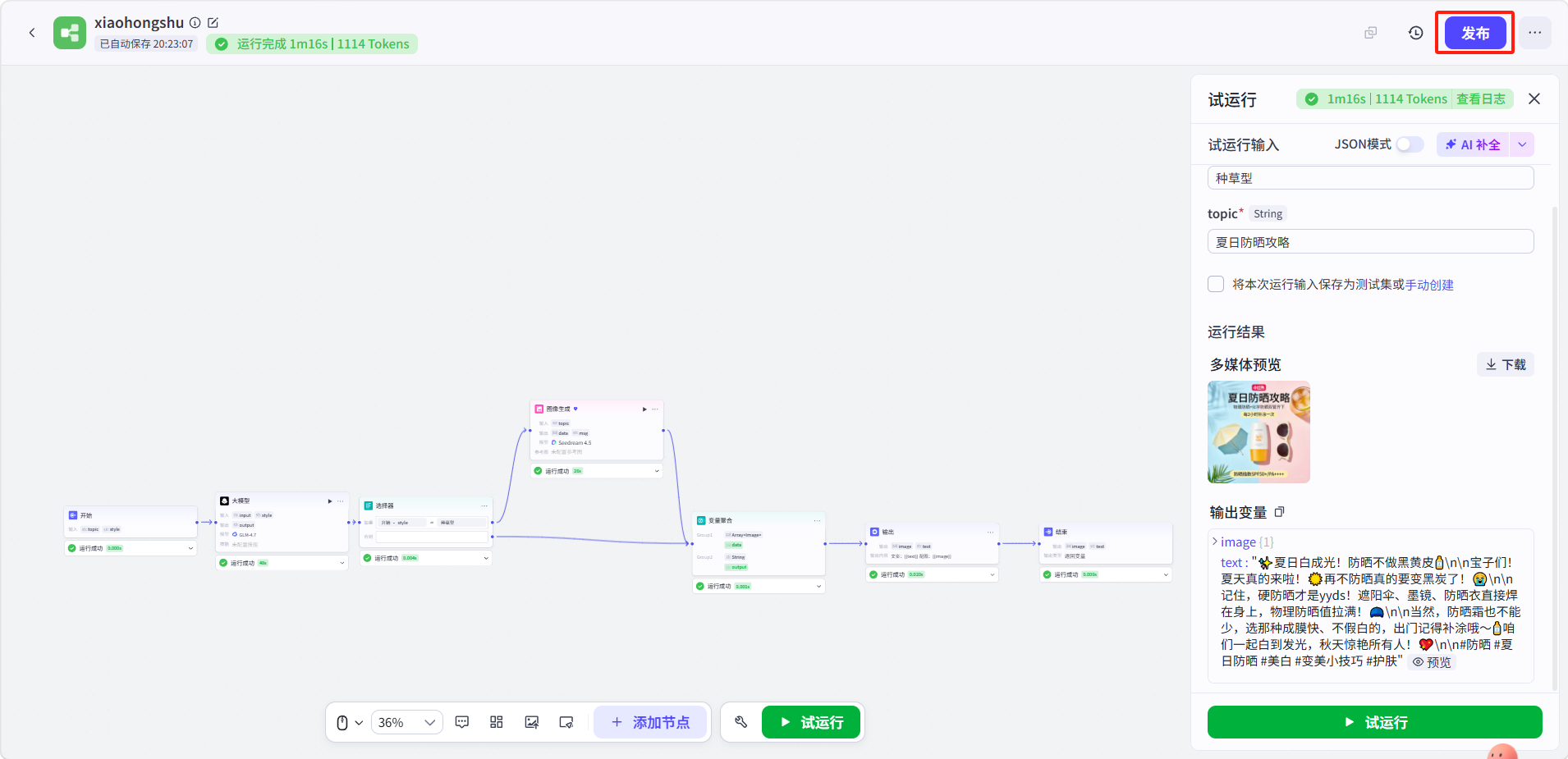
测试通过后,点击右上角「发布」即可。
可用节点类型
工作流支持丰富的节点类型,按功能分为以下几类:
工作流设计原则
- 模块化:将复杂流程拆分为独立的功能模块,每个模块用一个或一组节点实现
- 可测试:每添加一个节点后都进行试运行,确保该步骤的输出符合预期
- 错误处理:在关键节点后添加选择器节点,处理可能出现的异常情况
- 性能优化:避免不必要的大模型调用,对于固定逻辑优先使用代码节点
实战示例
示例一:小红书笔记自动生成器
示例二:智能客服工作流
示例三:销售数据分析工作流
示例四:多语言翻译工作流
示例五:内容审核工作流
评论
0 条